赫拉(hera)分布式任务调度系统之架构,基本功能(一)
文章目录
- 为数据平台打造的任务调度系统
- 全部文章
- 前言
- 架构
- 设计目标
- 支持任务的定时调度、依赖调度、手动调度、手动恢复
- 支持丰富的任务类型:shell,hive,python,spark-sql,java
- 可视化的任务DAG图展示,任务的执行严格按照任务的依赖关系执行& 某个任务的上、下游执行状况查看,通过任务依赖图可以清楚的判断当前任务为何还未执行,删除该任务会影响那些任务。
- 支持上传文件到hdfs,支持使用hdfs文件资源
- 支持日志的实时滚动
- 支持任务失败自动恢复
- 实现集群HA,机器宕机环境实现机器断线重连与心跳恢复与hera集群HA,节点单点故障环境下任务自动恢复,master断开,work抢占master
- 支持master/work 负载,内存,进程,cpu信息的可视化查看
- 支持正在等待执行的任务,每个work上正在执行的任务信息的可视化查看
- 支持实时运行的任务,失败任务,成功任务,任务耗时top10的可视化查看 & 支持历史执行任务信息的折线图查看 具体到某天的总运行次数,总失败次数,总成功次数,总任务数,总失败任务数,总成功任务数
- 支持关注自己的任务,自动调度执行失败时会向负责人发送邮件
- 组下任务总览、组下任务失败、组下任务正在运行
- 其它
- 关于hera开源
- 加入群聊
为数据平台打造的任务调度系统
全部文章
赫拉(hera)分布式任务调度系统之架构,基本功能(一)
赫拉(hera)分布式任务调度系统之项目启动(二)
赫拉(hera)分布式任务调度系统之开发中心(三)
赫拉(hera)分布式任务调度系统之版本(四)
赫拉(hera)分布式任务调度系统之Q&A(五)
前言
在大数据平台,随着业务发展,每天承载着成千上万的ETL任务调度,这些任务集中在hive,shell脚本调度。怎么样让大量的ETL任务准确的完成调度而不出现问题,甚至在任务调度执行中出现错误的情况下,任务能够完成自我恢复甚至执行错误告警与完整的日志查询。hera任务调度系统就是在这种背景下衍生的一款分布式调度系统。随着hera集群动态扩展,可以承载成千上万的任务调度。它是一款原生的分布式任务调度,可以快速的添加部署wokrer节点,动态扩展集群规模。支持shell,hive,spark脚本调度,可以动态的扩展支持python等服务器端脚本调度。
hera分布式任务调度系统是根据前阿里开源调度系统(
zeus)进行的二次开发,其中zeus大概在2014年开源,开源后却并未进行维护。我公司(二维火)2015年引进了zeus任务调度系统,一直使用至今年11月份,在我们部门乃至整个公司发挥着不可替代的作用。在我使用zeus的这一年多,不得不承认它的强大,只要集群规模于配置适度,他可以承担数万乃至十万甚至更高的数量级的任务调度。但是由于zeus代码是未维护的,前端更是使用GWT技术,难于在zeus上面进行维护。我与另外一个小伙伴(花名:凌霄,现在阿里淘宝部门)于今年三月份开始重写zeus,改名赫拉(hera)
项目地址:[email protected]:dfire/hera.git
https://github.com/scxwhite/hera
架构
hera系统只是负责调度以及辅助的系统,具体的计算还是要落在hadoop、hive、yarn、spark等集群中去。所以此时又一个硬性要求,如果要执行hadoop,hive,spark等任务,我们的hera系统的worker一定要部署在这些集群某些机器之上。如果仅仅是shell,那么也至少需要linux系统。对于windows系统,可以把自己作为master进行调试。

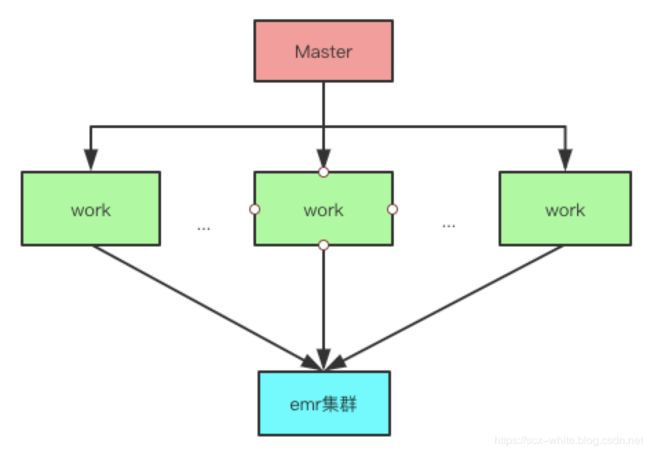
hera 在 2.4 版本以上也支持了emr 集群,即允许任务执行在阿里云、亚马逊的 emr 机器之上,架构图如下:
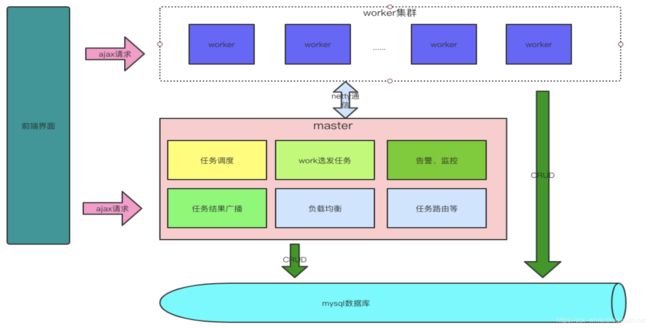
hera系统本身严格的遵从主从架构模式,由主节点充当着任务调度触发与任务分发器,从节点作为具体的任务执行器.架构图如下:
设计目标
hera分布式任务调度系统的设计目标首先是要完成zeus大部分核心功能,并能够根据自己公司的需求进行扩展。大致目标有以下几点
- 支持任务的定时调度、依赖调度、手动调度、手动恢复
- 支持丰富的任务类型:
shell,hive,python,spark-sql,java - 可视化的任务
DAG图展示,任务的执行严格按照任务的依赖关系执行 - 某个任务的上、下游执行状况查看,通过任务依赖图可以清楚的判断当前任务为何还未执行,删除该任务会影响那些任务。
- 支持上传文件到
hdfs,支持使用hdfs文件资源 - 支持日志的实时滚动
- 支持任务失败自动恢复
- 实现集群HA,机器宕机环境实现机器断线重连与心跳恢复与
hera集群HA,节点单点故障环境下任务自动恢复,master断开,worker抢占master - 支持对
master/work负载,内存,进程,cpu信息的可视化查看 - 支持正在等待执行的任务,每个
worker上正在执行的任务信息的可视化查看 - 支持实时运行的任务,失败任务,成功任务,任务耗时
top10的可视化查看 - 支持历史执行任务信息的折线图查看 具体到某天的总运行次数,总失败次数,总成功次数,总任务数,总失败任务数,总成功任务数
- 支持关注自己的任务,自动调度执行失败时会向负责人发送邮件
- 对外提供
API,开放系统任务调度触发接口,便于对接其它需要使用hera的系统 - 组下任务总览、组下任务失败、组下任务正在运行
- 支持
map-reduce任务和yarn任务的实时取消。 - 支持任务超时提醒
- 支持用户与组的概念
- 支持任务操作历史记录查看与恢复
- 支持任务告警定位到个人
- 告警类型支持邮箱以及自定义的钉钉、企业微信、短信、电话等
- 支持任务各种条件的模糊搜索
- 支持阿里云emr的自动创建、销毁
- 支持亚马逊emr的自动创建、销毁、弹性伸缩
- (还有更多,等待大家探索)
支持任务的定时调度、依赖调度、手动调度、手动恢复
- 定时调度
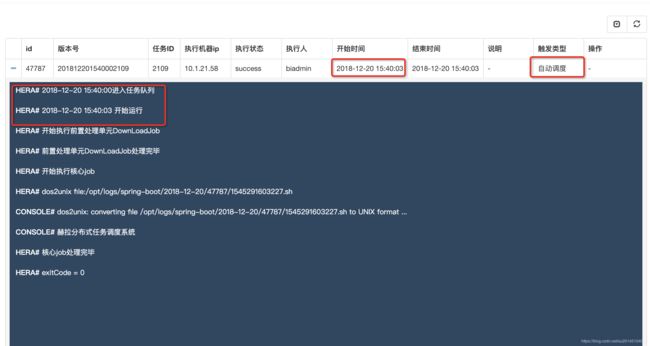
主要是根据cron表达式来解析该任务的执行时间,在达到触发时间时将该任务加入任务队列
为了进行测试我新建了一个shell任务 在15:40执行 ,在配置项里输入我们自己的配置,在脚本中使用${}进行替换,其中的继承配置项,即任务继承的所在组的配置信息,如果有重复以最近的为准
当任务达到时间开始执行,输出我们想要的结果:赫然分布式任务调度系统
- 依赖调度
我们的任务大部分都有依赖关系,只有在上一个任务计算出结果后才能进行下一步的执行。我们的依赖任务会在所有的依赖任务都执行完成之后才会被触发加入任务队列
贴一个已有的任务执行信息

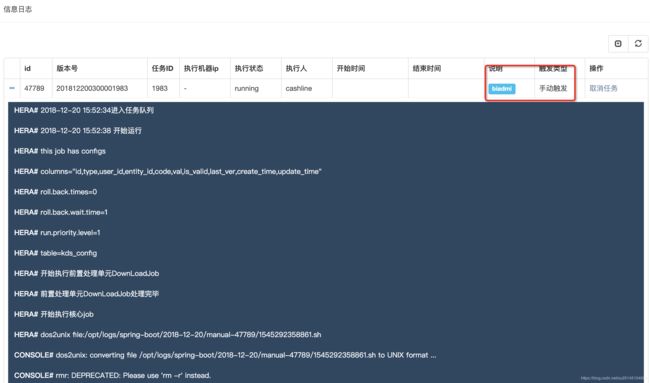
- 手动调度
手动调度即为手动执行的任务,手动执行后自动加入任务队列,请注意,手动任务执行成功后不会通知下游任务(即:依赖于该任务的任务)该任务已经执行完成
- 手动恢复
手动恢复类似于手动调度,于手动调度的区别为此时如果该任务执行成功,会通知下游任务该任务已经执行完成
支持丰富的任务类型:shell,hive,python,spark-sql,java
hera分布式任务调度系统依赖于jdk原生的ProcessBuilder 通过该工具向work/master以shell命令的方式执行任务。
比如python任务
我们可以首先写一个python脚本hello.py(这里随便贴个图片),然后把该脚本上传到hdfs
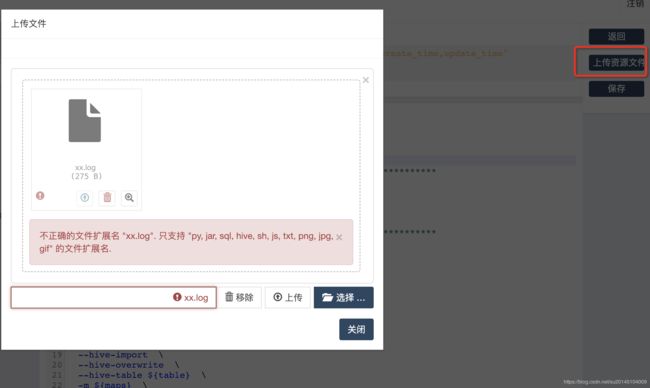
在执行的时候我们可以通过
download[hdfs:///hera/hello.py hello.py];
python hello.py;
来执行该脚本
这样一个完整的pyhton脚本就能通过方式实现shell方式调用执行,通过hera内部实现的job执行封装,脚本的文法解析,实现pyhton任务执行。实际上,通过这种方式甚至可以实现java,scala,hive-udf等服务器端语言的脚本任务执行。
- hive spark-sql 脚本的执行
对于hive脚本和spark-sql脚本 都是通过-f 命令来执行一个文件
可视化的任务DAG图展示,任务的执行严格按照任务的依赖关系执行& 某个任务的上、下游执行状况查看,通过任务依赖图可以清楚的判断当前任务为何还未执行,删除该任务会影响那些任务。
当任务数量过多,依赖错综复杂时就需要一个DAG图来查看任务之间的关系。

黄色表示正在执行,灰色表示关闭的任务,红色表示失败的任务,绿色表示执行成功的任务。右侧会显示该任务的详细信息。
当然在这里既支持全部查看也支持点击查看,当点击某个任务时会展示出依赖这个任务的所有任务。
支持上传文件到hdfs,支持使用hdfs文件资源
这个在上面 的 支持丰富的任务类型:shell,hive,python,spark-sql,java 已经说过,不再赘述。
支持日志的实时滚动
当执行任务时,可以通过查看日志的方式查看实时滚动的日志
支持任务失败自动恢复
当然,某些情况下任务可能会失败,比如网络闪断,可能下一秒就好了。建议对于非常重要的任务一定要开启任务失败重试,设置自定义的重试次数于重试时间间隔,设置后master会根据配置进行失败任务重试调度。
比如设置重试次数3,重试间隔10分钟
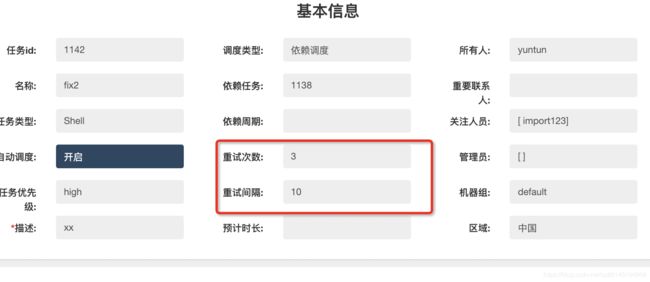
任务在执行失败后进行三次重试,可以看上次失败的结束时间与开始时间间隔为10分钟。

实现集群HA,机器宕机环境实现机器断线重连与心跳恢复与hera集群HA,节点单点故障环境下任务自动恢复,master断开,work抢占master
构建分布式系统,无法避免的就是需要做集群容灾。在出现服务器宕机与网络闪断的情况下要做到集群实现自动通信恢复,在此基础上,要做到实现任务在通信恢复后任务重新恢复执行等。
这个就无法展示了,等待大家以后去体验。
支持master/work 负载,内存,进程,cpu信息的可视化查看

这里可以看机器的用户cpu占用百分比,系统cpu占用百分比,cpu空闲,进行信息 等等。。
支持正在等待执行的任务,每个work上正在执行的任务信息的可视化查看
首先上图
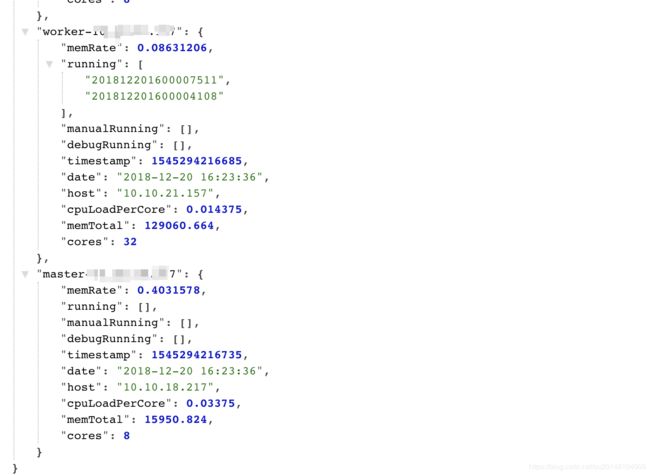
哈哈,有点简陋,只是提供了api接口,无奈没前端,现在就我一个人在开发。等吧。
里面的信息有机器内存使用百分比,平均每个核的负载,机器总内存,统计的时间。其中有三个队列,分别是running,manualRunning,debugRunning 在master开头的机器上表示等待执行的任务,在work开头的机器上表示正在执行的任务。分别对应自动调度&依赖任务 、手动执行任务、开发任务(另外一个开发界面)
支持实时运行的任务,失败任务,成功任务,任务耗时top10的可视化查看 & 支持历史执行任务信息的折线图查看 具体到某天的总运行次数,总失败次数,总成功次数,总任务数,总失败任务数,总成功任务数
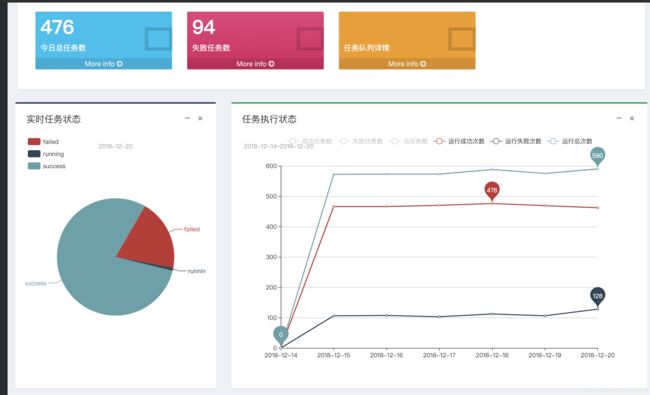
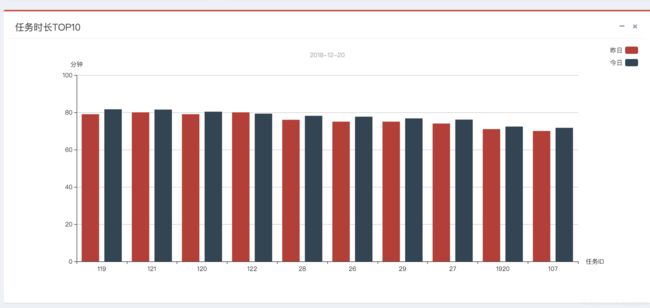
其中饼图可以通过点击进去查看具体的详细任务信息

支持关注自己的任务,自动调度执行失败时会向负责人发送邮件
当我们需要关注某些任务时可以通过关注任务来接收任务失败的信息

组下任务总览、组下任务失败、组下任务正在运行
虽然在首页我们看到失败的任务,但是有时候我们并不想关注别人的任务。我们就可以通过创建属于我们自己的组,然后在组下创建任务。这时候就可以通过组下任务预览来查看任务状态
比如点了任务总览
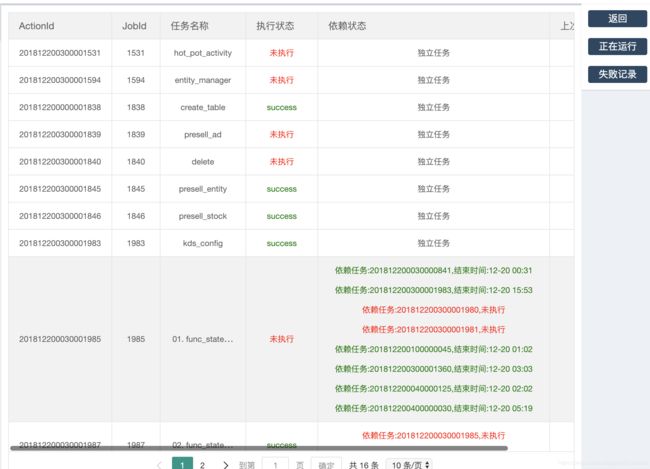
此时可以看到任务的所有信息,无论是执行,未执行,执行失败,执行成功还是运行中,如果任务未执行还会提示某些依赖任务未执行,如果依赖任务执行,
会展示任务的执行时间等等。右侧还可以再对内容进行筛选,比如查看失败,运行的任务。
其它
其实我们也做了许多其它功能,删除任务判断是否有任务依赖,关闭任务是否有任务依赖等。之外我们也做了hive sql血缘解析,字段解析,任务执行日志解析等等,由于在其它项目上面,后面会考虑继承到hera里面。
关于hera开源
准备在12月开源吧。最近把项目整理整理。
附上凌霄的博客地址:https://blog.csdn.net/pengjx2014/article/details/81276874
以上所有信息均为线下测试信息
加入群聊
微信交流群

个人微信(失效加我拉你进去)

公众号
