Python 3实现k-邻近算法以及 iris 数据集分类应用
前言
这个周基本在琢磨这个算法以及自己利用Python3 实现自主编程实现该算法。持续时间比较长,主要是Pyhton可能还不是很熟练,走了很多路,基本是一边写一边学。不过,总算是基本搞出来了。不多说,进入正题。
1. K-邻近算法
1.1 基本原理
k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存
在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分
类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本
最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,
通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
1.2 一个例子
先来看一个图:
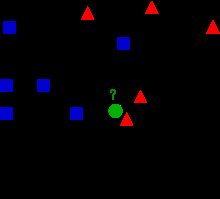
在这个图里面,我们可以看到有第三种颜色标记的标签,蓝色正方形,红色三角形以及一个未知类型的绿色原点。那么如何判断这
个绿色点是属于蓝色家族的还是红色家族的呢?
邻近的思想就是计算这个绿色的点分别到它附近的点的距离,距离近就判定属于这个类型,那么K-邻近就是让待分类的这个点与所
有的已经分类点的距离,然后选取K个点,统计待分类的这个绿色点属于哪个类别的数量比较多,就最终判定这个点属于哪一个。
再回到图,首先是K=3,可以看到实线里面有两个红点,一个蓝点,那么判定这个绿家伙属于红色的三角形类型。接着,选取了近
距离绿色点最近的5个点,这时,会发现,蓝色系占得更多,所以,判定这个绿家伙是属于蓝色正方形的类型。
从这个例子可以看出来,K-邻近的几个基本关键点有:
点之间的距离计算
- 欧式距离:
d12=∑i=1n(x1i−x2i)−−−−−−−−−−−√ 曼哈顿距离:
两个向量 a(x11,xx12,⋯,x1n) 与 b(x21,xx22,⋯,x2n) 的曼哈顿距离为:
d12=∑k=1n|x1k−x2k|其他
参考http://www.cnblogs.com/xbinworld/archive/2012/09/24/2700572.html
里面有着更加详细的关于距离的介绍。
- 欧式距离:
距离排序
在这个计算的过程中,需要将最终的计算进行一个排序的。为下一步操作做好准备。K的选择
很明显,对于这算法,K的选取决定了整个算法分类预测的准确性,可以说是其核心参数。从上面的例子也可以看出来,K=3和K=5得到的决然不同的结果的。
1.3 算法步骤
(1)初始化距离
(2)计算待分类样本和每个训练集的距离
(3)排序
(4)选取K个最邻近的数据
(5)计算K个训练样本的每类标签出现的概率
(6)将待分类样本归为出现概率最大的标签,分类结束。
2. Python实现K-邻近算法
2.1 K-邻近函数
def mykNN(testData, trainData, label, K):
# testData 待分类的数据集
# trainData 已经分类好的数据集
# label trainData数据集里面的分类标签
# K是knn算法中的K
# testData=[101,20]
# testData=np.array(testData)
import numpy as np
arraySize = trainData.shape
trainingSampleNumber = arraySize[0] # 样本大小
trainFeatureNumber = arraySize[1] # 样本特征个数
# 将待测试样本拓展为和训练集一样大小矩阵
testDataTemp = np.tile(testData, (trainingSampleNumber, 1))
distanceMatrixTemp = (testDataTemp - trainData)**2
distanceMatrix = np.sum(distanceMatrixTemp, axis=1)
distanceMatrix = np.sqrt(distanceMatrix)
# print('测试集与训练集之间的欧式距离值为:\n')
# print(distanceMatrix)
# print()
# np.argsort()得到矩阵排序后的对应的索引值
sortedDistanceIndex = np.argsort(distanceMatrix)
# print(sortedDistanceIndex)
# 定义一个统计类别的字典
labelClassCount = {}
for i in range(K):
labelTemp = label[sortedDistanceIndex[i]] # 获取排名前K的距离对应的类别值
# print(labelTemp)
labelClassCount[labelTemp] = labelClassCount.get(
labelTemp, 0) + 1 # 统计前K中每个类别出现的次数
# print(labelClassCount)
sortedLabelClassCount = sorted(labelClassCount.items(), key=lambda item: item[
1], reverse=True) # 对字典进行降序排序
# lambda item:item[1] 匿名函数,将利用dict.items()获取的字典的key-value作为该匿名函数的变量输入。# reverse=True 降序排列
# print(sortedLabelClassCount)
return sortedLabelClassCount[0][0] # 返回最终的分类标签值2.2 牛刀小试-电影分类
举个简单的例子,我们可以使用k-近邻算法分类一个电影是爱情片还是动作片。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 电影1 | 1 | 101 | Romance |
| 电影2 | 5 | 89 | Romance |
| 电影3 | 108 | 5 | action |
| 电影4 | 115 | 8 | action |
以上是已知的训练样本,我们需预测的是(101, 20)这个样本,我们大致可以知道,打斗镜头多则应该是动作片
数据集函数
def creatDataSet():
#定义数据集函数
group = np.array([[1, 101, 5], [5, 89, 6], [108, 5, 100], [115, 8, 120]])
label = ['romance Movie', 'romance Movie', 'action Movie', 'action Movie']
# label=['r','r','a','a']
return group, label
# print(group)
# print(label)'''
主函数
if __name__=='__main__':
#主函数
finalIdentifyingResult=[]
group,label=creatDataSet()
print()
print('Identifying ......')
print()
print('The identified result is :\n')
testData=[101,20]
testData=np.array(testData)
finalIdentifyingLabel=mykNN(testData,group,label,3)
print('the test data is identified as: ',finalIdentifyingLabel,'\n')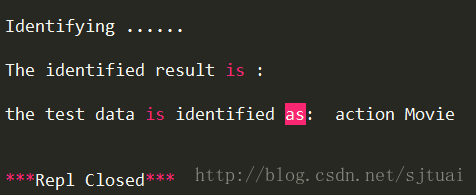
可以看出来,分类结果和我们预测的是一致的,动作电影。
完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-08-28 16:04:25
# @Author : AiYong ([email protected])
# @Link : http://blog.csdn.net/sjtuai
# @Version : $Id$
import numpy as np
def creatDataSet():
group = np.array([[1, 101], [5, 89], [108, 5], [115, 8]])
label = ['romance Movie', 'romance Movie', 'action Movie', 'action Movie']
return group, label
print(group)
print(label)
def mykNN(testData, trainData, label, K):
arraySize = trainData.shape
trainingSampleNumber = arraySize[0]
testDataTemp = np.tile(testData, (trainingSampleNumber, 1))
distanceMatrixTemp = (testDataTemp - trainData)**2
distanceMatrix = np.sum(distanceMatrixTemp, axis=1)
distanceMatrix = np.sqrt(distanceMatrix)
sortedDistanceIndex = np.argsort(distanceMatrix)
labelClassCount = {}
for i in range(K):
labelTemp = label[sortedDistanceIndex[i]]
labelClassCount[labelTemp] = labelClassCount.get(
labelTemp, 0) + 1
sortedLabelClassCount = sorted(labelClassCount.items(), key=lambda item: item[
1], reverse=True)
return sortedLabelClassCount[0][0]
if __name__=='__main__':
finalIdentifyingResult=[]
group,label=creatDataSet()
print()
print('Identifying ......')
print()
print('The identified result is :\n')
testData=[101,20]
testData=np.array(testData)
finalIdentifyingLabel=mykNN(testData,group,label,3)
print('the test data is identified as: ',finalIdentifyingLabel,'\n')
2.3 考验阶段-鸢尾花数据集应用-分类预测
鸢尾花数据集
U can get description of ‘iris.csv’ at ‘http://aima.cs.berkeley.edu/data/iris.txt‘####
Definiation of COLs:
#1. sepal length in cm (花萼长) #
#2. sepal width in cm(花萼宽)#
#3. petal length in cm (花瓣长)
#4. petal width in cm(花瓣宽) #
#5. class: #
#– Iris Setosa #
#– Iris Versicolour #
#– Iris Virginica #
#Missing Attribute Values: None
数据集整理函数
def creatDataSet(fileName, test_size_ratio):
# fileName is the data file whose type is string
# test_size whose type is float is the ratio of test data in the whole
# data set
irisData = np.loadtxt(fileName, dtype=float,
delimiter=',', usecols=(0, 1, 2, 3))
dataSize = irisData.shape
irisLabel = np.loadtxt(fileName, dtype=str, delimiter=',', usecols=4)
irisLabel = irisLabel.reshape(dataSize[0], 1)
#这里使用的一个函数是机器学习库中的一个可以用来随机选取训练集和测试集的一个函数
iristrainData, iristestData, iristrainDataLabel, iristestDataLabel = cross_validation.train_test_split(
irisData, irisLabel, test_size=test_size_ratio, random_state=0)
return iristrainData, iristestData, iristrainDataLabel, iristestDataLabel矩阵转化为列表函数
def ndarray2List(label):
#这个函数的目的是为了后的数据服务的。
label = label.tolist()
finalLabel = []
for i in range(label.__len__()):
finalLabel.append('\n'.join(list(label[i])))
return finalLabel自定义混淆矩阵计算函数
def computingConfusionMatrix(trueResultA, modelPredictResultB):
# trueResultA 正确的分类结果,numpy矩阵类型
# modelPredictResultB 模型预测结果,numpy矩阵类型
# labelType 分类标签值,list列表类型
#返回,confusionMatrix,混淆矩阵,numpy矩阵类型
#返回,labelType,分类标签,list列表类型
#返回,Accuracy,分类争取率,float浮点数据
import numpy as np
labelType = []
for i in trueResultA:
if i not in labelType:
labelType.append(i)
print(labelType)
labelTypeNumber = labelType.__len__()
confusionMatrix = np.zeros(
[labelTypeNumber, labelTypeNumber], dtype='int64')
finalCount = 0
for i in range(labelTypeNumber):
for j in range(trueResultA.__len__()):
if modelPredictResultB[j] == labelType[i] and trueResultA[j] == labelType[i]:
confusionMatrix[i][i] += 1
else:
for k in range(labelTypeNumber):
if k == i:
break
if modelPredictResultB[j] == labelType[k]:
confusionMatrix[i][k] += 1
break
count = 0
for i in range(labelTypeNumber - 1, -1, -1):
if i == 0:
break
for j in range(labelTypeNumber - 1 - count):
confusionMatrix[i][j] = confusionMatrix[
i][j] - confusionMatrix[i - 1][j]
count += 1
totalTrueResult = 0
for k in range(labelTypeNumber):
totalTrueResult += confusionMatrix[k][k]
Accuracy = float(totalTrueResult / modelPredictResultB.__len__()) * 100
return confusionMatrix, labelType, Accuracy定义图里面的横纵坐标轴标签值的旋转
def labelsRotation(labels, rotatingAngle):
#labels 获取的x,y轴的标签值
#rotatingAngle 想要旋转的角度
# 定义x,y轴标签旋转函数
for t in labels:
t.set_rotation(rotatingAngle)
定义混淆矩阵可视化函数
def plotConfusionMatrix(confusionMatrix,labelType):
import matplotlib.pyplot as plt
# 设置图片的大小以及图片分辨率
fig = plt.figure(figsize=(10, 8), dpi=120)
plt.clf()
# 绘制图,colormap是coolwarm
plt.imshow(confusionMatrix, cmap=plt.cm.coolwarm, interpolation='nearest')
plt.colorbar()
# 设置x,y的横纵轴的标签
plt.xlabel('Predicted Result', fontsize=11)
plt.ylabel('True Result', fontsize=11)
cmSize = confusionMatrix.shape
width = cmSize[0]
height = cmSize[1]
plt.xticks(fontsize=11)
plt.yticks(fontsize=11)
# 设置横纵坐标的刻度标签,显示为分类标签值
x_locs, x_labels = plt.xticks(range(width), labelType[:width])
y_locs, y_labels = plt.yticks(range(height), labelType[:height])
# 设置x,y轴的标签是否旋转
labelsRotation(x_labels, 0)
labelsRotation(y_labels, 0)
# 在图里面添加数据标签
confusionMatrix = confusionMatrix.T
for x in range(width): # 数据标签
for y in range(height):
plt.annotate(confusionMatrix[x][y], xy=(
x, y), horizontalalignment='center', verticalalignment='center')
plt.grid(True, which='minor', linestyle='-')
# plt.rc('font',family='Times New Roman',size=15)
font = {'family': 'monospace', 'weight': 'bold', 'size': 15}
plt.rc('font', **font)
plt.show()主函数
if __name__ == '__main__':
finalIdentifyingResult = []
iriskNNResult = []
iristrainData, iristestData, iristrainDataLabel, iristestDataLabel = creatDataSet(
'iris.txt', 0.8)
testGroup = iristestData
trainGroup = iristrainData
trainLabel = iristrainDataLabel
testSize = testGroup.shape
testSampleNumber = testSize[0]
print()
print('Identifying ......')
print()
print('The identified result is :\n')
for i in range(testSampleNumber):
testData = testGroup[i]
finalIdentifyingLabel = mykNN(testData, trainGroup, trainLabel, 10)
finalIdentifyingResult.append(finalIdentifyingLabel)
iriskNNResult = np.array(
finalIdentifyingResult).reshape(testSampleNumber, 1)
print(finalIdentifyingResult)
trueResultA = ndarray2List(iristestDataLabel)
modelPredictResultB = finalIdentifyingResult
confusionMatrix, labelType, Accuracy = computingConfusionMatrix(
trueResultA, modelPredictResultB)
print('The accuracy is :{a:5.3f}%'.format(a=Accuracy))
plotConfusionMatrix(confusionMatrix, labelType)
结果
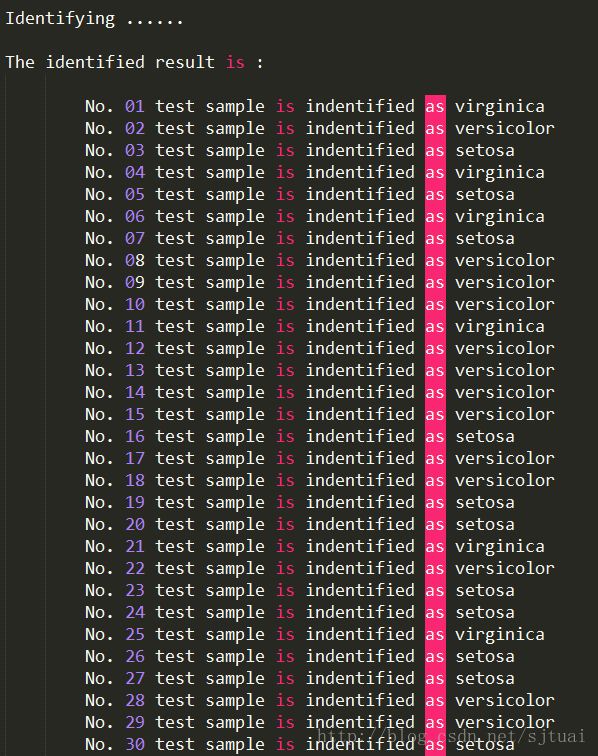
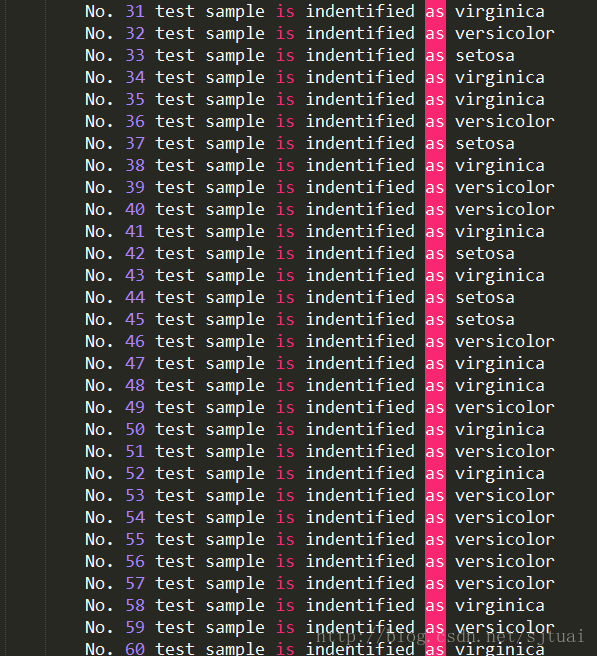

混淆矩阵
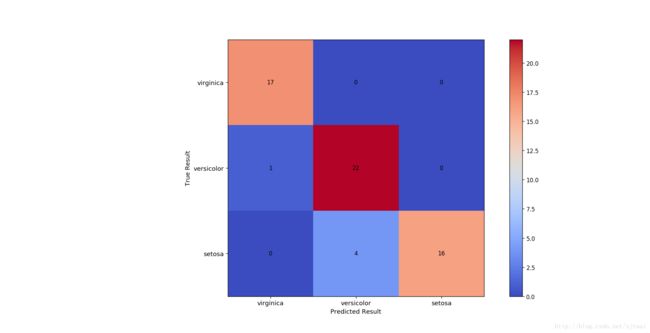
从上面的结果可以看到这个准确率在90%以上,说明还是不错的!
完整的程序结构
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2017-08-08 16:04:25
# @Author : AiYong ([email protected])
# @Link : http://blog.csdn.net/sjtuai
# @Version : $Id$
import numpy as np
from sklearn import cross_validation
import matplotlib.pyplot as plt
def mykNN(testData, trainData, label, K):
# testData 待分类的数据集
# trainData 已经分类好的数据集
# label trainData数据集里面的分类标签
# K是knn算法中的K
# testData=[101,20]
# testData=np.array(testData)
import numpy as np
arraySize = trainData.shape
trainingSampleNumber = arraySize[0] # 样本大小
trainFeatureNumber = arraySize[1] # 样本特征个数
# 将待测试样本拓展为和训练集一样大小矩阵
testDataTemp = np.tile(testData, (trainingSampleNumber, 1))
distanceMatrixTemp = (testDataTemp - trainData)**2
distanceMatrix = np.sum(distanceMatrixTemp, axis=1)
distanceMatrix = np.sqrt(distanceMatrix)
# print('测试集与训练集之间的欧式距离值为:\n')
# print(distanceMatrix)
# print()
# np.argsort()得到矩阵排序后的对应的索引值
sortedDistanceIndex = np.argsort(distanceMatrix)
# print(sortedDistanceIndex)
# 定义一个统计类别的字典
labelClassCount = {}
for i in range(K):
labelTemp = label[sortedDistanceIndex[i]] # 获取排名前K的距离对应的类别值
# print(labelTemp)
labelClassCount[labelTemp] = labelClassCount.get(
labelTemp, 0) + 1 # 统计前K中每个类别出现的次数
# print(labelClassCount)
sortedLabelClassCount = sorted(labelClassCount.items(), key=lambda item: item[
1], reverse=True) # 对字典进行降序排序
# lambda item:item[1] 匿名函数,将利用dict.items()获取的字典的key-value作为该匿名函数的变量输入。# reverse=True 降序排列
# print(sortedLabelClassCount)
return sortedLabelClassCount[0][0] # 返回最终的分类标签值
def creatDataSet(fileName, test_size_ratio):
# fileName is the data file whose type is string
# test_size whose type is float is the ratio of test data in the whole
# data set
irisData = np.loadtxt(fileName, dtype=float,
delimiter=',', usecols=(0, 1, 2, 3))
dataSize = irisData.shape
irisLabel = np.loadtxt(fileName, dtype=str, delimiter=',', usecols=4)
irisLabel = irisLabel.reshape(dataSize[0], 1)
#这里使用的一个函数是机器学习库中的一个可以用来随机选取训练集和测试集的一个函数
iristrainData, iristestData, iristrainDataLabel, iristestDataLabel = cross_validation.train_test_split(
irisData, irisLabel, test_size=test_size_ratio, random_state=0)
return iristrainData, iristestData, iristrainDataLabel, iristestDataLabel
def ndarray2List(label):
#这个函数的目的是为了后的数据服务的。
label = label.tolist()
finalLabel = []
for i in range(label.__len__()):
finalLabel.append('\n'.join(list(label[i])))
return finalLabel
def computingConfusionMatrix(trueResultA, modelPredictResultB):
# trueResultA 正确的分类结果,numpy矩阵类型
# modelPredictResultB 模型预测结果,numpy矩阵类型
# labelType 分类标签值,list列表类型
#返回,confusionMatrix,混淆矩阵,numpy矩阵类型
#返回,labelType,分类标签,list列表类型
#返回,Accuracy,分类争取率,float浮点数据
import numpy as np
labelType = []
for i in trueResultA:
if i not in labelType:
labelType.append(i)
print(labelType)
labelTypeNumber = labelType.__len__()
confusionMatrix = np.zeros(
[labelTypeNumber, labelTypeNumber], dtype='int64')
finalCount = 0
for i in range(labelTypeNumber):
for j in range(trueResultA.__len__()):
if modelPredictResultB[j] == labelType[i] and trueResultA[j] == labelType[i]:
confusionMatrix[i][i] += 1
else:
for k in range(labelTypeNumber):
if k == i:
break
if modelPredictResultB[j] == labelType[k]:
confusionMatrix[i][k] += 1
break
count = 0
for i in range(labelTypeNumber - 1, -1, -1):
if i == 0:
break
for j in range(labelTypeNumber - 1 - count):
confusionMatrix[i][j] = confusionMatrix[
i][j] - confusionMatrix[i - 1][j]
count += 1
totalTrueResult = 0
for k in range(labelTypeNumber):
totalTrueResult += confusionMatrix[k][k]
Accuracy = float(totalTrueResult / modelPredictResultB.__len__()) * 100
return confusionMatrix, labelType, Accuracy
def labelsRotation(labels, rotatingAngle):
#labels 获取的x,y轴的标签值
#rotatingAngle 想要旋转的角度
# 定义x,y轴标签旋转函数
for t in labels:
t.set_rotation(rotatingAngle)
def plotConfusionMatrix(confusionMatrix,labelType):
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10, 8), dpi=120)
plt.clf()
plt.imshow(confusionMatrix, cmap=plt.cm.coolwarm, interpolation='nearest')
plt.colorbar()
plt.xlabel('Predicted Result', fontsize=11)
plt.ylabel('True Result', fontsize=11)
cmSize = confusionMatrix.shape
width = cmSize[0]
height = cmSize[1]
plt.xticks(fontsize=11)
plt.yticks(fontsize=11)
x_locs, x_labels = plt.xticks(range(width), labelType[:width])
y_locs, y_labels = plt.yticks(range(height), labelType[:height])
labelsRotation(x_labels, 0)
labelsRotation(y_labels, 0)
confusionMatrix = confusionMatrix.T
for x in range(width): # 数据标签
for y in range(height):
plt.annotate(confusionMatrix[x][y], xy=(
x, y), horizontalalignment='center', verticalalignment='center')
plt.grid(True, which='minor', linestyle='-')
font = {'family': 'monospace', 'weight': 'bold', 'size': 15}
plt.rc('font', **font)
plt.show()
if __name__ == '__main__':
finalIdentifyingResult = []
iriskNNResult = []
iristrainData, iristestData, iristrainDataLabel, iristestDataLabel = creatDataSet(
'iris.txt', 0.8)
testGroup = iristestData
trainGroup = iristrainData
trainLabel = iristrainDataLabel
testSize = testGroup.shape
testSampleNumber = testSize[0]
print()
print('Identifying ......')
print()
print('The identified result is :\n')
for i in range(testSampleNumber):
testData = testGroup[i]
finalIdentifyingLabel = mykNN(testData, trainGroup, trainLabel, 10)
finalIdentifyingResult.append(finalIdentifyingLabel)
iriskNNResult = np.array(
finalIdentifyingResult).reshape(testSampleNumber, 1)
print(finalIdentifyingResult)
trueResultA = ndarray2List(iristestDataLabel)
modelPredictResultB = finalIdentifyingResult
confusionMatrix, labelType, Accuracy = computingConfusionMatrix(
trueResultA, modelPredictResultB)
print('The accuracy is :{a:5.3f}%'.format(a=Accuracy))
plotConfusionMatrix(confusionMatrix, labelType)
3. 总结
这里有非常好的关于K-邻近分类的理论以及一些比较好的图理:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
3.1 优缺点
优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
3.2 一些问题集锦
1、k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
在训练集中,有些样本可能是更值得依赖的。
可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
参考链接:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
http://blog.csdn.net/jmydream/article/details/8644004
http://wuguangbin1230.blog.163.com/blog/static/61529835201522905624494/
https://docs.scipy.org/doc/numpy-dev/user/quickstart.html
http://matplotlib.org/api/pyplot_summary.html