人脸关键点检测总结
本文转载自博客,供自己学习
人脸关键点检测也称为人脸关键点检测、定位或者人脸对齐,是指给定人脸图像,定位出人脸面部的关键区域位置,包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓等。
人脸关键点检测方法大致分为三种:
- 基于模型的ASM(Active Shape Model)和AAM(Active Appearnce Model)
- 基于级联形状回归CPR(Cascaded pose regression)
- 基于深度学习的方法
ASM(Active Shape Model)算法
1. 概要
这是一种1995年提出的很老的关键点检测方法。ASM是基于特征点分布模型(Point Distribution Model,PDM)提取的一种方法。在PDM中,外形相似的物体,例如人脸、人手、心脏、肺部等的几何形状可以通过若干关键特征点(landmarks)的坐标依次串联形成一个形状向量来表示。
ASM跟大多数统计学习方法一样,也包括train和test两部分,也就是形状建模build和形状匹配fit。这个算法其实很简单,可以用来做实时性的检测。
步骤:
==人工标定训练集->对齐构建形状模型->搜索匹配==
2. 特征点标记
为了建立ASM,需要一组标有n个特征点的N幅人脸图象(包括多个人的不同表情和姿态)作为训练数据。特征点可以标记在脸的外部轮廓和器官的边缘,需要注意的是各个标定点的顺序在训练集中的各张照片需要一致。
得到特征点集,可以看做一个2n维的向量,n表示特征点数量:
3. 模型训练
1)对齐
为了研究训练图象的形状变化,比较不同形状中相对应的点,应先对这些图象进行对齐。
对齐是指以某个形状为基准,对其它形状进行旋转,缩放和平移使其尽可能的与基准形状接近的过程。
首先选择一幅基准图像。训练集中其他图片经过变换尽可能的接近该基准图像,具体的变化过程可以用一个缩放幅度参数s,旋转参数theta以及平移参数矩阵t表示。假设我们要将第2幅图像经过变换尽可能的接近第1幅图像,变换后的图像矩阵表示为:
2) 构建局部特征
对对齐后的形状特征做PCA处理。接着,为每个关键点构建局部特征。目的是在每次迭代搜索过程中每个关键点可以寻找新的位置。局部特征一般用梯度特征,以防光照变化。有的方法沿着边缘的法线方向提取,有的方法在关键点附近的矩形区域提取。
形状搜索
首先:计算眼睛(或者眼睛和嘴巴)的位置,做简单的尺度和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点(常采用马氏距离),得到初步形状;再用平均人脸(形状模型)修正匹配结果;迭代直到收敛。
优点:
1. 得到的特征点是有序;
2. 能根据训练数据对于参数的调节加以限制,从而将形状的改变限制在一个合理的范围内。
- 1
- 2
缺点:
1. 需要人工对特征点进行顺序标注,工作量超大;
2. 其近似于穷举搜索的关键点定位方式在一定程度上限制了其运算效率。
- 1
- 2
AAM(Active Appearance Models)算法
1. 概要
1998年,Cootes对ASM进行改进,不仅采用形状约束,而且又加入整个脸部区域的纹理特征,即:Appreance = Shape + Texture,提出了AAM算法。
AAM主动外观模型主要分为两个阶段,模型建立阶段和模型匹配阶段。其中模型建立阶段包括了对训练样本分别建立形状模型(Shape Model)和纹理模型(Texture Model),然后将两个模型进行结合,形成AAM模型。模型匹配阶段是指在视频序列中将已建立好的AAM模型在当前帧图像中寻找最匹配的目标的过程。

2. 样本选取与标定
1)要建立AAM模型,就需要采集目标的样本,建立样本库。
2)要建立关于人脸的AAM模型,就需要把目标从样本中提取出来而去除背景等的影响。而提取目标的方法就是在样本中手动把人脸的轮廓标定出来。
3)在手动标定了样本中的点后,通过程序把样本的点的位置{x,y}保存为向量的形式
3. 形状模型(shape model)
对输入数据首先建立活动形状模型ASM。建立ASM模型包括Procrustes变换和PCA降维两个步骤。Procrustes变换就是ASM中的对齐操作。样本和形状模型的建立步骤与ASM相同。
4. 纹理模型(Texture Model)
纹理模型(Texture Model)描述了目标的纹理特征。纹理模型的输入数据和形状模型一样,在这里可以看做是n张图片,每张图片上有一个点集。
1)Delaunay三角划分:将空间点连接为三角形,使得所有三角形中最小的角最大的一个技术。三角划分的要点是任何三角形的外接圆都不包括任何其他顶点,即外接圆性质。

2)三角映射:使用Delaunay三角划分后,每一个样本都可以划分为一系列三角形,而不同样本间这些三角形是对应的。要得到平均纹理模型,就需要把样本中的目标的纹理通过分片仿射投影到同一个样本上,而这种分片仿射就是三角映射。
先设定一个样本为平均脸,既然在样本中的点与平均脸的所有三角形都是一一对应的,就可以根据三角形中每一点的位置计算其对应平均脸中某一点的位置,然后把该点的像素值复制到平均脸对应点的位置上。最终每一个样本都可以转化到平均脸上,然后把这n个脸求平均,就得到了平均纹理模型。
5. 组合模型(Combine Model)
在得到形状模型和纹理模型后,我们就可以对这两个模型进行加权组合,得到组合模型,也就是AAM模型。同时我们也得到了p+q个参数,再降维得到r个参数,这些参数就是用来改变AAM模型的特征的。
6. 搜索模型(Search Model)
AAM模型建立以后,就可以实际在视频序列中跟踪人脸。
初始时记AAM模型的r个参数为向量,然后对输入的图像,首先假设某个位置有人脸,得到人脸的实际参数c,然后我们通过不断地调整使c和r之间的距离最小,若这个最小值小于某个阀值,就可以认为当前位置出现人脸,我们就能够在视频中检测到了人脸。
优点:
1. 与ASM相比有增加了纹理信息
2. 模型简单直接,架构清晰明确,易于理解和应用
- 1
- 2
缺点:
1. 需要人工对特征点进行顺序标注,工作量超大;
2. 对噪声非常敏感。
- 1
- 2
CPR(Cascaded pose regression)
1. 概要
2010年,Dollar提出CPR(Cascaded Pose Regression, 级联姿势回归),CPR通过一系列回归器将一个指定的初始预测值逐步细化,每一个回归器都依靠前一个回归器的输出来执行简单的图像操作,整个系统可自动的从训练样本中学习。
2. 回归器训练
人脸关键点检测的目的是估计向量,K表示关键点的个数,由于每个关键点有横纵两个坐标,所以S的长度为2K。
在每个阶段中首先进行特征提取,这里使用的是shape-indexed features,也可以使用诸如HOG、SIFT等人工设计的特征,或者其他可学习特征(learning based features)。
姿态θ训练过程是先初始化一个θ,然后提取特征,再用特征进行回归,再更新θ。

然后通过训练得到的回归器R来估计增量ΔS( update vector),把ΔS加到前一个阶段的S上得到新的S,这样通过不断的迭代即可以得到最终的S(shape)。加上训练R的损失函数:
作者用到的回归方法为Random Fern Regressors,这种算法思想类似于随机森林。级联回归器的训练过程为:

根据θ的不断更新,关键位置的预测结果如图
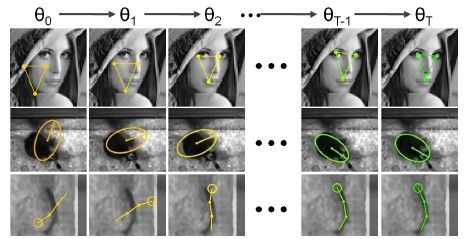
3. 姿势聚类
用不同的初始姿态θ训练级联分类器会得到不同的预测结果,有时候初始化姿态选的不合适就会导致错误预测。所以作者对每一个图像,初始化K个不同姿态,CPR运行K次得到K个不同结果。对这些结果进行聚类,选取密度最高的结果作为最终结果。
4. 人脸关键点
作者用了Caltech人脸数据集,对三个关键点即双眼和嘴巴进行位置预测。
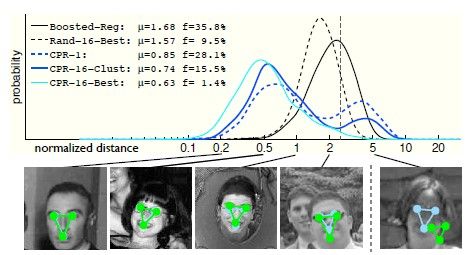
优点:
1. 算法思想类似于随机森林回归,是一种回归算法,结构清晰简单。
2. 可以用较少的训练数据训练出较好的模型、
- 1
- 2
缺点:
1. 只对人脸的3个关键点进行检查;
2. 特征提取方式很传统,且作者并没有明确说人脸回归方法预测的准确度。
- 1
- 2
Face Alignment at 3000 FPS via Regressing Local Binary Features(LBF)
1. 概要
CVPR14年的文章,这篇论文主要讲:Face Alignment 问题,即给人脸确定位置68个标点 (landmark)。而这些标点位置肯定是最能区别不同人的位置。
https://github.com/FaceDetect/jointCascade_py
https://github.com/FacialLandmark/landmark_py
2. 算法步骤
算法步骤可以分为三个过程:
1)提取特征(shape index feature)
2)LBF编码(learning local binary feature)
3)获取shape 增量(learning global linear regression)
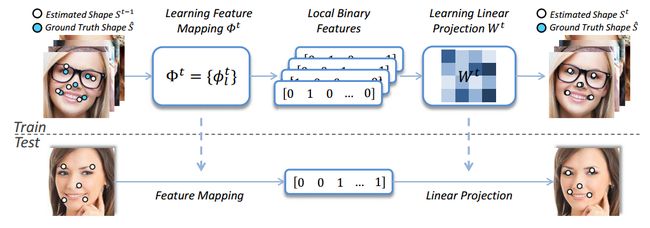
训练过程中,先初始化一个shape St-1,用一种特征映射方法Φt生成local binary features。根据特征和目标shape的增量生成最终shape。权值通过线性回归进行更新。在测试阶段,直接预测形状增量,并应用于更新当前估计的形状。形状增量:
3. 提取shape index feature
shape index feature 也就是特征和现有的一系列标定点是相关的,3000fps的做法是在landmark周围随机出两个偏移量,形成两个点,用这两个点的像素差作为特征。
刚开始的时候,shape和ground truth差距太大,因此需要取样特征的半径大一些,最后的shape和ground truth已经很接近了,半径要小一些。
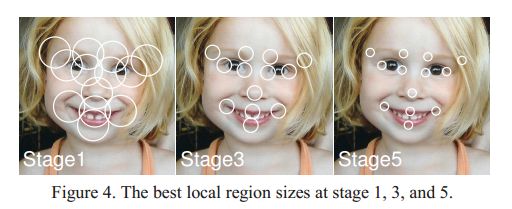
4. 学习local binary features
使用标准随机森林训练Φt
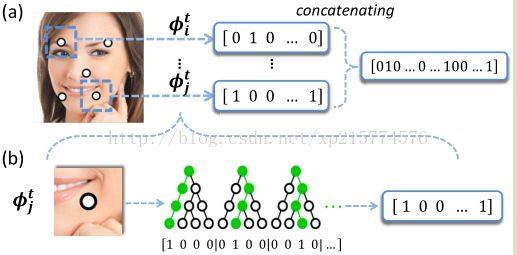
(b)所示是标点j用随机森林得到二进制特征,再串联成(a),组成全局特征,最后训练全局线性投影Wt.
随机森林的思想:随机是随机抽取n对像素,这n个像素就成为一个模板(template),以后一直不变。再比较每一对像素,第一个像素大于第二个就为1,第二个大于第一个就为0,再串联n对像素比较值,组成二进制向量就为随机森林特征。如图取的是到达叶子节点为1,道理一样(大于节点遍历左子节点,小于遍历右子节点).
5. 权值学习
使用的双坐标下降方法,使下公式最小:
λ是控制Wt长度,即让Wt尽量稀疏。
测试的时候,先对一幅图像提取shape index feature, 然后使用随机森林进行编码,最后使用w估计shape 增量。
优点:
1. 速度快,在笔记本上跑了3000FPS,智能手机是300FPS
2. 是最先进算法(the state of the art)有更高的精确性,做为人脸验证底层实现,实时性显然重要。
- 1
- 2
缺点:
1. 只对人脸的3个关键点进行检查;
2. 参数很难调。
- 1
- 2
Joint Cascade Face Detection and Alignment
1. 概要
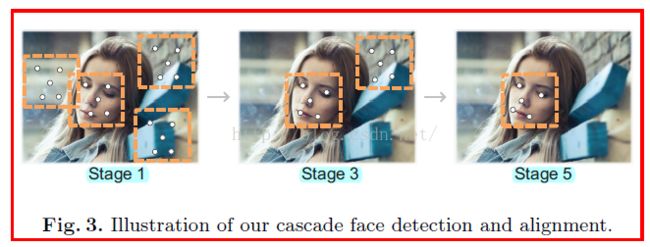
这篇是MSRA在14年发表在ECCV上的论文,这篇文章直接在30ms的时间里把detection和alignment都给做了,PR曲线彪到很高,时效性高,内存占用却非常低。这篇文章的思想继承了CPR,使用级联树+简单特征的结构,将分类与回归都完成,计算简单,高效。
文章的思想是训练一棵决策树同时做Face Alignment和Face Detection。
2. Post classifier
在人脸对齐前需要先将人脸检测出来。
1)样本准备:首先作者调用opencv的Viola-Jones分类器,将recall阀值设到99%,这样能够尽可能地检测出所有的脸,但是同时也会有非常多的不是脸的东东被检测出来。于是,检测出来的框框们被分成了两类:是脸和不是脸。这些图片被resize到96*96。
2)特征提取:接下来是特征提取,怎么提取呢?作者采用了三种方法:
第一种:把window划分成6*6个小windows,分别提取SIFT特征,然后连接着36个sift特征向量成为图像的特征。
第二种:先求出一个固定的脸的平均shape(27个特征点的位置,比如眼睛左边,嘴唇右边等等),然后以这27个特征点为中心提取sift特征,然后连接后作为特征。
第三种:用他们组去年的另一个成果Face Alignment at 3000 FPS via Regressing Local Binary Features (CVPR14) ,也就是图中的3000FPS方法,回归出每张脸的shape,然后再以每张脸自己的27个shape points为中心做sift,然后连接得到特征。
- 1
- 2
- 3
- 4
- 5
3)分类:将上述的三种特征分别扔到线性SVM中做分类,训练出一个能分辨一张图是不是脸的SVM模型。紧接着作者将以上三种方法做出的分类器和初始分类器进行比对,画了一个样本分布的图:

这个图从左到右依次是原始级联分类器得到的样本分类分布和第一种到第三种方法提取的特征得到的样本分类分布。可见做一下shape alignment可以得到一个更好的分类效果。但是效率很渣,recall 99%一张图可以检测出3000个框。
3. 级联分类器
和随机森林很相似,级联分类器就是一种bagging的思想。定义形状S为一个2L维的向量,L是标点总数。逐步回归的过程是:
每一个Rt是一个回归函数,它会在前一级形状的基础上增加一个形状增量。学习时使当前形状St与真实形状S之间的误差最小。
一个关键的创新点在于,在级联标点框架中,每一个回归器Rt依赖于前一个形状S(t-1),在训练学习的过程中,特征定义为与S(t-1)相关,所以称之为姿态/形状索引特征,这种特征对面部形状变化时,呈现出很好的几何不变性。
将这种姿态/形状索引特征同样的应用在检测环节,则文章统一两个训练学习任务,将分类器定义为:
这样的分类器相当于结合了形状标定S和分类检测C。算法过程

训练结果:
4. 实验效果
使用像素差作为特征使得高性能得到保证。算法在VGA图像(640*480pixel)上的检测性能是28.6ms/张。检测器只占用15MB内存。在FDDB数据集上。算法的Recall为80.07%。
优点:
1. 速度快,占用内存小。
2. 可以同时做人脸和人脸关键点检测
- 1
- 2
缺点:
1. 参数难调。
- 1
One Millisecond Face Alignment with an Ensemble of Regression Trees(ETR)
1. 概要
CVPR 2014的一篇关于人脸关键点检测的论文,基于Ensemble of Regression Tress算法(以下简称 ERT),速度极快(单人人脸关键点检测耗时约为1ms),效果也不错。同时又能处理训练集中部分关键点标定缺失的情况。LBF(Face Alignment at 3000 FPS via Regressing Local Binary Features)这篇论文的进阶版本。
2. 算法思想
LBF是基于Tree的方法,学习每个关键点的局部二值特征,然后将特征组合起来,使用线性回归检测关键点。与 LBF 不同的是, ERT 是在学习 Tree的过程中,直接将 shape 的更新值 ΔS存入叶子结点 leaf node. 初始位置 S 在通过所有学习到的 Tree后,mean shape 加上所有经过的叶子结点的ΔS,即可得到最终的人脸关键点位置。总体流程如下图所示:

公式表达是:
其中 t 表示级联序号,rt(∙,∙)表示当前级的回归器regressor。回归器的输入参数为图像 I 和上一级回归器更新后的 shape, 采用的特征可以是灰度值或者其它。
为了训练每一级的 rt,文章采用了 gradient tree boosting算法减小 initial shape 和 ground truth 的平方误差总和。
每个回归器由很多棵树(tree)组成,每棵树参数是根据 current shape 和 ground truth 的坐标差和随机挑选的像素对训练得到的。
优点:
1. 速度快,占用内存小;
2. 改进了参数难调的问题。
- 1
- 2
缺点:
1. 模型稍大(随机数算法的通病)。
- 1
Deep Convolutional Network Cascade for Facial Point Detection
1. 概要
2013年,Sun等人首次将CNN应用到人脸关键点检测,提出一种级联的CNN(拥有三个层级)——DCNN(Deep Convolutional Network),此种方法属于级联回归方法。作者通过设计拥有三个层级的级联卷积神经网络对面部5个关键点左眼、右眼、鼻子、嘴巴两侧进行检测。
https://github.com/zhaoyuzhi/Deep-Convolutional-Network-Cascade-for-Facial-Point-Detection
2. 整体结构
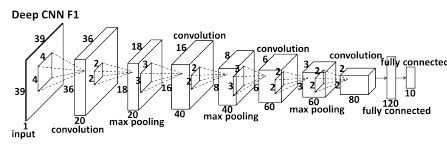
如图所示,DCNN由三个Level构成。Level-1 由3个CNN组成;Level-2由10个CNN组成(每个关键点采用两个CNN);Level-3同样由10个CNN组成。

1)Level-1分3个CNN,分别是F1(Face1)、EN1(Eye,Nose)、NM1(Nose,Mouth);F1输入尺寸为39*39,输出5个关键点的坐标;EN1输入尺寸为39*31,输出是3个关键点的坐标;NM11输入尺寸为39*31,输出是3个关键点。Level-1的输出是由三个CNN输出取平均得到。
2)Level-2,由10个CNN构成,输入尺寸均为15*15,每两个组成一对,一对CNN对一个关键点进行预测,预测结果同样是采取平均。
3)Level-3与Level-2一样,由10个CNN构成,输入尺寸均为15*15,每两个组成一对。Level-2和Level-3是对Level-1得到的粗定位进行微调,得到精细的关键点定位。
Level-1之所以比Level-2和Level-3的输入要大,是因为作者认为,由于人脸检测器的原因,边界框的相对位置可能会在大范围内变化,再加上面部姿态的变化,最终导致输入图像的多样性,因此在Level-1应该需要有足够大的输入尺寸。Level-1与Level-2和Level-3还有一点不同之处在于,Level-1采用的是局部权值共享(Locally Sharing Weights)
3. 网络结构
第一级的网络深度要深,
分析3个选择网络的重要因素。讨论集中在最难训练的第一级网络。
1)第一级的网络必须要深。从大的输入区域中预测关键点是一个高级任务。更深的结构有利于形成全局的高级特征,在低层,由于局部感受野,神经元提取的特征是局部的。通过结合空间上相邻的低层特征,高层的神经元能从更大的区域提取特征。此外,高层的特征是高度非线性的,增加额外的层增强了从输入到输出的非线性,更有可能代表输入和输出的关系。
2)第二,对卷积层上的神经元,在双曲正切激活函数后的绝对值校正(下一章)能有效提高效果。
3)第三,局部地共享权值有利于更好的表现。
多级回归
由于脸部检测器的不稳定性和姿态的多样性。所以第一级的输入区域应该是足够大来覆盖所有可能的预测。但大的输入区域是主要的不准确原因,因为不相关的区域可能退化网络最后的输出。
第一级的网络输出为接下来的检测提供了一个强大的先验知识。真实的脸部点伪装分布在第一级预测的一个小领域内。所以第二级的检测可以在一个小范围内完成。但没有上下文信息,局部区域的表现是不可靠的。为了避免发散,我们不能级联太多层,或者过多信任接下来的层。这些网络只能在一个小范围内调整初始预测。
为了更好的提高检测精度和可靠性,作者提出了每一级都有多个网络共同地预测每一个点。这些网络的不同在于输入区域。最后的预测可以用公式表达如下:
优点:
1. 改善初始不当导致陷入局部最优的问题;
2. 借助于CNN强大的特征提取能力,获得更为精准的关键点检测。
- 1
- 2
缺点:
1. 只有5个关键点检测
2. 3.3GHz的CPU单张图片检测速度0.12s,网络结构复杂。
- 1
- 2
Extensive Facial Landmark Localization with Coarse-to-Fine Convolutional Network Cascade
这篇是ICCV2013年face++在DCNN模型上改进提出的从粗到精的人脸关键点检测算法。实现了68个人脸关键点的高精度定位。该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。
整体结构
网络采用四级级联结构,与上一篇文章相似。本篇最大的创新点在于:在网络的输入方面,不是用人脸检测器检测到的人脸区域图片作为网络的输入,而是采用CNN预测人脸的bounding box,这个改进对初始level定位精度提高非常多。

1)Level-1主要作用是获得面部器官的边界框,上面是inner的bounding box,下面是contour的bounding box;
2)Level-2的输出是51个关键点预测位置,这里起到一个粗定位作用,目的是为了给Level-3进行初始化;
3)Level-3会依据不同器官进行从粗到精的定位;
4)Level-4的输入是将Level-3输出的inner point进行一定的旋转,最终将51个关键点的位置进行输出。
针对外部17个关键点contour point,仅采用两个层级的级联网络进行检测。
网络结构
N1表示为inner point各个特征点的初始位置预测,也就是相当于inner 的level 2。

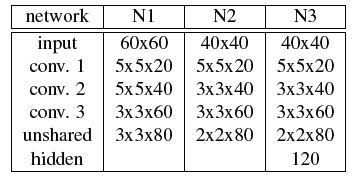
网络结构方面基本上与传统的CNN模型,差不多,最大的区别在于locally sharing weights,也就是上面的unshared conv层,我们平时所遇到的CNN都是global sharing weights的。但是对于特征点的预测,五官的高层特征差别比较大,所以需要在高层采用unshared weight的方式,在低层采用global sharing weights。
优点:
1. 把人脸的关键点定位问题,划分为内部关键点和轮廓关键点分开预测,有效的避免了loss不均衡问题;
2. 内部关键点检测部分,并未像DCNN那样每个关键点采用两个CNN进行预测,而是每个器官采用一个CNN进行预测,从而减少计算量。
- 1
- 2
缺点:
1. 模型多,运算复杂。
- 1
Facial Landmark Detection by Deep Multi-task Learning(TCDCN)
1. 概述
这篇文章发表于ECCV2014,来自香港中文大学汤晓鸥课题组。
文章提出了人脸特征点检测的新方法,使用与人脸相关的属性共同学习人脸的特征点位置。具体而言,就是在人脸特征点检测的时候,同时进行多个任务的学习,这些任务包括:性别,是否带眼镜,是否微笑和脸部的姿势。使用这些辅助的属性帮助更好的定位特征点,根据论文结果,这样的确对人脸特征点检测有一定的帮助。
这种Multi-task learning的困难在于:不同的任务有不同的特点,不同的收敛速度。针对这两个问题,文章给出前者的解决办法是tasks-constrained deep model,对后者解决办法是task-wise early stopping。文章中的方法在处理有遮挡和姿势变化时表现较好,而且模型比较简单。

https://github.com/zhzhanp/TCDCN-face-alignment
https://github.com/flyingzhao/tfTCDCN
2. 多任务检测模型
传统的多任务学习(multi-task learning)把每个任务都赋予相同的权重:
从这个式子可以看到,损失函数的前部分就是特征点检测,后部分是不同的分类任务loss相加,最后一项是正则项。在训练时,各个任务使用相同的特征,只有在最后一级才根据任务的不同做不同处理(线性回归或者分类)。
3. 网络结构
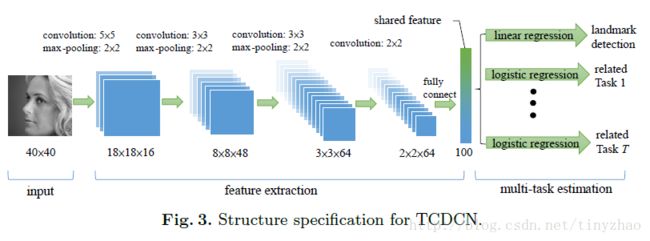
输入图片为40*40的黑白图片,然后经过4个卷积层变成2*2*64的图像,其中激活函数采用|tanh|,即对tanh取绝对值。在最后的全连接层将2*2*64的多层结构变成100个shared feature,以上部分都可以看成特征提取的操作。在最后一层由这些特征进行不同操作,对特征点检测问题就是linear regression,对于其他分类问题就是logistic regression(softmax)。
4. Task-wise early stopping
针对多任务学习的特点,本文提出了一种新的early stopping方法。当辅助任务达到最好表现以后,这个任务就对主要任务没有帮助了,就可以停止这个任务。如下式所示,Eaval是任务a的验证集loss,Eatr是训练集loss,如果下面式子超过了某个阈值ϵ就会停止这个任务。
优点:
1. 采用多任务学习方法对人脸关键点进行检测;
2. 对比于级联CNN方法,在Intel Core i5 cpu上,级联CNN需要0.12s,而TCDCN仅需要17ms,速度提升七倍有余。
- 1
- 2
缺点:
1. 论文中很很多超参数需要调整。
- 1
Multi-task Cascaded Convolutional Networks(MTCNN)
1. 概述
2016年,Zhang等人提出一种多任务级联卷积神经网络(MTCNN, Multi-task Cascaded Convolutional Networks)用以同时处理人脸检测和人脸关键点定位问题。作者认为人脸检测和人脸关键点检测两个任务之间往往存在着潜在的联系,然而大多数方法都未将两个任务有效的结合起来,本文为了充分利用两任务之间潜在的联系,提出一种多任务级联的人脸检测框架,将人脸检测和人脸关键点检测同时进行。
https://github.com/xiangrufan/keras-mtcnn
2. 网络结构
MTCNN包含三个级联的多任务卷积神经网络,分别是Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。网络结构如图所示:

TCNN实现人脸检测和关键点定位分为三个阶段。
1)第一阶段,通过一个浅层的CNN快速生成候选窗口。该阶段是一个全部由卷积层组成的CNN,取名P-Net,获取候选人脸窗口以及人脸框回归向量。基于人脸框回归向量对候选窗口进行校正。之后采用NMS合并高重叠率的候选窗口。

2)第二阶段,通过一个更复杂的CNN否决大量非人脸窗口从而精化人脸窗口。第一阶段输出的候选窗口作为R-Net的输入,R-Net能够进一步筛除大量错误的候选窗口,再利用人脸框回归向量对候选窗口做校正,并执行NMS。
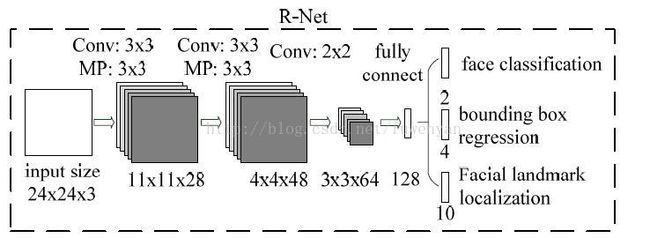
3)使用更复杂的CNN进一步精化结果并输出5个人脸特征点。与stage2相似,但这一阶段用更多的监督来识别人脸区域,而且网络能够输出五个人脸特征点位置坐标。

3. 训练阶段
在具体训练过程中,作者就多任务学习的损失函数计算方式进行相应改进。在多任务学习中,当不同类型的训练图像输入到网络时,有些任务时是不进行学习的,因此相应的损失应为0。例如,当训练图像为背景(Non-face)时,边界框和关键点的loss应为0,文中提供计算公式自动确定loss的选取,公式为:
其中, αj表示任务的重要程度,在P-Net和R-Net中,αdet=1,αbox=0.5,αlandmark=0.5 ,在O-Net中,由于要对关键点进行检测,所以相应的增大任务的重要性,αdet=1,αbox=0.5 , αlandmark=1 。 作为样本类型指示器。
实验结果表明,MTCNN在人脸检测数据集FDDB 和WIDER FACE以及人脸关键点定位数据集LFPW均获得当时最佳成绩。在运行时间方面,采用2.60GHz的CPU可以达到16fps,采用Nvidia Titan Black可达99fps
优点:
1. 采用CNN方法同时预测人脸和人脸关键点;
2. 对于速度和精度都有一定的提升。
- 1
- 2
缺点:
1. 网络结构较复杂。
- 1
Facial Landmark Detection with Tweaked Convolutional Neural Networks(TCNN)
1. 概述
2016年,Wu等人研究了CNN在人脸关键点定位任务中到底学习到的是什么样的特征,在采用GMM(Gaussian Mixture Model, 混合高斯模型)对不同层的特征进行聚类分析,发现网络进行的是层次的,由粗到精的特征定位,越深层提取到的特征越能反应出人脸关键点的位置。针对这一发现,提出了TCNN(Tweaked Convolutional Neural Networks)。
https://github.com/flyingzhao/mxnet_VanillaCNN
2. 网络结构
其网络结构如图所示:

图为Vanilla CNN,针对FC5得到的特征进行K个类别聚类,将训练图像按照所分类别进行划分,用以训练所对应的FC6K 。测试时,图片首先经过Vanilla CNN提取特征,即FC5的输出。将FC5输出的特征与K个聚类中心进行比较,将FC5输出的特征划分至相应的类别中,然后选择与之相应的FC6进行连接,最终得到输出。
3. 特征聚类
作者对Vanilla CNN中间各层特征进行聚类分析,并统计出关键点在各层之间的变化程度,如图所示:
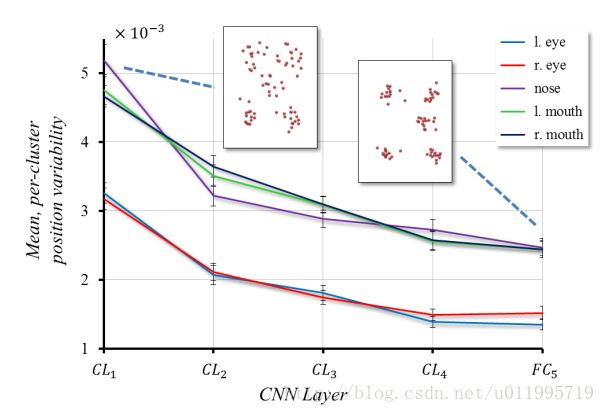
从图中可知,越深层提取到的特征越紧密,因此越深层提取到的特征越能反应出人脸关键点的位置。作者在采用K=64时,对所划分簇的样本进行平均后绘图如下:

从图上可发现,每一个簇的样本反应了头部的某种姿态,甚至出现了表情和性别的差异。因此可推知,人脸关键点的位置常常和人脸的属性相关联。因此为了得到更准确的关键点定位,作者使用具有相似特征的图片训练对应的回归器。网络结构修改为FC5不同的类别对应不同的FC6。FC6用回归的方法对人脸的5个关键点进行检测。

优点:
1. 对CNN提取的特征进行聚类,将各簇对应的样本进行分析,最后发现同一簇表现出“相同属性”(姿态,微笑,性别)的人脸。对此,设计了K个FC5和K个FC6层,用以对不同“面部属性”的人脸进行关键点检测。
- 1
缺点:
1. TCNN相当于按照姿态的不同,细分了K个“子模型”,只不过K个“子模型”共用卷积层用以提取特征,然后对应的有自己的FC5,FC6层。感觉这个模型的鲁棒性和泛化性不太好。
- 1
DAN-Deep Alignment Network: A convolutional neural network for robust face alignment
1. 概述
DAN-Deep Alignment Network,发表于CVPR-2017。以往级联神经网络输入的是图像的某一部分,与以往不同,DAN各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以DAN能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的主要创新点。
https://github.com/MarekKowalski/DeepAlignmentNetwork
2. 网络结构
DAN基本框架如图所示:
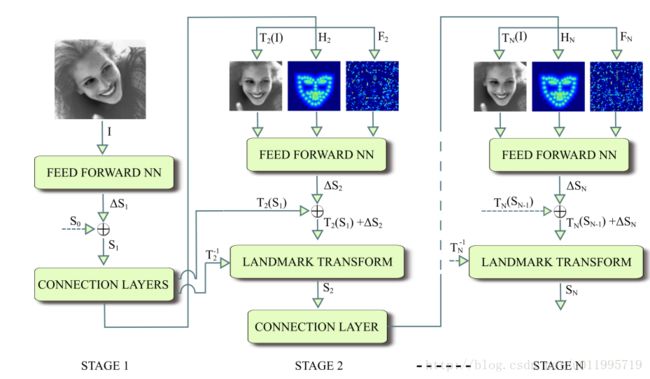
DAN包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(Face Shape)。其中,CONNECTION LAYER的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示:

第一阶段的输入仅有原始图片和S0。面部关键点的初始化即为S0,S0是由所有关键点取平均得到,第一阶段输出S1。对于第二阶段,首先,S1经第一阶段的CONNECTION LAYERS进行转换,分别得到转换后图片T2(I)、S1所对应的热图H2和第一阶段fc1层输出,这三个正是第二阶段的输入。如此周而复始,直到最后一个阶段输出SN。文中给出在数据集IBUG上,经过第一阶段后的T2(I)、T2(S1)和特征图,如图所示:

3. 前馈神经网络
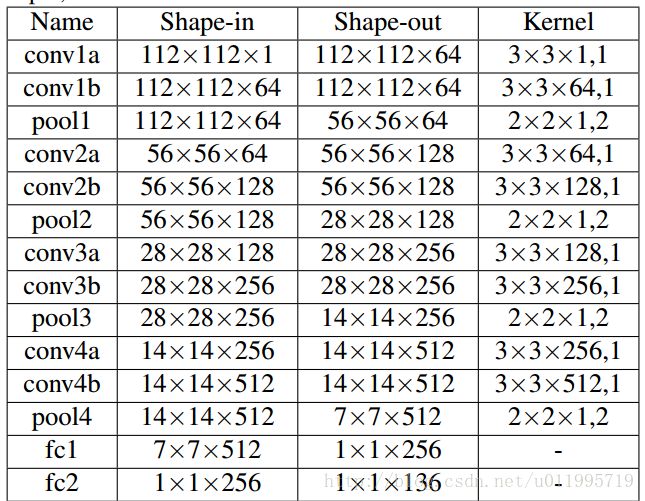
前馈神经网络的网络结构如图,其输出为landmark的偏移量,这里与以往用回归方法求偏移不同,这里用神经网络输出计算shape的偏移。
DAN要做的“变换”,就是把图片给矫正了,DAN对姿态变换具有很好的适应能力,或许就得益于这个“变换”。St是如何由St-1以及该阶段CNN得到,先看St计算公式:
该CNN的输入均是经过了“变换”Tt的操作,因此得到的偏移量 ΔSt是在新特征空间下的偏移量,在经过偏移之后应经过一个反变换T−1t 还原到原始空间。而这里提到的新特征空间,或许是将图像进行了“矫正”,使得网络更好的处理图像。
4. Landmark热力图
关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,公式如下:
优点:
1. DAN是一个级联思想的关键点检测方法;
2. 通过引入关键点热图作为补充,DAN可以从整张图片进行提取特征,从而获得更为精确的定位。
- 1
- 2
缺点:
1. 网络结构很复杂,还需要计算heatmap;
2. 在1070 GPU上单张图片检测为73fps,连续图片检测为45fps。
- 1
- 2
How far are we from solving the 2D & 3D Face Alignment problem?
概述
ICCV 2017的论文,结合最先进的人脸特征点定位(landmark localization)架构和最先进的残差模块(residual block),首次构建了一个非常强大的基准,在一个超大2D人脸特征点数据集(facial landmark dataset)上训练,并在所有其他人脸特征点数据集上进行评估。
https://github.com/1adrianb/face-alignment
2D-FAN结构
通过堆叠四个HG(HourGlass)构建的人脸对齐网络(Face Alignment Network, FAN),其中所有的 bottleneck blocks(图中矩形块)被替换为新的分层、并行和多尺度block。
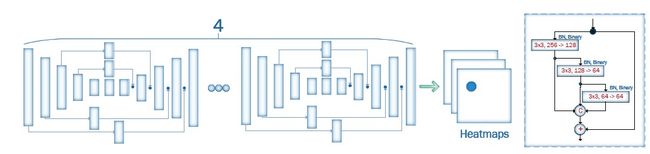
本质上来说就是一个小卷积网络的4层堆叠来预测人脸。输入2D图片,输出2D图片的Heatmap。
2D 检测结果:

2D-to-3D-FAN网络架构
文章首先构建人脸对齐网络“FAN”(Face Alignment Network),然后基于FAN,构建2D-to-3D-FAN,也即将给定图像2D面部标注转换为3D的网络。文章表示,据测试所知,在大规模2D/3D人脸对齐实验中训练且评估FAN这样强大的网络,还尚属首次。
基于人体姿态估计架构HourGlass,输入是RGB图像和2D图片的heatmaps,输出是对应的3D Heatmaps。
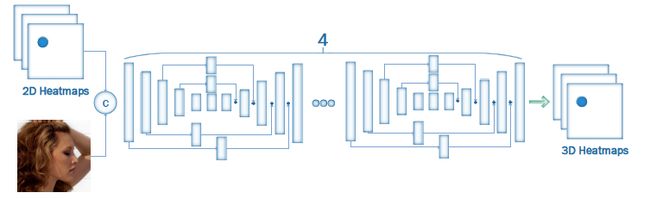
3D检测结果:

优点:
1. 提出了一种新的FAN网络结构来预测人脸关键点;
2. 实现了2D到3D关键点的一种转换。
- 1
- 2
缺点:
1. 3D的检测结果还是不够准确;
2. 文章工作还包括标注3D数据集,所以技术细节提及不多。
- 1
- 2
OpenFace: A general-purpose face recognition library with mobile applications
1. 概述
OpenFace是很热门的人脸检测和人脸对齐开源库,这个pipeline可以看做是使用深度卷积网络处理人脸问题的一个基本框架,她结合了Dlib和传统的决策树人脸对齐方法。
https://github.com/cmusatyalab/openface
2. 基本结构
它的结构如下图所示:

1)Input Image -> Detect
输入:原始的可能含有人脸的图像。
输出:人脸位置的bounding box。
这一步一般我们称之为“人脸检测”(Face Detection),在OpenFace中,使用的是dlib、OpenCV现有的人脸检测方法。此方法与深度学习无关,使用的特征是传统计算机视觉中的方法(一般是Hog、Haar等特征)。
2)Detect -> Transform -> Crop
输入:原始图像 + 人脸位置bounding box
输出:“校准”过的只含有人脸的图像
对于输入的原始图像 + bounding box,这一步要做的事情就是要检测人脸中的关键点,然后根据这些关键点对人脸做对齐校准。所谓关键点,就是下图所示的绿色的点,通常是眼角的位置、鼻子的位置、脸的轮廓点等等。有了这些关键点后,我们就可以把人脸“校准”,或者说是“对齐”。解释就是原先人脸可能比较歪,这里根据关键点,使用仿射变换将人脸统一“摆正”,尽量去消除姿势不同带来的误差。这一步我们一般叫Face Alignment。

在OpenFace中,这一步同样使用的是传统方法,特点是比较快,对应的论文是: 《One Millisecond Face Alignment with an Ensemble of Regression Trees》
3)Crop -> Representation
输入:校准后的单张人脸图像
输出:一个向量表示。
这一步就是使用深度卷积网络,将输入的人脸图像,转换成一个向量的表示。在OpenFace中使用的向量是128x1的,也就是一个128维的向量。
优点:
1. openface相当于是做了一个整合,把人脸检测,人脸对齐方法结合了一下。
2. 前面的检测和对齐用到的是传统方法,所以速度比较快。
- 1
- 2
缺点:
1. 只是做了整合,神经网络实际只是用于后续的人脸分类。
- 1