深度之眼Pytorch打卡(六):将数据集切分成训练集、验证集和测试集的方法
前言
深度学习说到底是由数据驱动的,所以数据是非常重要的。我们在网上收集的数据,常常是没有分成训练集,验证集和测试的,需要我们自己进行分割。本笔记的代码参照了深度之眼老师提供的参考代码,并作了一些相关的拓展。
代码和数据集:dataSplit.zip
任务
在网上收集不同类别的数据,笔者收集了两个类别的数据,ants和bees各100张,放在old_data下的两个文件夹内。拆分数据集为训练集,验证集和测试集。
数据集拆分
拆分数据集,即要随机分配数据到训练集,验证集和测试集。可以有两种方式,第一种是直接拆分数据,即直接在物理地址上切分;第二种是分别生成训练集、验证集和测试集的路径列表文件,然后在读取过程中切分。
- 要用到的函数简析
os.listdir(): 获取给定路径下的文件和文件夹列表,不能得到下一级目录的文件和文件夹列表。如:
print(os.listdir(old_path))
# output
# ['ants', 'bees']
os.walk(): 该方法有4个参数,我们就用一个就可以,即top,是要遍历的路径。该方法可以遍历完给定路径下的所有文件信息,为定路径下的每一个目录(包括自身)返回的一个三元组,即(root, dirs , files)。root指当前遍历文件夹的的地址,dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录),files 同样是 list , 内容是该文件夹中所有的文件。如:
root_dir, sub_dirs, sub_sub_dirs = os.walk(old_path)
print(root_dir, '\n', sub_dirs, '\n', sub_dirs1)
# output
# ('old_data', ['ants', 'bees'], [])
# ('old_data\\ants', [], ['1030023514_aad5c608f9.jpg', '1095476100_3906d8afde.jpg', .....])
# ('old_data\\bees', [], ['1092977343_cb42b38d62.jpg', '1093831624_fb5fbe2308.jpg', .....]
for root_dir, sub_dirs, files in os.walk(old_path): # 遍历os.walk()返回的每一个三元组,内容分别放在三个变量中
print('root_dir:', root_dir, 'sub_dirs:', sub_dirs, 'file:', files)
# output
# root_dir: old_data sub_dirs: ['ants', 'bees'] file: []
# root_dir: old_data\ants sub_dirs: [] file: ['1030023514_aad5c608f9.jpg', .....]
# root_dir: old_data\bees sub_dirs: [] file: ['1092977343_cb42b38d62.jpg', .....]
os.path.join(): 把字符拼接成目录。
shuffle() : 将序列的所有元素随机排序
filter():filter(function, iterable),用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。该函数接收两个参数,第一个为判断函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。如下表示去掉img_names列表中非.jpg文件,并将结果转换成列表。
list(filter(lambda x: x.endswith('.jpg'), img_names))
- 第一种:直接切分数据
要用到shutil包来复制数据。思路就是遍历目录下的所有文件,得到所有类别的存放路径。遍历每个类别,然后获得每个类别的所有图片的名称列表,并将其随机排列。然后创建存放对应数据集的文件夹,并遍历图片名称列表,按照比例(8:1:1)将名字分配给不同的集。最后拼接路径,根据路径复制图片到对应位置。代码如下:
import os
import random
import math
import shutil
def data_split(old_path):
new_path = 'data'
if os.path.exists('data') == 0:
os.makedirs(new_path)
for root_dir, sub_dirs, file in os.walk(old_path): # 遍历os.walk()返回的每一个三元组,内容分别放在三个变量中
for sub_dir in sub_dirs:
file_names = os.listdir(os.path.join(root_dir, sub_dir)) # 遍历每个次级目录
file_names = list(filter(lambda x: x.endswith('.jpg'), file_names)) # 去掉列表中的非jpg格式的文件
random.shuffle(file_names)
for i in range(len(file_names)):
if i < math.floor(0.8*len(file_names)):
sub_path = os.path.join(new_path, 'train_set', sub_dir)
elif i < math.floor(0.9*len(file_names)):
sub_path = os.path.join(new_path, 'val_set', sub_dir)
elif i < len(file_names):
sub_path = os.path.join(new_path, 'test_set', sub_dir)
if os.path.exists(sub_path) == 0:
os.makedirs(sub_path)
shutil.copy(os.path.join(root_dir, sub_dir, file_names[i]), os.path.join(sub_path, file_names[i])) # 复制图片,从源到目的地
if __name__ == '__main__':
data_path = 'old_data'
data_split(data_path)
结果:
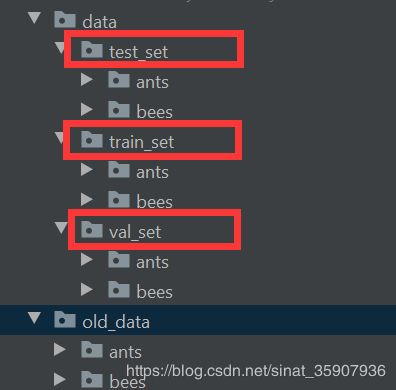
第二种:生成路径列表
代码与上述方法类似,此方法只是将路径,分别储存到三个不同的文本文件中。这种方法可以直接生成路径列表,在加载数据时不用重新生成,使得数据读取过程简化了。代码如下:
def data_list(path):
for root_dir, sub_dirs, _ in os.walk(path): # 遍历os.walk()返回的每一个三元组,内容分别放在三个变量中
idx = 0
for sub_dir in sub_dirs:
file_names = os.listdir(os.path.join(root_dir, sub_dir)) # 遍历每个次级目录
file_names = list(filter(lambda x: x.endswith('.jpg'), file_names)) # 去掉列表中的非jpg格式的文件
random.shuffle(file_names)
for i in range(len(file_names)):
if i < math.floor(0.8 * len(file_names)):
txt_name = 'train_set.txt'
elif i < math.floor(0.9 * len(file_names)):
txt_name = 'val_set.txt'
elif i < len(file_names):
txt_name = 'test_set.txt'
with open(os.path.join(path, txt_name), mode='a') as file:
file.write(str(idx) + ',' + os.path.join(path, sub_dir, file_names[i]) + '\n') # 为了以后好用,修改了这里,将' '改成了',',另外路径加了sub_dir
idx += 1
if __name__ == '__main__':
data_path = 'old_data'
data_list(data_path)
结果:

参考
https://ai.deepshare.net/detail/p_5df0ad9a09d37_qYqVmt85/6
https://www.runoob.com/python/os-walk.html
https://www.runoob.com/python/os-listdir.html