用TensorFlow实现AlexNet,并完成Kaggle上的Dogs Vs Cats竞赛
原文链接
总体架构
AlexNet的总体架构如下所示:

-
整个网络总共有八层,其中前五层为卷积层,后面三层为全连接层;
-
用了两个GPU(GTX 580,3G内存)进行训练,因此整个架构被平均分成了两部分,除了第二层与第三层是跨GPU进行连接,其他卷积层都只和各自的GPU内的前一层进行连接;
-
在第一、二个卷积层后进行现在并不常用的局部响应归一化(local response normalization,LRN),LRN的公式如下:
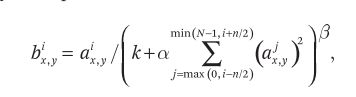
公式中的 k k k、 n n n、 α \alpha α、 β \beta β均为超参数,在验证集上实验得到 k = 2 k = 2 k=2、 n = 5 n = 5 n=5、 α = 0.00001 \alpha = 0.00001 α=0.00001、 β = 0.75 \beta = 0.75 β=0.75;
-
在LRN、第五层后面进行窗口大小和步幅不相等的最大池化,称为最大重叠池化;
-
批量大小为 128 128 128,并使用ReLU作为激活函数,
-
用数据扩充和DropOut法来防止过拟合。
各层中的具体过程为:

- 输入的大小原为 224 × 224 × 3 224 \times 224 \times 3 224×224×3,为方便后续处理将其调整为 227 × 227 × 3 227 \times 227 \times 3 227×227×3;
- 第一层用 96 96 96个大小为 11 × 11 11 \times 11 11×11的卷积核进行步幅为 4 4 4的卷积,之后用大小为 3 × 3 3\times3 3×3的窗口进行步幅为 2 2 2的最大重叠池化后,再进行尺度为 5 × 5 5\times5 5×5的LRN;
- 第二层用 256 256 256个大小为 5 × 5 5 \times 5 5×5的卷积核进行步幅为 1 1 1的卷积,之后和前一层一样进行重叠池化和LRN;
- 第三层用 384 384 384个大小为 3 × 3 3 \times 3 3×3的卷积核连接到第二层的所有输出;
- 第四、第五层分别用 384 384 384、 256 256 256个大小为 3 × 3 3 \times 3 3×3的卷积核进行步幅为 1 1 1的卷积,且在第五层后用大小为 3 × 3 3\times3 3×3的窗口进行步幅为 2 2 2的最大重叠池化。
- 第六层的输入大小为 6 × 6 × 256 6 \times 6 \times 256 6×6×256,与 4096 4096 4096个大小为 6 × 6 × 256 6 \times 6 \times 256 6×6×256的卷积核进行卷积,就得到包含 4096 4096 4096个节点的全连接层。训练时,需要在该全连接层进行一次drop_prob为 0.5 0.5 0.5的Dropout。
- 第七层的 4096 4096 4096个节点与上一个全连接层进行全连接,训练时,也需要在该全连接层进行一次drop_prob为 0.5 0.5 0.5的Dropout。
- 第八层进行第三次全连接,并输出最后的结果。
TensorFlow实现
辅助方法
卷积:
def conv(x, filter_height, filter_width, filters_num, stride_x, stride_y, name, padding='SAME', groups=1): # groups: 分成多个部分
input_channels = int(x.get_shape()[-1]) # 输入通道数
convolve = lambda i, k: tf.nn.conv2d(i, k, strides=[1, stride_x, stride_y, 1], padding=padding) # 卷积
with tf.variable_scope(name) as scope:
weights = tf.get_variable('weights', shape=[filter_height, filter_width, input_channels/groups, filters_num])
bias = tf.get_variable('bias', shape=[filters_num])
if groups == 1:
conv = convolve(x, weights)
else:
input_groups = tf.split(value=x, num_or_size_splits=groups, axis=3) # 切分
weight_groups = tf.split(value=weights, num_or_size_splits=groups, axis=3)
output_groups = [convolve(i, k) for i, k in zip(input_groups, weight_groups)] # 分别卷积
conv = tf.concat(values=output_groups, axis=3) # 拼接
z = tf.reshape(tf.nn.bias_add(conv, bias), conv.get_shape().as_list())
relu = tf.nn.relu(z, name=scope.name)
return relu
池化、LRN、Dropout:
def max_pool(x, filter_height, filter_width, stride_x, stride_y, name, padding='SAME'):
return tf.nn.max_pool(x, [1, filter_height, filter_width, 1], strides=[1, stride_x, stride_y, 1], padding=padding, name=name)
# 局部响应归一化
def lrn(x, radius, alpha, beta, name, bias=1.0):
return tf.nn.lrn(x, depth_radius=radius, alpha=alpha, beta=beta, bias=bias, name=name) # bias对应k, radius对应n/2
# 全连接
def fc(x, num_in, num_out, name, relu=True):
with tf.variable_scope(name) as scope:
weights = tf.get_variable('weights', shape=[num_in, num_out])
bias = tf.get_variable('bias', shape=[num_out])
z = tf.nn.xw_plus_b(x, weights, bias, name=scope.name)
if relu == True:
act = tf.nn.relu(z)
else:
act = z
return act
# Dropout
def dropout(x, keep_prob):
return tf.nn.dropout(x, keep_prob)
用动态图测试上面的各方法:
import tensorflow.contrib.eager as tfe
tfe.enable_eager_execution()
x = tf.truncated_normal(shape=[1, 227, 227, 3], seed = 1)
cnv = conv(x, 11, 11, 96, 4, 4, padding='VALID', name='conv')
pool = max_pool(cnv, 3, 3, 2, 2, padding='VALID', name='pool')
norm = lrn(pool, 2, 2e-05, 0.75, name='norm')
norm.get_shape()
整个模型
建立整个AlenNet:
class AlexNetModel(object):
def __init__(self, num_classes=1000, keep_prob=0.5, skip_layer=[], weights_path='DEFAULT'):
self.num_classes = num_classes
self.keep_prob = keep_prob
self.skip_layer = skip_layer
if weights_path == 'DEFAULT':
self.weights_path = 'bvlc_alexnet.npy'
else:
self.weights_path = weights_path
def inference(self, x, training=False): # 模型
# conv1: CONV --> POOL --> LRN
conv1 = conv(x, 11, 11, 96, 4, 4, padding='VALID', name='conv1')
pool1 = max_pool(conv1, 3, 3, 2, 2, padding='VALID', name='pool1')
norm1 = lrn(pool1, 2, 2e-05, 0.75, name='norm1')
# conv2: CONV --> POOL --> LRN with 2 Groups
conv2 = conv(norm1, 5, 5, 256, 1, 1, groups=2, name='conv2')
pool2 = max_pool(conv2, 3, 3, 2, 2, padding='VALID', name='pool2')
norm2 = lrn(pool2, 2, 2e-05, 0.75, name='norm2')
# conv3: CONV
conv3 = conv(norm2, 3, 3, 384, 1, 1, name='conv3')
# conv4: CONV with 2 Groups
conv4 = conv(conv3, 3, 3, 384, 1, 1, groups=2, name='conv4')
# conv5: CONV --> PooL with 2 Groups
conv5 = conv(conv4, 3, 3, 256, 1, 1, groups=2, name='conv5')
pool5 = max_pool(conv5, 3, 3, 2, 2, padding='VALID', name='pool5')
# fc6: Flatten --> FC --> Dropout
flattened = tf.reshape(pool5, [-1, 6*6*256])
fc6 = fc(flattened, 6*6*256, 4096, name='fc6')
if training:
fc6 = dropout(fc6, self.keep_prob)
# fc7: FC --> Dropout
fc7 = fc(fc6, 4096, 4096, name='fc7')
if training:
fc7 = dropout(fc7, self.keep_prob)
# fc8: FC
self.score = fc(fc7, 4096, self.num_classes, relu=False, name='fc8')
return self.score
def loss(self, batch_x, batch_y): # 损失
y_predict = self.inference(batch_x, training=True)
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=y_predict, labels=batch_y))
return self.loss
def optimize(self, learning_rate, train_layers=[]): # 优化
var_list = [v for v in tf.trainable_variables() if v.name.split('/')[0] in train_layers]
return tf.train.AdamOptimizer(learing_rate).minimize(self.loss, var_list=var_list)
def load_original_weights(self, session): # 导入训练好的权重
weights_dict = np.load(self.weights_path, encoding='bytes').item()
for op_name in weights_dict:
if op_name not in self.skip_layer:
with tf.variable_scope(op_name, reuse=True):
for data in weights_dict[op_name]:
if len(data.shape) == 1:
var = tf.get_variable('bias')
session.run(var.assign(data))
else:
var = tf.get_variable('weights')
session.run(var.assign(data))
模型测试
用原始的参数值来测试构建好的AlexNet模型,原始参数的文件可从这里下载。
import matplotlib.pyplot as plt
from caffe_classes import class_names
import cv2
import os
img_dir = os.path.join(os.getcwd(), 'images')
img_file = [os.path.join(img_dir, f) for f in os.listdir(img_dir) if f.endswith('.jpeg')]
imgs = []
for f in img_file:
imgs.append(cv2.imread(f))
imagenet_mean = np.array([104., 117., 124.], dtype=np.float32) # ImageNet中的图片像素均值
x = tf.placeholder(tf.float32, [1, 227, 227, 3])
model = AlexNetModel()
score = model.inference(x)
softmax = tf.nn.softmax(score)
writer = tf.summary.FileWriter('./graph/alexnet', tf.get_default_graph())
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
model.load_original_weights(sess)
fig2 = plt.figure(figsize=(15, 6))
for i, image in enumerate(imgs):
img = cv2.resize(image.astype(np.float32), (227, 227))
img -= imagenet_mean
img = img.reshape((1, 227, 227, 3))
probs = sess.run(softmax, feed_dict={x: img})
class_name = class_names[np.argmax(probs)]
writer.close()
fig2.add_subplot(1,3,i+1)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title("Class: " + class_name + ", probability: %.4f" %probs[0,np.argmax(probs)])
plt.axis('off')
得到预测结果:

Dogs VS Cats
下载Kaggle上的Dogs vs. Cats Redux Competetion的数据集,考虑微调上面构建好的AlexNet来完成该竞赛。
解压其中的压缩包后,可以看到其中包含 25000 25000 25000张带标签的训练数据:

和 15000 15000 15000张不带标签的测试数据:
数据处理
首先将数据集划分一下,这里把 85 % 85\% 85%的训练数据也就是 21250 21250 21250张图片作为训练集,剩下的 4750 4750 4750张图片作为验证集。
竞赛中要求将猫图的标签设为 0 0 0,狗图的标签设为 1 1 1。要使用这些数据来训练我们的模型,为了方便读取,可考虑获取所有的图片的路径和对应的标签,把它们统一放在一个txt文件中。实现该过程的程序如下:
import os
train_sets_dir = os.path.join(os.getcwd(), 'train')
train_images_file = os.listdir(train_sets_dir)
train_sets_list = []
for fn in train_images_file:
file_label = fn.split('.')[0]
if file_label == 'cat':
label = '0'
else:
label = '1'
path_and_label = os.path.join(train_sets_dir, fn) + ' ' + label + '\n'
train_sets_list.append(path_and_label)
validate_sets_list = train_sets_list[int(len(train_sets_list)*0.85):] # 15%作为验证集
train_sets_list = train_sets_list[:int(len(train_sets_list)*0.85)]
train_text = open('train.txt', 'w') # 写入txt文件
for img in train_sets_list:
train_text.writelines(img)
validate_text = open('validate.txt', 'w') # 写入txt文件
for img in validate_sets_list:
validate_text.writelines(img)
这样就能得到名为train.txt、validate.txt的两个文件,文件的内容如下:

前面是图片的数据路径,后面则是该图片对应的标签。
导入数据
用下面的辅助方法来调用tf.data.Dataset导入数据,并对数据进行一些简单的处理:
# 数据处理
IMAGENET_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32) # 用于放缩范围
def parse_image(filename, label):
img_string = tf.read_file(filename) # 读取
img_decoded = tf.image.decode_png(img_string, channels=3) # 编码
img_resized = tf.image.resize_images(img_decoded, [227, 227]) # 裁剪
img_converted = tf.cast(img_resized, tf.float32) # 数据格式
img_centered = tf.subtract(img_resized, IMAGENET_MEAN) # 放缩范围
return img_centered, label
def data_generate(txt_file, batch_size, num_classes, shuffle=True):
paths_and_labels = np.loadtxt(txt_file, dtype=str).tolist() # 读取文件,组成列表
if shuffle:
np.random.shuffle(paths_and_labels) # 打乱
paths, labels = zip(*[(l[0], int(l[1])) for l in paths_and_labels]) # 将paths和labels分开
steps_per_epoch = np.ceil(len(labels)/batch_size).astype(np.int32)
paths = tf.convert_to_tensor(paths, dtype=tf.string) # 转换为tensor
labels = tf.one_hot(labels, num_classes)
labels = tf.convert_to_tensor(labels, dtype=tf.float32)
dataset = tf.data.Dataset.from_tensor_slices((paths, labels)) # 创建数据集
dataset = dataset.map(parse_image) # 调函数进行预处理
if shuffle:
dataset = dataset.shuffle(buffer_size=batch_size)
dataset = dataset.batch(batch_size) # 小批量
return dataset, steps_per_epoch
微调AlexNet,其中的卷积层仍采用原始参数,而使用现有的数据集来训练其中的全连接层。因此调用上面的方法导入数据,设置并初始化迭代器,并设置一些超参数如下:
train_file = 'train.txt'
validate_file = 'validate.txt'
learning_rate = 0.01 # 超参数
num_epochs = 10
batch_size = 256
num_classes = 2
train_layers = ['fc8', 'fc7', 'fc6']
train_data, train_steps = data_generate(train_file, batch_size=batch_size, num_classes=num_classes)
validate_data, validate_steps = data_generate(validate_file, batch_size=batch_size, num_classes=num_classes)
iterator = tf.data.Iterator.from_structure(train_data.output_types, train_data.output_shapes) # 迭代器
train_init = iterator.make_initializer(train_data)
validate_init = iterator.make_initializer(validate_data)
imgs, labels = iterator.get_next()
建立并训练模型
建立AlexNet模型:
model = AlexNetModel(num_classes=num_classes, skip_layer=train_layers)
loss = model.loss(imgs, labels) # 损失
optimizer = model.optimize(learning_rate=learning_rate)
correct_pred = tf.equal(tf.argmax(model.score, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_sum(tf.cast(correct_pred, tf.float32)) # 识别正确的总个数
训练并保存模型:
from datetime import datetime
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
writer.add_graph(sess.graph)
model.load_original_weights(sess)
print("{} Start training...".format(datetime.now()))
for epoch in range(num_epochs): # 开始训练
sess.run(train_init) # 训练数据初始化
total_loss = 0
n_batches = 0
total_acc = 0
try:
while True:
_, l, ac = sess.run([optimizer, loss, accuracy])
total_loss += l
total_acc += ac
n_batches += 1
except tf.errors.OutOfRangeError:
pass
print('Average loss epoch {0}: {1}'.format(epoch, total_loss/n_batches)) # 平均损失
print("{} Training Accuracy = {:.4f}".format(datetime.now(), total_acc/21250.0) # 训练集准确率
print("{} Start validation".format(datetime.now()))
sess.run(validate_init) # 初始化验证集
total_correct_preds = 0
try:
while True:
accuracy_batch = sess.run(accuracy)
total_correct_preds += accuracy_batch
except tf.errors.OutOfRangeError:
pass
print("{} Validation Accuracy = {:.4f}".format(datetime.now(), total_correct_preds/4750.0)) # 验证集准确率
print("{} Saving checkpoint of model...".format(datetime.now()))
model_name = os.path.join(os.getcwd() + '/model', 'model_epoch'+str(epoch+1)+'.ckpt')
save_path = saver.save(sess, model_name) # 保存模型
print("{} Model checkpoint saved at {}".format(datetime.now(), model_name))
使用前面设置的超参数,本人的Colab上训练的结果如下:

精确度还不够高,可以尝试继续调整超参数。
测试模型
在测试集上测试训练好的模型:
import os
import pandas as pd
import tensorflow as tf
test_sets_dir = os.path.join(os.getcwd(), 'test')
test_images_file = os.listdir(test_sets_dir)
test_images_file.sort(key=lambda x:int(x[:-4]))
test_sets_list = []
for fn in test_images_file:
path = os.path.join(test_sets_dir, fn) + '\n'
test_sets_list.append(path)
test_text = open('test.txt', 'w') # 写入txt文件
for img in test_sets_list:
test_text.writelines(img)
IMAGENET_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32) # 用于放缩范围
def parse_test_image(filename):
img_string = tf.read_file(filename)
img_decoded = tf.image.decode_png(img_string, channels=3)
img_resized = tf.image.resize_images(img_decoded, [227, 227])
img_converted = tf.cast(img_resized, tf.float32)
img_centered = tf.subtract(img_resized, IMAGENET_MEAN)
return img_centered
images_path = np.loadtxt('./test.txt', dtype=str).tolist()
images_path = tf.convert_to_tensor(images_path, dtype=tf.string)
test_dataset = tf.data.Dataset.from_tensor_slices((images_path))
test_dataset = test_dataset.map(parse_test_image)
test_dataset = test_dataset.batch(1000)
test_iterator = test_dataset.make_one_shot_iterator()
test_image = test_iterator.get_next()
model = AlexNetModel(num_classes=2)
score = model.inference(test_image)
predicts = []
saver=tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, './model/model_epoch10.ckpt')
try:
while True:
scores = sess.run(score)
predicts.extend(tf.argmax(scores, 1).eval())
except tf.errors.OutOfRangeError:
pass
# 生成测试结果并写入cvs文件中
results = pd.Series(predicts, name="label")
submission = pd.concat([pd.Series(range(1,12501),name = "id"), results],axis = 1)
submission.to_csv("sample_submission.csv",index=False)
上传到kaggle上得到的成绩:

参考资料
- ImageNet classification with deep convolutional neural networks
- Finetuning AlexNet with TensorFlow
- AlexNet详细解读-CSDN
- finetune_alexnet_with_tensorflow-Github
- tensorflow-cnn-finetune-Github