机器学习实战笔记---Logistic回归
本文转自https://blog.csdn.net/u010454729/article/details/48274955和http://cuijiahua.com/blog/2017/11/ml_6_logistic_1.html
实现Logistic回归分类器:在每个特征上都乘以一个回归系数,然后把所有的结果值相加,总和带入Sigmoid函数,其结果大于0.5分为正样本类,结果小于0.5分为负样本类。
sigmoid函数:
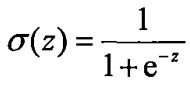
Sigmoid的输入z:
![]()
其可以写成z=wT*x,向量x为分类器的输入数据, w为训练器寻找的最佳参数。

参数迭代公式:

使用梯度上升找到最佳参数w:
伪代码:

假设Sigmoid的输入为z,求得的最佳回归系数(最优参数)为![]() ,那么:
,那么:
![]() 即可将数据分割开
即可将数据分割开
令z=0,则![]() (
(![]() )
)
这样就求出来决策边界。
import numpy as np
import matplotlib.pyplot as plt
#加载函数
def loadDataSet():
dataMat=[]
labelMat=[]
fr=open("D:/anicode/spyderworkspace/examtest/testSet.txt")
for line in fr.readlines():
lineArr=line.strip().split()
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
labelMat.append(int(lineArr[2]))
fr.close()
return dataMat,labelMat
#可视化
def plotBestFit(weights):
dataMat,labelMat=loadDataSet()
dataArr=np.array(dataMat)
n=np.shape(dataMat)[0]
xcord1=[]
ycord1=[]
xcord2=[]
ycord2=[]
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1])
ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=20,c='red',marker='s',alpha=.5)
ax.scatter(xcord2,ycord2,s=20,c='green',alpha=.5)
x=np.arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]#令z=0,则x_2=(-w_0-w_1 *x_1)/w_2
ax.plot(x,y)
plt.title('BestFit')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
def sigmoid(inX):
return 1.0/(1+np.exp(-inX))
#梯度上升函数
def gradAscent(dataMatIn,classLabels):
dataMatrix=np.mat(dataMatIn)
labelMat=np.mat(classLabels).transpose()
m,n=np.shape(dataMatrix)
alpha=0.001
maxCycles=500
weights=np.ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)
error=labelMat-h
weights=weights+alpha*dataMatrix.transpose()*error
return weights.getA()
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
weights=gradAscent(dataMat,labelMat)
plotBestFit(weights)
改进
#随机梯度上升函数
def stocGradAscent(dataMatrix,classLabels,numIter=150):
m,n=np.shape(dataMatrix)
weights=np.ones(n)
for j in range(numIter):
dataIndex=list(range(m))
for i in range(m):
alpha=4/(1.0+j+i)+0.01
randIndex=int(random.uniform(0,len(dataIndex)))
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
if __name__=='__main__':
dataMat,labelMat=loadDataSet()
weights=stocGradAscent(np.array(dataMat),labelMat)
plotBestFit(weights)

预测病马死亡率
import numpy as np
import random
def sigmoid(inX):
return 1.0/(1+np.exp(-inX))
def stocGradAscent(dataMatrix,classLabels,numIter=150):
m,n=np.shape(dataMatrix)
weights=np.ones(n)
for j in range(numIter):
dataIndex=list(range(m))
for i in range(m):
alpha=4/(1.0+j+i)+0.01
randIndex=int(random.uniform(0,len(dataIndex)))
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*dataMatrix[randIndex]*error
del(dataIndex[randIndex])
return weights
def colicTest():
frTrain=open("D:/anicode/spyderworkspace/examtest/horseColicTraining.txt")
frTest=open("D:/anicode/spyderworkspace/examtest/horseColicTest.txt")
trainingSet=[]
trainingLabels=[]
for line in frTrain.readlines():
currLine=line.strip().split('\t')
lineArr=[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
trainWeights=stocGradAscent(np.array(trainingSet),trainingLabels,500)
errorCount=0
numTestVec=0.0
for line in frTest.readlines():
numTestVec+=1.0
currLine=line.strip().split('\t')
lineArr=[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr),trainWeights))!=int(currLine[-1]):
errorCount+=1
errorRate=(float(errorCount)/numTestVec)*100
print("测试集错误率:%.2f%%"% errorRate)
def classifyVector(inX,weights):
prob=sigmoid(sum(inX*weights))
if prob>0.5:
return 1.0
else:
return 0.0
if __name__=='__main__':
colicTest()![]()