【Algs4】算法(1):Union-Find
原文链接
在计算机科学(Computer Science,CS)领域,算法(Algorithm)是描述一种有限、确定、有效,并且适合用计算机语言来实现的解决问题的方法,它是CS领域的基础与核心。
这里先通过一个动态连通性问题,来了解设计、分析算法的基本过程。
动态连通性
问题描述
动态连通性问题的描述如下:问题的输入是一系列的整数对,每个整数都能代表某种对象。当有输入一对整数p、q时,则说明p、q所代表的对象是“相连”的,这里假设“相连”是一种等价关系,且相连后有如下几个性质:
- 自反性:p和p是相连的,q和q是相连的
- 对称性:q与p也是相连的
- 传递性:如果q和r相连,则p和r也相连
其中一些相连的对象组成的集合称为连通分量(Connected Components),它相互连接的对象组成的最大集合,如下图所示的两个连通分量:
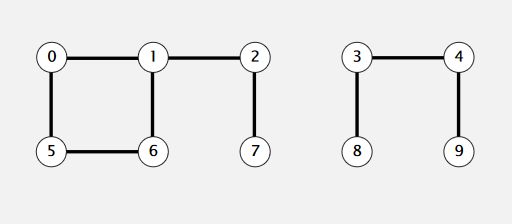
要求我们设计一个数据结构来保存所有输入的整数对之间的连通信息,基于它设计可以高效地连通两个对象、查询对象间的连通性的Union-Find算法。
该问题中的整数对可以代表现实生活中各种各样的对象,从而解决该问题的算法也有很广泛的应用。例如在计算机网络上,一个整数对可以代表两台计算机,该算法就可以用来判断计算机之间通信线路是否畅通;在社交网络上,一个整数对可以代表两个人,该算法就可以用来判断很多人之间的朋友关系。
根据问题的要求,为Union-Find算法设置如下几个API:
此外,可用以下程序来检查这些API的正确性:
public static void main(String[] args) {
int N = StdIn.readInt();
UF uf = new UF(N);
while (!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if (!uf.connected(p, q)) {
uf.union(p, q);
StdOut.println(p + " " + q);
}
}
}
Quick-Find算法
Quick-Find算法以数组id[]作为数据结构,一个对象对应数组中的一个索引。该算法的思想,是保证当且仅当id[p]等于id[q]时,索引p和q对应的对象才是连通的,也就是说,同一个连通分量中的所有对象在数组id[]中对应的值必须全部相同。如下图所示:
此时,要实现connected方法,只要由索引值p、q,判断id[p]和id[q]是否相等;find方法则只要返回某个对象在数组id[]中对应的值;而每次执行union方法时,都需要遍历整个数组id[],将已连通的分量全部赋上相同的值。
Quick-Find具体实现为:
public class QuickFindUF {
private int[] id;
public QuickFindUF(int N) {
id = new int[N];
for (int i = 0; i < N; i++) // 初始化数组
id[i] = i;
}
public boolean connected(int p, int q) {
return id[p] == id[q];
}
public int find(int p) {
return id[p];
}
public void union(int p, int q) {
int pid = find(p);
int qid = find(q);
if (pid == qid)
return;
for (int i = 0; i < id.length; i++) // 遍历整个数组
if (id[i] == pid)
id[i] = qid;
}
}
Quick-Find中,每执行一次find只访问了一次数组,而执行一次union需要访问 ( N + 3 ) (N+3) (N+3)到 ( 2 N + 1 ) (2N+1) (2N+1)次数组,对 N N N个对象至少需要调用 N − 1 N-1 N−1次union,总共至少需要访问 ( N + 3 ) ( N − 2 ) (N+3)(N-2) (N+3)(N−2)到 N 2 N^2 N2次数组。
由此可知,Quick-Find算法的执行过程是平方级别的,面对大量的输入时该算法无法高效进行处理。
Quick-Union算法
Quick-Union算法中,提高了Quick-Find中union方法的速度。还是以一个数组id[]作为数据结构,但这个数组有了新的含义:一个对象还是对应id[]的一个索引,而id[]中存储的值,代表的则是同一个连通分量中的另一个对象对应的索引值。在这里,id[]用父链接的形式代表了一片森林,且根节点及初始时各对象的链接都指向它本身。
如图所示,每个对象都有它的根结点及父结点,3的父节点是4,2、4的父节点是9,而2、3、4的根节点都是9,9的父节点和根节点则是它本身,这样就形成一颗树。
实现该算法,connected方法要做的,就是确定两个对象的根节点的值是否相同,find方法则确定对象的根节点,union方法将两个对象的根节点的值统一。
Quick-Union具体实现为:
private class QuickUnionUF {
private int[] id;
public QuickUnionUF(int N) {
id = new int[N];
for (int i = 0; i < N; i ++)
id[i] = i;
}
public int find(int p) {
while (p != id[p])
p = id[p]; // 循环,直到找出根节点
return p;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
id[pRoot] = qRoot;
}
}
对于Quick-Union算法,对 N N N个对象,union过程寻找根节点要访问 N N N次数组,find寻找根节点时也可能需要访问 N N N次数组。遇到大型的问题,Quick-Union在部分情况下比Quick-Find快了一些,但极端情况下,id[]中某棵树的高度不断增加,导致find的代价不断变大,这时该算法的性能比Quick-Find还糟糕。
加权Quick-Union算法
Quick-Union算法的缺点在于一棵树会不断增长,而使寻找某个对象的根节点的代价不断变大,最糟糕情况下可能要遍历整棵树才能找到某个对象的根节点。对此改进的方法之一,就是进行加权。
所谓加权,在原Quick-Union算法的基础上,跟踪每一棵树中对象的个数,确保总是将较小树的根结点作为较大树的子节点,避免将一棵大树连接在小树下面,从而有效缩短树的高度。
加权Quick-Union具体实现为:
public class WeightedQuickUnionUF {
private int[] id;
private int[] sz; // 各根结点对应的分量大小
public WeightedQuickUnionUF(int N) {
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
sz = new int[N];
for (int i = 0; i < N; i++)
sz[i] = 1;
}
public int find(int p) {
while (p != id[p])
p = id[p];
return p;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
if (sz[pRoot] < sz[qRoot]) {
id[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else {
id[qRoot] = pRoot;
sz[pRoot] = sz[qRoot];
}
}
}
加权Quick-Union算法中,当 N N N个对象连接在一棵树上,形成的树的最大高度为 lg N \lg\ N lg N。对N个输入对,union过程需要访问 lg N \lg\ N lg N次数组,find寻找根节点时最多也只需要访问 lg N \lg N lgN次数组。面对大量输入时,该算法的性能就比较能接受了,且该算法实现起来也相对容易。
这个算法还可以进一步改进:在加权Quick-Union的基础上再进行路径压缩(Path Compression)。理想情况下,希望每个对象节点都直接连接到根节点上,因此可以在找到某个对象的根节点后,将这个对象的节点直接连接在根节点上,这样整个树的路径就进行了极大的压缩。
实际上,为了只添加少量代码,我们只将每个节点链接到其祖父节点上,虽然这样并没有将树完全展平,但只用修改find方法中的一行代码,就将树基本展平,效果和完全展平相当。具体的修改如下:
public int find(int i) {
while(i != id[i]) {
id[i] = id[id[i]];
i = id[i];
}
return i;
}
总结比较一下在N个对象上进行M次Union-Find操作时,以上几种算法的性能:
最后,总结一下研究某个问题的算法时要遵循的基本步骤:
- 完整而详解地定义问题,找出解决问题必需的基本抽象操作,定义一份API;
- 简洁地实现一种初级算法,给出一个精心组织的开发用例并使用实际数据作为输入;
- 当算法可解决的问题的最大规模达不到预期时,决定改进还是放弃该算法;
- 逐步改进实现算法,并通过经验性分析或数学分析验证改进后的效果;
- 用更高层次的抽象表示数据结构或算法来设计更高级的改进版本;
- 尽量为最坏情况下的性能提供保证,且处理普通数据时也要有良好的性能。
算法分析
编写好的程序将会运行多长的时间,将会占用多大的内存,这都是经常需要考虑的问题。对此,需要采用一些科学的方法,对一个算法的性能好坏作出大致的分析预测,了解最坏情况下算法性能的下界,避免程序出现性能瓶颈。
《计算机程序设计艺术》的作者D.E.Knuth认为,尽管有许多复杂的因素影响着程序的运行时间,原则上还是可以构建出一个数学模型来描述任意程序的运行时间。他的基本见解是,一个程序运行的总时间主要与:
- 执行每条语句和耗时
- 执行每条语句的频率
这两点有关,前者取决于计算机、编译器和操作系统,后者就取决于我们所编写的程序的本身和输入。
程序中执行最频繁的指令,往往决定了程序执行的总时间。例如,对于下面一个用来统计文本文件中,所有和为0的三个整数的数量的3-SUM程序:
//3-SUM
public calss ThreeSUM {
public staic int count(int[] a) {
int N = a.length;
int count = 0;
for (int i = 0; i < N; i++)
for(int j = 0; j < N; j++)
for(int k = j+1; k < N; k++)
if(a[i] + a[j] + a[k] == 0)
count++;
return count;
}
public static void main(String[] args) {
int[] a = In.readInts(args[0]);
StdOut.println(count(a));
}
}
分析可知,对于大量的输入,3-SUM程序中执行次数最多的将是if语句,且执行次数为: g ( N ) = N ( N − 1 ) ( N − 2 ) 6 = N 3 6 − N 2 2 + N 3 g(N) = \frac{N(N-1)(N-2)}{6} = \frac{N^3}{6} - \frac{N^2}{2} + \frac{N}{3} g(N)=6N(N−1)(N−2)=6N3−2N2+3N。
表达式中,其他项都比首项小了很多,于是可以用 g ( N ) ∼ a f ( N ) g(N) \sim af(N) g(N)∼af(N)的近似方式,忽略较小的项以简化式子,并以此对程序的开销作大致衡量。其中 f ( N ) f(N) f(N)称为 g ( N ) g(N) g(N)的增长数量级, a a a则用来进一步修正偏差。上式中即有: g ( N ) ∼ N 3 6 g(N) \sim \frac{N^3}{6} g(N)∼6N3
对程序中执行最为频繁的语句,其执行次数 g ( N ) g(N) g(N)的增长数量级 f ( N ) f(N) f(N)可用来表示程序运行时间的增长数量级。对各种算法分析过程中,常遇到的增长阶数有下面几类:
对上面的3-SUM问题,使用二分查找来解决的话,能将其增长数量级从 N 3 N^3 N3降到 N 2 log N N^2 \log N N2logN。
除了对算法的增长阶数外,不用的输入也会使算法的性能发生剧烈的变化,所以在进行算法分析时,也得考虑一个算法运行时间的最好情况和最坏情况。最好情况是算法代价的下限,程序运行的时间总是大于等于它;最坏情况是算法代价的上界,程序运行的时间不会长于它,两种情况综合起来可以得到用以衡量一般情况下的算法的平均性能。
常用 Θ \Theta Θ、 O O O和 Ω \Omega Ω这几个大写符号来描述性能的界限:
- O O O用以描述算法性能的渐进上界,如 O ( N 2 ) O(N^2) O(N2)就表示N增长时,程序运行时间小于某个常数乘以 N 2 N^2 N2;
- Ω \Omega Ω用以描述最坏情况下的性能下限,如 Ω ( N 2 ) \Omega(N^2) Ω(N2)就表示N增长时,程序运行时间比某个常数乘以 N 2 N^2 N2大;
- Θ \Theta Θ用以表示增长阶数,如 Θ ( N 2 ) \Theta(N^2) Θ(N2)就是某个常数乘以 N 2 N^2 N2的简写。
编程作业:渗透问题
描述
给定一个由 N × N N \times N N×N个方格组成的方形水槽,其中每个方格是随机开启或关闭。相邻的开启方格可形成一条通路。如果存在一条从水槽顶端到底端的通路,则称该水槽是**渗透(Percolation)**的。
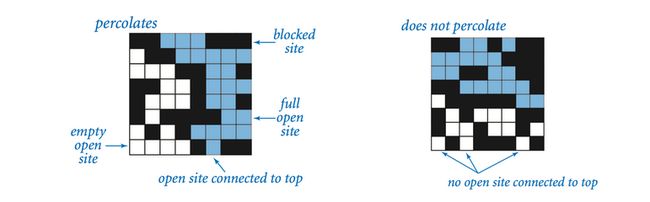
假设其中的各方格开启的概率为 p p p,渗透问题想要研究 p p p的大小与整个系统渗透的概率之间的关系。经过实验,当系统大小分别为 20 × 20 20\times20 20×20、 100 × 100 100\times100 100×100可以得到以下面的两个曲线:

要求编程建立一个模型,来验证当整个系统渗透时,方格的开启概率 p p p的取值区间。
[具体要求][提示]
分析
将此抽象为Union-Find问题,一个方格抽象为一个结点,并用使用二维数组进行索引,二维数组索引值从1开始。为了方便判断整个系统是否渗透,可以在顶部和底部分别添加一个虚节点,它们分别与顶层所有节点及底层所有结点相连接。这样只要判断顶部和底部的虚结点是否连通,即可知整个系统是否渗透。

测试时,需要注意一个看似渗透,实际上并未渗透的"backwash"问题:
解决这个问题的一个简单办法是维护两个数据结构,一个包含顶部及底部虚结点,另一个只包含顶部虚结点。
根据提示,抽象好整个系统后,可用蒙特卡洛(Monte Carlo)法进行分析:
- 初始化所有的格子为关闭状态,之后随机开启一些格子,直到系统渗透;
- 统计出开启的格子数,与全部格子数的比值即是作为 p p p值;
- 进行 T T T次实验,得到足够多的 p p p值后,算出所有p的平均值$\overline x 及 方 差 及方差 及方差s^2$
- 根据如下公式可以计算出置信度为 95 % 95\% 95%的的渗透阈值范围: [ x ‾ − 1.96 s T , x ‾ + 1.96 s T ] \left [ \; \overline x - \frac {1.96 s}{\sqrt{T}}, \;\; \overline x + \frac {1.96 s}{\sqrt{T}} \; \right] [x−T1.96s,x+T1.96s]
实现
见以下github链接,程序仅供参考:
- Percolation.java
- PercolationStats.java
参考资料
- Algorithms-Coursera
- 算法(第四版)
注:本文涉及的图片及资料均整理翻译自Robert Sedgewick的Algorithms课程以及配套书籍《算法(第四版)》,版权归其所有。翻译整理水平有限,如有不妥的地方欢迎指出。
更新历史:
- 2017.11.15 完成初稿
- 2018.02.16 内容更新
- 2019.01.03 部分修改