NLP-用RNN/LSTM做文本生成
- 说明:学习笔记,内容来自七月在线视频-作者加号
一、带记忆神经网络
文本生成,光直接feed不行,我们希望我们的分类器能够记得上下文前后关系,RNN的目的就是让有sequential关系的信息得到考虑。sequential关系是信息在时间上的前后关系。
1.RNN
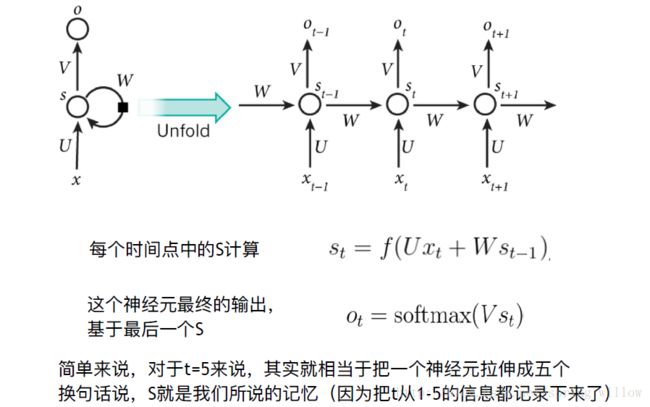
2.LSTM-加强版RNN
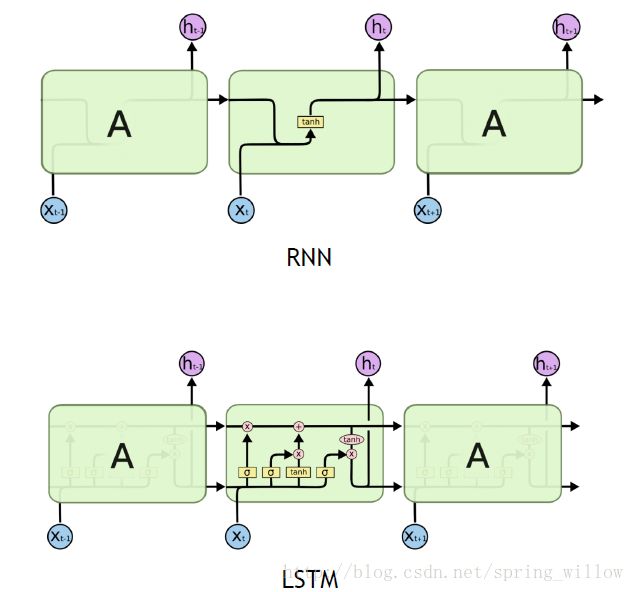
- 说明
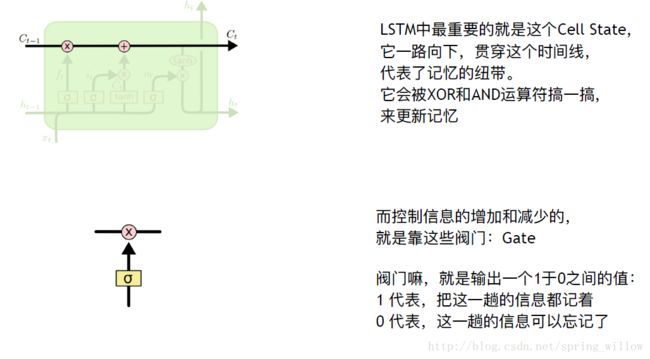
3.模拟信息在LSTM的变化
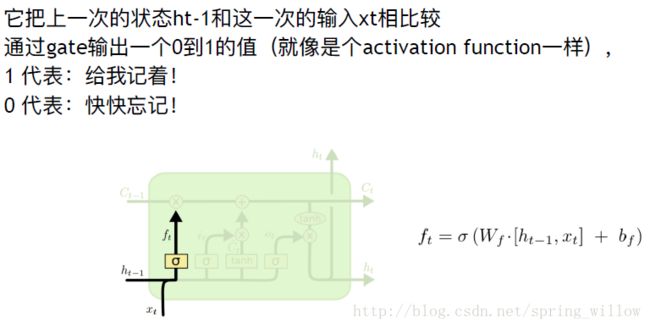
①忘记门
决定了我们应该忘记哪些信息
②记忆门
哪些该记住
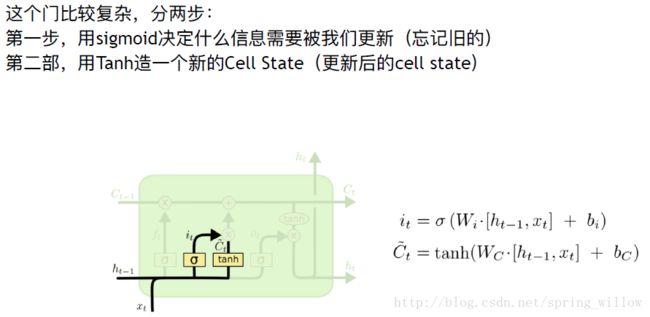
③更新门
把老的cell state更新为新的cell state

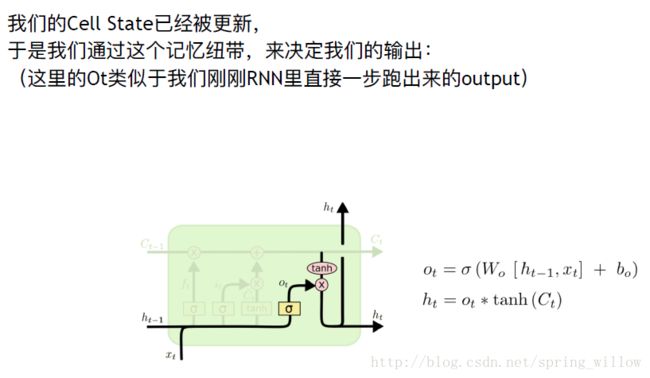
④输出门
由记忆来决定输出什么门
二、使用LSTM做文本生成
1.预料说明:各种中文语料可以自行网上查找, 英文的小说语料可以从古登堡计划网站下载txt文本
2.文本生成:以char层级或以word层级生成
3.代码步骤:
- 第一步,导入所需的库
import os
import numpy as np
import nltk
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
from gensim.models.word2vec import Word2Vec- 第二步,文本读入
raw_text = ''
for file in os.listdir("../input/"):
if file.endswith(".txt"):
raw_text += open("../input/"+file, errors='ignore').read() + '\n\n'
# raw_text = open('../input/Winston_Churchil.txt').read()
raw_text = raw_text.lower()
sentensor = nltk.data.load('tokenizers/punkt/english.pickle')
sents = sentensor.tokenize(raw_text)
corpus = []
for sen in sents:
corpus.append(nltk.word_tokenize(sen))- 第三步,w2v乱炖
w2v_model = Word2Vec(corpus, size=128, window=5, min_count=5, workers=4)- 第四步,处理我们的training data,把源数据变成一个长长的x,好让LSTM学会predict下一个单词
raw_input = [item for sublist in corpus for item in sublist]
text_stream = []
vocab = w2v_model.vocab
for word in raw_input:
if word in vocab:
text_stream.append(word)
len(text_stream)- 第五步,构造训练测试集
seq_length = 10
x = []
y = []
for i in range(0, len(text_stream) - seq_length):
given = text_stream[i:i + seq_length]
predict = text_stream[i + seq_length]
x.append(np.array([w2v_model[word] for word in given]))
y.append(w2v_model[predict])
# 我们可以看看做好的数据集的长相
print(x[10])
print(y[10])- 第六步,①我们已经有了一个input的数字表达(w2v),我们要把它变成LSTM需要的数组格式: [样本数,时间步伐,特征],,②对于output,我们直接用128维的输出
x = np.reshape(x, (-1, seq_length, 128))
y = np.reshape(y, (-1,128))- 第七步,LSTM模型构建
model = Sequential()
model.add(LSTM(256, dropout_W=0.2, dropout_U=0.2, input_shape=(seq_length, 128)))
model.add(Dropout(0.2))
model.add(Dense(128, activation='sigmoid'))
model.compile(loss='mse', optimizer='adam')- 第八步,跑模型
model.fit(x, y, nb_epoch=50, batch_size=4096)- 最后,写程序检验训练出的模型效果
# ①
def predict_next(input_array):
x = np.reshape(input_array, (-1,seq_length,128))
y = model.predict(x)
return y
def string_to_index(raw_input):
raw_input = raw_input.lower()
input_stream = nltk.word_tokenize(raw_input)
res = []
for word in input_stream[(len(input_stream)-seq_length):]:
res.append(w2v_model[word])
return res
def y_to_word(y):
word = w2v_model.most_similar(positive=y, topn=1)
return word
# ②
def generate_article(init, rounds=30):
in_string = init.lower()
for i in range(rounds):
n = y_to_word(predict_next(string_to_index(in_string)))
in_string += ' ' + n[0][0]
return in_string
# ③
init = 'Language Models allow us to measure how likely a sentence is, which is an important for Machine'
article = generate_article(init)
print(article)