【Algs4】算法(2):栈和队列
原文链接
实际编程时,经常需要维护某个对象的集合,对集合中的对象的表示方式,往往决定着对它们进行各种操作时的效率。
这里介绍一些数据结构相关的基本概念以及两种最基本的数据结构–栈和队列。
数据结构
数据结构(data structure)是指相互之间存在着一种或多种关系的数据元素的集合,它包括数据的逻辑结构、存储结构及数据的运算这三方面的内容。
逻辑结构指的是数据元素之间的逻辑关系,它独立于计算机,与数据的存储无关。数据的逻辑结构可分为:
- 线性结构:结构中的数据元素间存在一一对应关系,典型的有线性表
- 非线性结构:结构中的数据元素间不存在或存在多种对应关系,典型的有集合、树、图
存储结构指的是数据结构在计算机中的表示方式,它依赖于计算机语言,包括数据元素的表示和关系的表示。数据的存储结构主要有:
- 顺序存储:逻辑上相邻的元素存储的物理位置也相邻,元素间的关系用存储单元的邻接关系来体现,可实现随机存取
- 链式存储:逻辑上相邻的元素存储的物理位置不一定相邻,而借助元素的存储地址的指针来表示元素间逻辑关系,只能顺序存取
- 索引存储:存储元素信息的同时,另建立索引表,索引表中存放一般形式为(关键字,地址)的索引项
- 散列存储:根据元素的关键字计算出其存储地址
数据的运算包括对运算的定义和实现,运算的定义是针对逻辑结构而指出运算的功能,实现则是针对存储结构指出运算的具体步骤。
栈
线性表(linear list)是由相同数据类型的多个数据元素组成的有限序列,可采用顺序或链式方式存储,且它的顺序存储又称为顺序表。
下压栈(stack,简称“栈”)是一种后进先出(Last In First Out,LIFO)的线性表,将某个对象添加到该数据结构的过程称为入栈(push),取出的过程则称为出栈(pop)。一个栈好比堆叠起来的一摞文件,将一份文件放在其最顶端的过程也就是所谓的入栈,出栈则是从最顶端取出一份文件的过程,如下图所示:
我们将栈的API设置如下:
实现
线性表可以用顺序或链式方式进行存储,先考虑用链表实现的一个下压堆栈,其示意图如下:
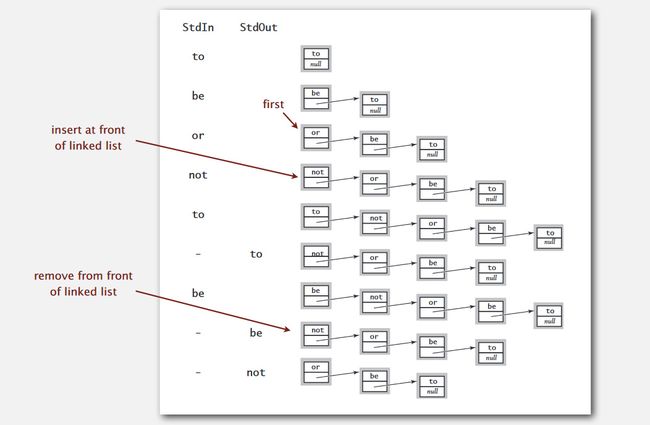
在Java中,我们构建一个内部类Node以实现单链表:
private class Node {
Item item;
Node next;
}
入栈对链表而言是表头插入新节点,出栈的则是在表头删除结点,采用链表实现一个泛型可迭代的下压堆栈的具体程序如下:
public class Stack<Item> implements Iterable<Item> {
private Node first; // 栈顶
private int n; // 元素数量
private class Node {
Item item;
Node next;
}
public Stack() {
first = null;
n = 0
}
public boolean isEmpty() {
return first == null;
}
public int size() {
return n;
}
public void push(Item item) {
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
n++;
}
public Item pop() {
Item item = first.item;
first = first.next;
n--;
return item;
}
public Iterator<Item> iterator() {
return new ListIterator();
}
private class ListIterator implements Iterator<Item> {
private Node current = first;
public boolean hasNext() {
return current != null;
}
public Item next() {
Item item = current.item;
current = current.next;
return item;
}
}
}
为了储存多种类型的数据,以上代码中用到了Java中的泛型(genericity)机制,将数据类型参数化。此外,为使用Java中的foreach语句迭代遍历集合中的所有元素,代码中将Stack类继承(implements)了一个Java库的迭代器Iterator接口(interface),并重写(override)了其中抽象方法(abstract function)。
对以上实现的堆栈,其中没有任何循环过程,因而每一种操作即使在极端情况下也能保持常数级别的运行时间。
使用数组实现下压堆栈时,需注意Java不允许泛型数组,要用以下方式进行转换:
a = (Item[]) new Object[cap];
此外还需要根据元素的数量及时调整数组的大小以防止出现溢出(overflow)。用数组实现堆栈的完整过程如下:
public class ResizingArrayStack<Item> extends Iterable<Item> {
private Item[] a = (Item[]) new Object[1]; // 数组
private int n = 0; // 元素数量
private void resize(int max) { // 调整数组大小
Item[] temp = (Item[]) new Object[max];
for (int i = 0; i < n; i++)
temp[i] = a[i];
a = temp;
}
public boolean isEmpty() {
return n == 0;
}
public int size() {
return n;
}
public void push(Item item) {
if (n == a.length)
resize(2 * a.length);
a[N++] = item;
}
public Item pop() {
Item item = a[--n];
a[n] = null;
if (n > 0 && n == a.length/4)
resize(a.length/2);
return item;
}
public Iterator<Item> iterator() {
return new ReverseArrayIterator();
}
private class ReverseArrayIterator() implements Iterator<Item> {
private int i = n;
public boolean hasNext() {
return i > 0;
}
public String next() {
return a[--i];
}
public void remove() {
}
}
}
其中自动调整数组大小的方式为:元素入栈时,检测到当前数组已满,则建立一个与当前数组大小翻倍的新数组,之后将所有原数组中的所有元素复制过去;而出栈时,在数组只剩 1 / 4 1/4 1/4满时则将数组的大小减半。平均下来,这样做的时间成本约为 3 N 3N 3N,比每次出入栈都去调整数组大小下的 N 2 N^2 N2要好很多,如下图所示:

用链表实现栈时:
- 在极端情况下,每次操作也能保持常数级别的时间复杂度
- 需要用到额外的时间、空间来处理指针
而对数组实现的栈:
- 平均下来每次操作将是常数级别的时间复杂度
- 不浪费空间
因此需根据实际需求,在两种实现方式间做出选择。
应用
上世纪60年代E.W.Dijkstra发明了一种使用两个栈对算术表达式求值的算法,用Java实现的具体过程如下:
public class Evaluate {
public static void main(String[] args) {
Stack<String> ops = new Stack<String>(); // 存放字符
Stack<Double> vals = new Stack<Double>(); // 存放数字
while (!StdIn.isEmpty()) {
String s = StdIn.toString();
if (s.equals("(")) ;
else if (s.euqals("+")) ops.push(s);
else if (s.euqals("-")) ops.push(s);
else if (s.euqals("*")) ops.push(s);
else if (s.euqals("/")) ops.push(s);
else if (s.euqals("sqrt")) ops.push(s);
else if (s.euqals(")")) {
String op = ops.pop();
double v = vals.pop();
if (op.equals("+")) v = vals.pop() + v;
else if (op.equals("-")) v = vals.pop() - v;
else if (op.equals("*")) v = vals.pop() * v;
else if (op.equals("/")) v = vals.pop() / v;
else if (op.equals("sqrt")) v = Math.sqrt(v);
vals.push(v);
}
else vals.push(Double.parseDouble(s));
}
StdOut.println(vals.pop());
}
}
这样一种算法,可以用来对带括号的式子进行一些基本的四则运算。
队列
队列(queue)是一种先进先出(First In First Out,FIFO)形式的线性表,向其中添加元素的过程称为入列(enqueue),删除元素的过程则称为出列(dequeue)。我们日常生活经常遇到的排队等待各种服务的过程,就相对于一个队列的入列、出列过程。
我们将队列包含的API设置如下:
实现
与栈类似,队列也可以用链表或数组实现。
用链表实现的一个队列如下图所示:
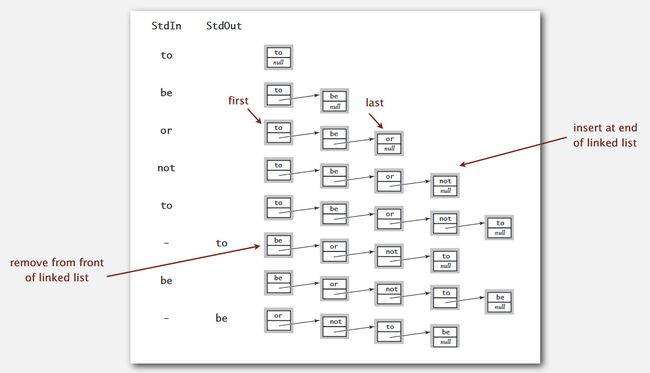
入队对链表而言,要从表位插入新节点,并将插入的新节点的指针设置为null,出队则和出栈的操作类似,还是从表头删除结点,具体实现过程为:
public class Queue<Item> implements Iterable<Item> {
private Node first; // 指向最早添加的结点
private Node last; // 指向最近添加的结点
private int n; // 元素数量
private class Node {
Item item;
Node next;
}
public Queue() {
first = null;
last = null;
n = 0;
}
public boolean isEmpty() {
return first == null;
}
public int size() {
return n;
}
public void enqueue(Item item) {
Node oldlast = last;
last = new Node();
last.item = item;
last.next = null;
if (isEmpty())
first = last;
else
oldlast.next = last;
n++;
}
public Item dequeue() {
Item item = first.item;
first = first.next;
if (isEmpty())
last = null;
n--;
return item;
}
public Iterator<Item> iterator() {
return new ListIterator();
}
private class ListIterator implements Iterator<Item> {
private Node current = first;
public boolean hasNext() {
return current != null;
}
public Item next() {
Item item = current.item;
current = current.next;
return item;
}
}
}
编程作业:双端、随机队列
描述
要实现一个双端队列和一个随机队列,双端队列能够从队头或队尾入队或出队,随机队列则随机选择一个其中的元素出队。
[具体要求][提示]
分析
根据两种队列的特点,考虑用双向链表来构建双端队列,随机队列则直接用数组进行实现。
实现
(仅供参考)
- Deque.java
- RandomizedQueue.java
- Permutation.java
参考资料
- Algorithms-Coursera
- 算法(第四版)
注:本文涉及的图片及资料均整理翻译自Robert Sedgewick的Algorithms课程以及配套教材《算法(第四版)》,版权归其所有。翻译整理水平有限,如有不妥的地方欢迎指出。
更新历史:
- 2019.03.22 完成初稿