新冠肺炎CT识别COVID-CT(二)| 深度之眼Pytorch打卡(八):新冠肺炎CT影像识别(二分类 | 逻辑回归)
前言
COVID-CT中把新冠肺炎CT图片识别,当做的一个二分类问题,即肺部CT中有新冠病毒和无病毒两种情况。作者给了一个用torchxrayvision中的DenseNet模型在COVID-CT数据集上的训练、验证和测试代码,其中DenseNet是预训练好的。也给了一个先在LUNA数据集上预训练,然后再在COVID-CT数据集上的训练、验证和测试的代码。对于前者,美中不足的是所有代码都是写在一个文件里的,而且import了很多没有用到的但是可能会引起错误的包,也没有可视化训练过程。当然,这些笔者都做了修改,改了代码结构、删了很多东西也引入了visdom来可视化训练过程。作为初学者,本笔记主要是学习前者,体验一下过程,至于后者就以后再说吧,虽然性能更好。
原代码及数据地址:UCSD-AI4H/COVID-CT
数据切分笔记参考:深度之眼Pytorch打卡(六):数据集切分方法
数据读取笔记参考:深度之眼Pytorch打卡(七):Pytorch数据读取机制
数据集与识别方法:新冠肺炎CT识别COVID-CT(一):新冠肺炎CT识别方法与CT数据集
环境
- Pycharm-2019.2
- torchvision-0.5.0
- Python-3.7
- torch-1.4.0
- numpy、sklearn、Visdom、torchxrayvision
- GTX1060 6G
- 可视化工具Visdom安装遇坑
pip install visdom
安装完成后用:visdom命令启动服务器,很大可能会卡在如下地方
Checking for scripts.
Downloading scripts, this may take a little while…
解决方法1:
pip install --upgrade visdom
解决方法2:
找到:虚拟环境目录\Lib\site-packages\visdom。注释掉server.py末尾的download_scripts(),同时将此文件中的static直接替换掉static文件夹。
def download_scripts_and_run():
# download_scripts()
main()
训练
- 模型简介
torchxrayvision
首先说一下torchxrayvision,它是一个仍在开发中的X射线(x-ray)影像数据集和模型,也包括用X射线影像预训练好的模型。现在torchxrayvision中模型和预训练模型还只有DenseNet121,其可以预测检测18中疾病的X射线图像,如下所示,当然还没有包括COVID-19。由于这里的模型使用x-ray影像pre_train的,我们的任务又是识别CT图像,所以,我觉得用这个预训练模型会比用torchvision中的预训练模型来进行训练效果要好。估计这也是COVID-CT作者做此选择的原因。
[‘Atelectasis’,
‘Consolidation’,
‘Infiltration’,
‘Pneumothorax’,
‘Edema’,
‘Emphysema’,
‘Fibrosis’,
‘Effusion’,
‘Pneumonia’,
‘Pleural_Thickening’,
‘Cardiomegaly’,
‘Nodule’,
‘Mass’,
‘Hernia’,
‘Lung Lesion’,
‘Fracture’,
‘Lung Opacity’,
‘Enlarged Cardiomediastinum’]
DenseNet
DenseNet是在CVPR 2017最佳论文《Dense Convolutional NetworkDenseNet》中提出的网络结构。比起ResNet的残差块(Residual Block),将一块输入直接与输出相连,DenseNet采取了一种更密集连接机制,如图1(引自DenseNet论文)所示。比起ResNet,DenseNet也有更好的性能。
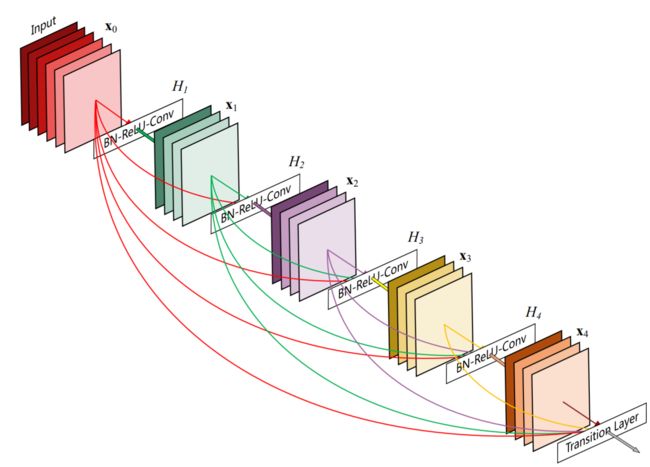
用如下一行代码就可以使用用x-ray图像预训练好的DenseNet模型,实现简单,适合初学者。
model = xrv.models.DenseNet(num_classes=2, in_channels=3).cuda() # DenseNet 模型,二分类
- 训练过程
任务类型: 二分类,逻辑回归
模型: DenseNet121
输入尺寸: 3* 224*224
batch_size: 根据自身GPU性能还设置。COVID-CT作者用的10,我改成了32。
迭代次数: 2000x14,COVID-CT迭代了3000x43次
损失函数: 交叉熵,CrossEntropyLoss()
优化器: Adam
训练过程可视化: visdom
性能评估: precision、recall、AUC、F1、acc等
数据读取实现: CovidCTDataset(Dataset)
这里用的数据读取方式与上一篇笔记的第二种读取方法类似。都是根据图像路径列表来读数据,区别是COVID-CT作者给的列表文件只有图片名,没有相对路径。所以read_txt(txt_path)解析出来的是图片名列表,需要join一些目录才能使用。Image.open(img_path).convert(‘RGB’),根据相对路径读入图像。另外,COVID-CT作者把COVID为阳性当成的负样本,我把它调转了一下,感觉更符合逻辑一点。该代码我把它放在了tools\dataload.py里。
import os
import torch
from PIL import Image
from torch.utils.data import Dataset
class CovidCTDataset(Dataset):
def __init__(self, root_dir, txt_COVID, txt_NonCOVID, transform=None):
self.root_dir = root_dir
self.txt_path = [txt_COVID, txt_NonCOVID]
self.classes = ['CT_COVID', 'CT_NonCOVID']
self.num_cls = len(self.classes)
self.img_list = []
for c in range(self.num_cls):
cls_list = [[os.path.join(self.root_dir, self.classes[c], item), c] for item in read_txt(self.txt_path[c])]
self.img_list += cls_list
self.transform = transform
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_path = self.img_list[idx][0]
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
sample = {'img': image,
'label': int(self.img_list[idx][1])}
return sample
def read_txt(txt_path):
with open(txt_path) as f:
lines = f.readlines()
txt_data = [line.strip() for line in lines] # 主要是跳过'\n'
return txt_data
训练代码实现: train(optimizer, epoch, model, train_loader, modelname, criteria)
train()方法是训练过程的核心。在方法里,完成了一个epoch的数据的训练。过程是从train_loader中去一个batch_size的图像和标签,前向传播,计算交叉熵loss,反向传播,完成一次迭代。过完全部数据,跳出函数。该代码我把它放在了tools\conduct.py里。
import os
import torch
import numpy as np
import torch.nn.functional as F
device = 'cuda'
def train(optimizer, epoch, model, train_loader, modelname, criteria):
model.train() # 训练模式
bs = 32
train_loss = 0
train_correct = 0
for batch_index, batch_samples in enumerate(train_loader):
# move data to device
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data形状,torch.Size([32, 3, 224, 224])
# data = data[:, 0, :, :] # 原作者只取了第一个通道的数据来训练,笔者改成了3个通道
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
optimizer.zero_grad()
output = model(data)
loss = criteria(output, target.long())
train_loss += criteria(output, target.long()) # 后面求平均误差用的
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = output.argmax(dim=1, keepdim=True)
train_correct += pred.eq(target.long().view_as(pred)).sum().item() # 累加预测与标签吻合的次数,用于后面算准确率
# 显示一个epoch的进度,425张图片,批大小是32,一个epoch需要14次迭代
if batch_index % 4 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tTrain Loss: {:.6f}'.format(
epoch, batch_index, len(train_loader),
100.0 * batch_index / len(train_loader), loss.item() / bs))
# print(len(train_loader.dataset)) # 425
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
train_loss / len(train_loader.dataset), train_correct, len(train_loader.dataset),
100.0 * train_correct / len(train_loader.dataset)))
if os.path.exists('performance') == 0:
os.makedirs('performance')
f = open('performance/{}.txt'.format(modelname), 'a+')
f.write('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
train_loss / len(train_loader.dataset), train_correct, len(train_loader.dataset),
100.0 * train_correct / len(train_loader.dataset)))
f.write('\n')
f.close()
return train_loss / len(train_loader.dataset) # 返回一个epoch的平均误差,用于可视化损失
验证实现代码: val(model, val_loader, criteria)
val()方法是验证过程的核心。方法将验证集所有数据送入模型,并返回与模型评价有关的数据,如预测结果,和平均损失。该代码我同样把它放在了tools\conduct.py里。
def val(model, val_loader, criteria):
model.eval()
val_loss = 0
correct = 0
# Don't update model
with torch.no_grad():
predlist = []
scorelist = []
targetlist = []
# Predict
for batch_index, batch_samples in enumerate(val_loader):
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data = data[:, 0, :, :] # 原作者只取了第一个通道的数据,笔者改成了3个通道
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
output = model(data)
val_loss += criteria(output, target.long())
score = F.softmax(output, dim=1)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.long().view_as(pred)).sum().item()
targetcpu = target.long().cpu().numpy() # 由GPU->CPU
predlist = np.append(predlist, pred.cpu().numpy())
scorelist = np.append(scorelist, score.cpu().numpy()[:, 1])
targetlist = np.append(targetlist, targetcpu)
return targetlist, scorelist, predlist, val_loss / len(val_loader.dataset)
visiom可视化训练过程:
初始化:我就只实时显示了两幅曲线图,一幅上是显示训练过程中,模型在训练集上的平均损失与在验证集上的平均损失的曲线的对比。另一幅图则是显示在训练过程中,模型在验证集上的表现。
viz = Visdom(server='http://localhost/', port=8097)
viz.line([[0., 0., 0., 0., 0.]], [0], win='train_performance', update='replace', opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[0., 0.]], [0], win='train_Loss', update='replace', opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
使用:在主函数里直接使用。
viz.line([[p, r, AUC, F1, acc]], [epoch], win='train_performance', update='append',
opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[train_loss], [val_loss]], [epoch], win='train_Loss', update='append',
opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
模型评价:
用了6个参数来评价模型的好坏,即precision、recall、accuracy、AUCp、AUC和F1。它们大多都要用TP、TN、FP和FN来计算,而这四个的计算又依赖于预测结果与标签。
TP:标签为1,预测为1,即预测是positive,对了true,标签也是positive的个数。
TN:标签为0,预测为0,即预测是negative,对了true,标签也是negative的 个数。
FN:标签为1,预测为0,即预测是negative,错了False,那标签是positive的个数。
FP:标签为0,预测为1,即预测是positive,错了False,那标签是negative的个数。
precision:p = TP / (TP + FP),所有预测为1的结果中,正确的比例。精确率越高,负例被误判成正例的可能性越小,即查的准,代价就是可能会有越多的正例被误判成负例。
recall:r = TP / (TP + FN),所有标签为1的样本中,预测正确的比例。召回率越高,就会有越少的正例被误判定成负例,即查的全,代价就是可能会有越多的负例被误判成正例。对于上述案例,肯定是recall越大越好,新冠肺炎阳性被判成阴性的代价是非常大的,而阴性判成阳性的代价相对较小,最多就是让医生多看几张片子。
F1:F1 = 2 * r * p / (r + p)是P和R的调和平均数,综合考虑准与全。
accuracy:acc = (TP + TN) / (TP + TN + FP + FN),预测正确的比例。
AUC:ROC曲线下与坐标轴围成的面积,常用于评价二分类模型的好坏。
vote_pred[vote_pred <= (votenum / 2)] = 0 # 投票,对某样本的预测,超过一半是正例,则判为正例,反之判为负例
vote_pred[vote_pred > (votenum / 2)] = 1
vote_score = vote_score / votenum
TP = ((vote_pred == 1) & (targetlist == 1)).sum()
TN = ((vote_pred == 0) & (targetlist == 0)).sum()
FN = ((vote_pred == 0) & (targetlist == 1)).sum()
FP = ((vote_pred == 1) & (targetlist == 0)).sum()
p = TP / (TP + FP)
p = TP / (TP + FP)
r = TP / (TP + FN)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
AUC = roc_auc_score(targetlist, vote_score)
训练过程代码: 训练过程主要分为5步
第一步,数据,包括数据读取和数据预处理(数据增强与标准化)。
# 数据标准化函数使用示例
torchvision.transforms.Normalize(mean, std, inplace=False)
output[channel] = (input[channel] - mean[channel]) / std[channel]
第二步,模型,模型加载
第三步,损失函数
第四步,优化器
第五步,训练
完整代码如下:我将其放在train.py里。
import os
import torch
import warnings
import numpy as np
import torch.nn as nn
from visdom import Visdom
import torch.optim as optim
import torchxrayvision as xrv
from torchvision import transforms
from torch.utils.data import DataLoader
from sklearn.metrics import roc_auc_score
from torch.optim.lr_scheduler import StepLR
# 在自定义的文件中导入方法
from tools.conduct import val
from tools.conduct import test
from tools.conduct import train
from tools.dataload import CovidCTDataset
# 预处理,标准化与图像增强
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 依通道标准化
train_transformer = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop((224), scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
val_transformer = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
if __name__ == '__main__':
batchsize = 32 # 原来用的10,这里改成32,根据个人GPU容量来定。
total_epoch = 2000 # 2000个epoch,每个epoch 14次迭代,425/32,训练完就要迭代2000*14次
votenum = 10
# ------------------------------- step 1/5 数据 ----------------------------
# 实例化CovidCTDataset
trainset = CovidCTDataset(root_dir='data',
txt_COVID='data/trainCT_COVID.txt',
txt_NonCOVID='data/trainCT_NonCOVID.txt',
transform=train_transformer)
valset = CovidCTDataset(root_dir='data',
txt_COVID='data/valCT_COVID.txt',
txt_NonCOVID='data/valCT_NonCOVID.txt',
transform=val_transformer)
testset = CovidCTDataset(root_dir='data',
txt_COVID='data/testCT_COVID.txt',
txt_NonCOVID='data/testCT_NonCOVID.txt',
transform=val_transformer)
print(trainset.__len__())
print(valset.__len__())
print(testset.__len__())
# 构建DataLoader
train_loader = DataLoader(trainset, batch_size=batchsize, drop_last=False, shuffle=True)
val_loader = DataLoader(valset, batch_size=batchsize, drop_last=False, shuffle=False)
test_loader = DataLoader(testset, batch_size=batchsize, drop_last=False, shuffle=False)
# ------------------------------ step 2/5 模型 --------------------------------
model = xrv.models.DenseNet(num_classes=2, in_channels=3).cuda() # DenseNet 模型,二分类
modelname = 'DenseNet_medical'
torch.cuda.empty_cache()
# ----------------------------- step 3/5 损失函数 ----------------------------
criteria = nn.CrossEntropyLoss() # 二分类用交叉熵损失
# ----------------------------- step 4/5 优化器 -----------------------------
optimizer = optim.Adam(model.parameters(), lr=0.0001) # Adam优化器
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10) # 动态调整学习率策略,初始学习率0.0001
# ---------------------------- step 5/5 训练 ------------------------------
viz = Visdom(server='http://localhost/', port=8097)
viz.line([[0., 0., 0., 0., 0.]], [0], win='train_performance', update='replace', opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[0., 0.]], [0], win='train_Loss', update='replace', opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
warnings.filterwarnings('ignore')
TP = 0
TN = 0
FN = 0
FP = 0
r_list = []
p_list = []
acc_list = []
AUC_list = []
vote_pred = np.zeros(valset.__len__())
vote_score = np.zeros(valset.__len__())
# 迭代3000*14次
for epoch in range(1, total_epoch + 1):
train_loss = train(optimizer, epoch, model, train_loader, modelname, criteria) # 进行一个epoch训练的函数
targetlist, scorelist, predlist, val_loss = val(model, val_loader, criteria) # 用验证集验证
print('target', targetlist)
print('score', scorelist)
print('predict', predlist)
vote_pred = vote_pred + predlist
vote_score = vote_score + scorelist
if epoch % votenum == 0: # 每10个epoch,计算一次准确率和召回率等
# major vote
vote_pred[vote_pred <= (votenum / 2)] = 0 # 投票,对某样本的预测,超过一半是正例,则判为正例,反之判为负例
vote_pred[vote_pred > (votenum / 2)] = 1
vote_score = vote_score / votenum
print('vote_pred', vote_pred)
print('targetlist', targetlist)
TP = ((vote_pred == 1) & (targetlist == 1)).sum()
TN = ((vote_pred == 0) & (targetlist == 0)).sum()
FN = ((vote_pred == 0) & (targetlist == 1)).sum()
FP = ((vote_pred == 1) & (targetlist == 0)).sum()
print('TP=', TP, 'TN=', TN, 'FN=', FN, 'FP=', FP)
print('TP+FP', TP + FP)
p = TP / (TP + FP)
print('precision', p)
p = TP / (TP + FP)
r = TP / (TP + FN)
print('recall', r)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
print('F1', F1)
print('acc', acc)
AUC = roc_auc_score(targetlist, vote_score)
print('AUC', AUC)
# 训练过程可视化
train_loss = train_loss.cpu().detach().numpy()
val_loss = val_loss.cpu().detach().numpy()
viz.line([[p, r, AUC, F1, acc]], [epoch], win='train_performance', update='append',
opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[train_loss], [val_loss]], [epoch], win='train_Loss', update='append',
opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
print(
'\n The epoch is {}, average recall: {:.4f}, average precision: {:.4f},average F1: {:.4f}, '
'average accuracy: {:.4f}, average AUC: {:.4f}'.format(
epoch, r, p, F1, acc, AUC))
# 更新模型
if os.path.exists('backup') == 0:
os.makedirs('backup')
torch.save(model.state_dict(), "backup/{}.pt".format(modelname))
vote_pred = np.zeros(valset.__len__())
vote_score = np.zeros(valset.__len__())
f = open('performance/{}.txt'.format(modelname), 'a+')
f.write(
'\n The epoch is {}, average recall: {:.4f}, average precision: {:.4f},average F1: {:.4f}, '
'average accuracy: {:.4f}, average AUC: {:.4f}'.format(
epoch, r, p, F1, acc, AUC))
f.close()
if epoch % (votenum*10) == 0: # 每100个epoch,保存一次模型
torch.save(model.state_dict(), "backup/{}_epoch{}.pt".format(modelname, epoch))
训练过程曲线:
batch_size 32,28000次迭代花了大概6个小时时间,比想象中快,还以为要训练三天三夜的。图2与图3所示的曲线,横坐标都是epoch。从图1可以看到,可能epoch在200-300的时候,模型在训练集上的损失都非常小了,再观察此时模型在训练集上的准确率,已经接近99%。说明模型已经可以很好的拟合训练集了,虽然当时感觉后面再进行训练不会有什么效果,但是还是让它迭代完了,反正也是体验过程。
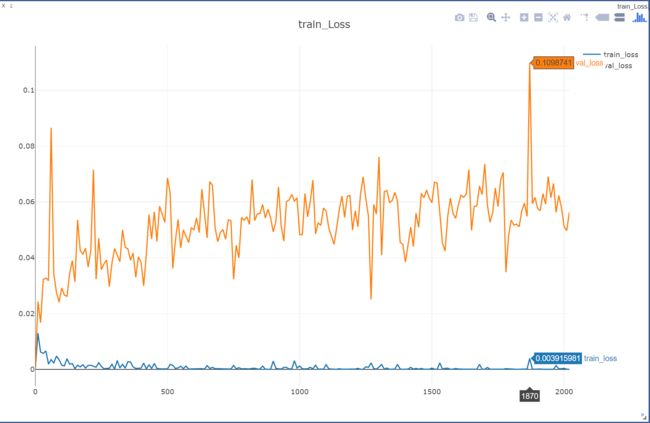
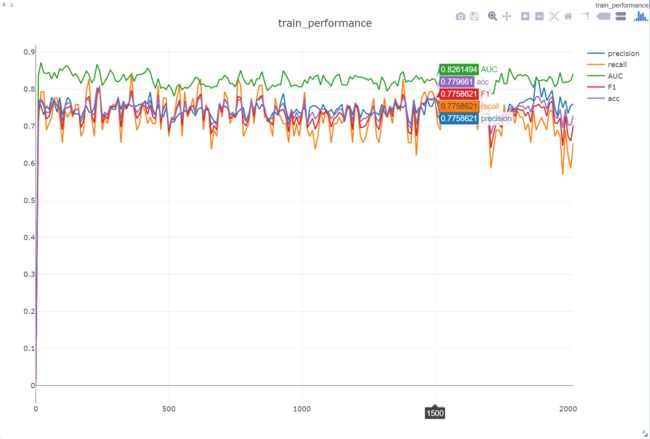
如图3所示,在大概进行了20个epoch,也就是经过大概280次迭代以后,模型在验证集上的表现一直都在以大概0.75为基准,上下波动,到1500个epoch后,波动稍微大了点。我想可能是训练集上的误差太小了,导致更新参数幅度非常小,所以模型表现也差不多。看着这个曲线,会让人内心感到迷茫。
每100个epoch保存一次代码,最后挑选表现较好的,这也是验证集的作用。输出的20个模型参数如图4所示。
测试
- 测试代码实现:test(model, test_loader, criteria)
test()方法是测试过程的核心,代码基本与val()一样。方法将测试集所有数据送入模型,并返回与模型评价有关的数据。该代码我同样把它放在了tools\conduct.py里。
def test(model, test_loader):
model.eval()
# Don't update model
with torch.no_grad():
predlist = []
scorelist = []
targetlist = []
# Predict
for batch_index, batch_samples in enumerate(test_loader):
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data = data[:, 0, :, :] # 只取了第一个通道的数据来训练,笔者改成了灰度图像
# data = 0.299 * data[:, 0, :, :] + 0.587 * data[:, 1, :, :] + 0.114 * data[:, 2, :, :]
# data形状,torch.Size([32, 224, 224])
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
# print(target)
output = model(data)
score = F.softmax(output, dim=1)
pred = output.argmax(dim=1, keepdim=True)
targetcpu = target.long().cpu().numpy()
predlist = np.append(predlist, pred.cpu().numpy())
scorelist = np.append(scorelist, score.cpu().numpy()[:, 1])
targetlist = np.append(targetlist, targetcpu)
return targetlist, scorelist, predlist
- 测试流程
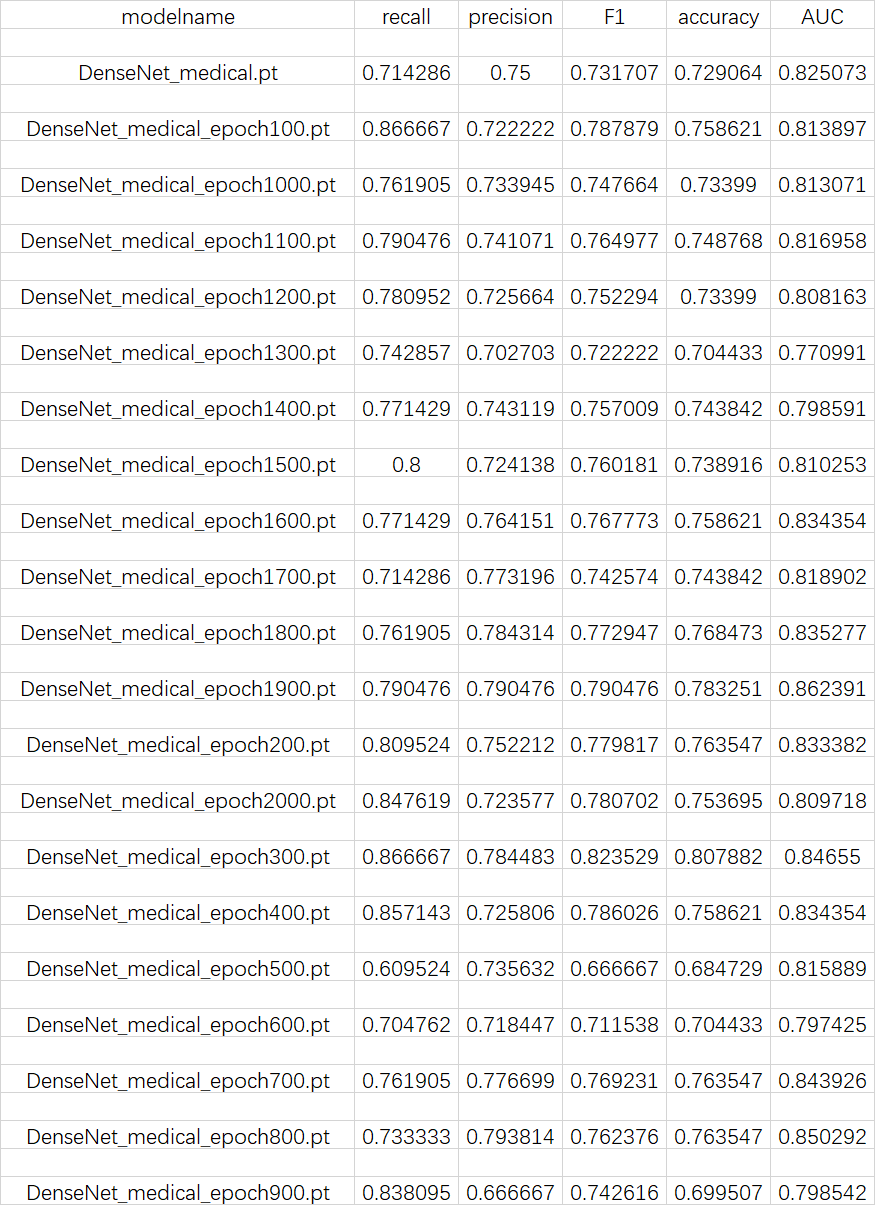
测试过程和验证过程都是一样的。只是完成前向传播,包括数据、模型和测试三步。训练过程中生成的20个模型参数,我都测试了一遍,最后的结果保存到了performance/test_model.csv里。代码如下,我把它放在了predict.py里。
import os
import csv
import torch
import warnings
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torchxrayvision as xrv
from torchvision import transforms
from torch.utils.data import DataLoader
from sklearn.metrics import roc_auc_score
from tools.conduct import test
from tools.dataload import CovidCTDataset
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 依通道标准化
test_transformer = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
if __name__ == '__main__':
batchsize = 32 # 原来用的10,这里改成32,根据个人GPU容量来定。
# ------------------------------- step 1/3 数据 ----------------------------
# 实例化CovidCTDataset
testset = CovidCTDataset(root_dir='data',
txt_COVID='data/testCT_COVID.txt',
txt_NonCOVID='data/testCT_NonCOVID.txt',
transform=test_transformer)
print(testset.__len__())
# 构建DataLoader
test_loader = DataLoader(testset, batch_size=batchsize, drop_last=False, shuffle=False)
# ------------------------------ step 2/3 模型 --------------------------------
model = xrv.models.DenseNet(num_classes=2, in_channels=3).cuda() # DenseNet 模型,二分类
modelname = 'DenseNet_medical'
torch.cuda.empty_cache()
# ---------------------------- step 3/3 测试 ------------------------------
f = open(f'performance/test_model.csv', mode='w')
csv_writer = csv.writer(f)
flag = 1
for modelname in os.listdir('backup'):
model.load_state_dict(torch.load('backup/{}'.format(modelname)))
torch.cuda.empty_cache()
bs = 10
warnings.filterwarnings('ignore')
r_list = []
p_list = []
acc_list = []
AUC_list = []
TP = 0
TN = 0
FN = 0
FP = 0
vote_score = np.zeros(testset.__len__())
targetlist, scorelist, predlist = test(model, test_loader)
vote_score = vote_score + scorelist
TP = ((predlist == 1) & (targetlist == 1)).sum()
TN = ((predlist == 0) & (targetlist == 0)).sum()
FN = ((predlist == 0) & (targetlist == 1)).sum()
FP = ((predlist == 1) & (targetlist == 0)).sum()
p = TP / (TP + FP)
p = TP / (TP + FP)
r = TP / (TP + FN)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
AUC = roc_auc_score(targetlist, vote_score)
print(
'\n{}, recall: {:.4f}, precision: {:.4f},F1: {:.4f}, accuracy: {:.4f}, AUC: {:.4f}'.format(
modelname, r, p, F1, acc, AUC))
if flag:
header = ['modelname', 'recall', 'precision', 'F1', 'accuracy', 'AUC']
csv_writer.writerow(header)
flag = 0
row = [modelname, str(r), str(p), str(F1), str(acc), str(AUC)]
csv_writer.writerow(row)
f.close()
- 测试结果
训练前模型的表现:
recall: 1.0000, precision: 0.5172,F1: 0.6818, accuracy: 0.5172, AUC: 0.3694
COVID-CT作者训练该模型的表现:
average recall: 0.8667, average precision: 0.8426,average F1: 0.8545, average accuracy: 0.8465, average AUC: 0.9186
笔者训练该模型的表现
DenseNet_medical_epoch300.pt, recall: 0.8667, precision: 0.7845,F1: 0.8235, accuracy: 0.8079, AUC: 0.8466,这是笔者觉得表现最好的一个模型参数,其他模型参数表现见表1。
参考
https://www.cnblogs.com/HL-space/p/10990407.html
https://github.com/UCSD-AI4H/COVID-CT