FPGA从入门到精通(3) - DRAM
所使用EDA软件:VIVADO2019.1.3
FPGA型号:xc7a35tcsg325-2
看完这篇文章你将收获以下内容:
- 理解SLICEL,SLICEM最本质的区别。
- 理解什么是单端口DRAM,双端口DRAM,简单双端口DRAM,以及四端口DRAM,SRL。
- 通过对比调用DRAM 原语/IP产生DRAM的结果与直接运用Verilog来产生RAM的结果来加深DRAM的认识。
- 通过对比调用SRL原语/IP产生DRAM的结果与直接运用Verilog reg来产生RAM的结果来加深DRAM的认识。
好的进入正题,今天我来带大家认识LUT的另一种形态,DRAM(Distributed RAM,翻译为分布式随机存储器,而不是我们平时看到的动态随机存储器)。在上一节课中,我们讲到LUT6可以用作64bit的ROM(Read Only Memory),ROM里面的内容是只读的,因此它里面的内容在我们将bit文件烧录到FPGA中就已经确定好的了,无法修改。
有没有方法将LUT6里面的内容修改呢,有在XILINX 7系中,有两种SLICE。分别为SLICEL,和SLICEM。SLICEM 除了具备完整的SLICEL功能之外,它还具有写存储数据功能。结构决定功能,那么SLICEM与SLICEL是结构上存在哪些不同,我们通过图1进行对比一下。我们可以看到,两者只有红框里的LUT6是不同的,其他结构完全一样。
 图一:左边为SLICEM,右边为SLICEL
图一:左边为SLICEM,右边为SLICEL
接下来我们分别将两者的LUT6结构放大进行进一步对比。两者的LUT6相同点和不同点如下:
相同点:都具有地址输入线(A1-A6),两个输出口(O5-O6)。
不同点:SLICEM的LUT6具有写地址输入线(WA1-WA8),写数据端(DI1 DI2),写使能端(WE),而SLICEL的LUT6没有。
因此SLICEM的LUT6可以读写存储数据,而SLICEL的LUT6只能读数据不能写。这就是为什么SLICEM的LUT6可以做RAM,而SLICEL的LUT6只能做ROM。
 图2:左为SLICEM的LUT6,右为SLICEL的LUT6
图2:左为SLICEM的LUT6,右为SLICEL的LUT6
从图1 中我们可以看到,1个SLICEM中有4个LUT6,它们可以单独使用或者组合使用来形成多种形态的DRAM。如:
- 32 x1 或 64x1的单端口DRAM (占用1个LUT6)
- 32 x1 或 64x1的双端口DRAM (占用2个LUT6 )
- 32 x6 或 64x3的简单双端口DRAM(占用4个LUT6)
- 32 x2或 64x1的四端口DRAM (占用4个LUT6)
除此之外这些LUT6还可以配合MUX来使用组成更大深度的DRAM如:
- 128 x 1 的单端口DRAM(占用2个LUT6+1个MUX)
- 128 x 1 的双端口DRAM (占用4个LUT6+2个MUX)
- 256 x 1 的单端口DRAM (占用4个LUT6+3个MUX)
以下是单端口DRAM、双端口DRAM、简单双端口DRAM、四端口DRAM的读写特性(下面图中,所有的的寄存器都是SLICE中四大件(LUT ,MUX,进位链,寄存器)的寄存器,不是DRAM内部结构,有关寄存器的内容在后面章节会讲) :
- 单端口DRAM:同步读,同步写(均以A[5:0]为输入地址),结构如图3所示。D为数据输入,O为数据输出,WCLK为同步时钟,WE为写使能(当要写数据到DRAM时置高,当要从DRAM中读数据时置低)
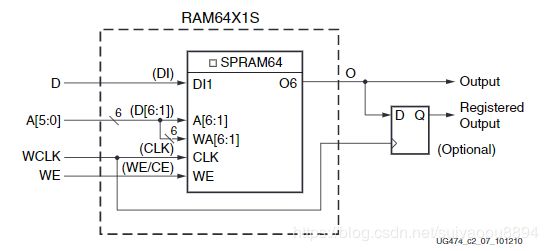 图三:单端口DRAM结构
图三:单端口DRAM结构
- 双端口DRAM : 一个端口(A[5:0]为地址输入)可同步写,异步读。另一个端口(DPRA[5:0]为输入地址)只能异步读,其结构如图4所示。两个LUT6中存放着相同的数据,其实上面的LUT6就是一个单端DRAM,它的输出(SPO)取决于输入地址A[5:0]。下面的LUT6的不同之处就是它的输入端口A[6:1]连的是DRPA[5:0],因此它的输出取决于地址DPRA[5:0]。
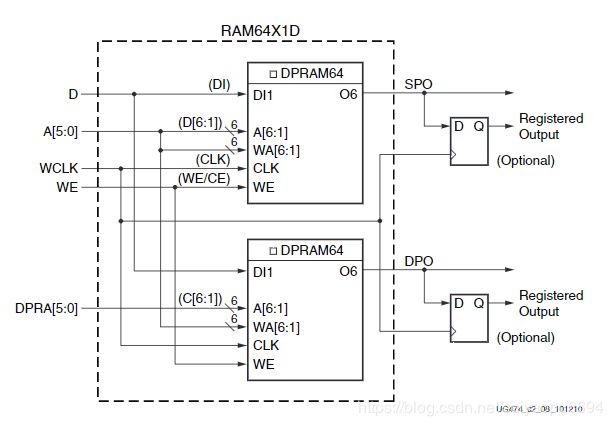 图四:双端口DRAM结构
图四:双端口DRAM结构
- 简单双端口DRAM:一个端口(WADDR为地址输入地址)只可同步写,另一端口(RADDR为地址输入)只能异步读。在64x3简单双端口DRAM(图5)中,3个数据输入口DATA[3:1]并行输入,3个数据输出口O[3:1]并行输出。在32x6简单双端口DRAM(图6)中,6个数据输入口DATA[6:1]并行输入,6个数据输出口O[6:1]并行输出。
 图5:64x3简单双端口DRAM
图5:64x3简单双端口DRAM
 图6:32x6简单双端口DRAM
图6:32x6简单双端口DRAM
- 四端口DRAM: 一个端口(ADDRD为地址输入)可同步写,异步读。另外三个端口(ADDRA,ADDRB,ADDRC为输入地址)只能异步读。结构与双端口DRAM相似,4个LUT所存放着着相同的数据,只不过每个端口都可以单独读不同地址的内容。
 图7:四端口DRAM
图7:四端口DRAM
- 128x1单端口DRAM(图8),它由2个64x1单端口DRAM+1个MUX组成,结构与上一章2个LUT5组成1个LUT6类似,不同之处就是这里只有一个输出口O。要注意:这里的MUX是SLICE中四大件(LUT ,MUX,进位链,寄存器)中的MUX,不是LUT6中的MUX。
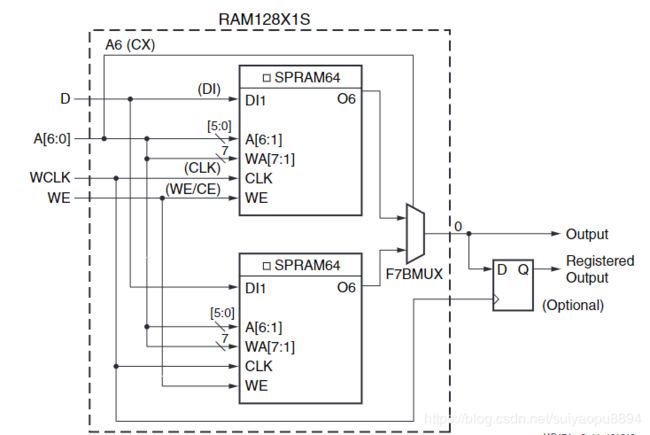 图8:128x1单端口DRAM
图8:128x1单端口DRAM
- 32位移位寄存器,SRL32E(图9)。它支持最高32位的移位输出,可以选择普通数据(D)输入,也可以选择由上一级SRLC32E的SHIFTOUT作为输入。如果想用SRLC32E做12位移位输出,只需要将A[4:0]设置为5'd12,移位输出结果在SHIFTOUT口输出,与此同时O6也将会输出地址5'd12的结果,相当于一个32x1单端口DRAM(这地址是对于SRLC32E外部接口A[4:0]来说的,对于SRL32内部来说它是将高5位地址A[6:2]设为5'd12)。特别注意:SRLC32E只能在同一时钟域使用,不能做跨时钟域打拍使用,因为它内部移位操作不是用32个级联的触发器来做的,而是将上一级的电荷转移到下一级,如果第一级发生出现亚稳态,它将会一直传递到最后一级。
 图9:SRLC32E
图9:SRLC32E
- SRL32E级联为64位移位寄存器(图10) ,上一级的SHIFTOUT输出连到下一级的SHIFTIN输入即可。如果要实现它64x1单端口DRAM功能,需要额外增加一个MUX。可以参考128x1单端口DRAM(图8)的情况,这里不加以累赘。
 图10:SRL32级联组成64位移位寄存器
图10:SRL32级联组成64位移位寄存器
下面我将通过实例来讲解SLICE中的DRAM和 移位寄存器。
单端口DRAM,使用verilog 中的reg来写(例1),综合后一共耗费了54个LUT6,64个寄存器,8个MUX_F7,4个MUX_F4,肯用那么多资源去写一个64x1的DRAM十有八九是土豪。当然造成资源使用过多有可能是我写法比较随意,vivado优化不了,在这里不细纠。
//以下是例1
module dram64_1(
input clk, //input clk
input [5:0]a, //input address
input d, //input data
input wr_en,//input write enable
output o//output
);
//这种写法结果和使用DRAM原语一样,但是会耗费很多资源,当然EDA软件机智点也是可以优化成只用一个LUT的
reg dram64x1 [63:0] ;
always@(clk)
begin
if(wr_en)
begin
dram64x1[a]<=d;
end
end
assign o=dram64x1[a];
endmodule
单端口DRAM,使用verilog 中的原语来写(例2),综合后一共使用了1个LUT6,资源利用率十分亲民。
//以下是例2
module dram64_1(
input clk, //input clk
input [5:0]a, //input address
input d, //input data
input wr_en,//input write enable
output o//output
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst (
.O(o), // 1-bit data output
.A0(a[0]), // Address[0] input bit
.A1(a[1]), // Address[1] input bit
.A2(a[2]), // Address[2] input bit
.A3(a[3]), // Address[3] input bit
.A4(a[4]), // Address[4] input bit
.A5(a[5]), // Address[5] input bit
.D(d), // 1-bit data input
.WCLK(clk), // Write clock input
.WE(wren) // Write enable input
);
endmodule
接下来我将对例(1),例(2)进行仿真,由于我们的例(1),例(2)的顶层的输入输出是一样的,所以两者的testbench一模一样,我们往地址0~15依次写入1111_0000_0000_1111。图11为例(1)仿真结果,两个红色框中输入d的内容和输出o的内容是一样的。至于蓝色框出现不定态x,是因为我没有将例(1)中的RAM初始化。图12为例(2)的仿真结果,结果与例(1)类似,这里写入时,o的输出为我们预先写入的初始值0。
//以下是例(1),例(2)的仿真测试用例
`timescale 1ns / 1ps
module dram64_1_tb(
);
reg clk;
reg [5:0]a;
reg d;
reg wr_en;
reg [5:0]i;
wire o;
dram64_1 dram64_1_inst(.clk(clk),.a(a),.d(d),.wr_en(wr_en),.o(o));
initial begin
clk=1'b1;
a=6'h0;
d=1'b1;
wr_en=1'b1;
i=6'h0;
end
always begin
#10 clk=~clk;
end
always@(posedge clk)begin
i<=i+6'b1;
end
always@(posedge clk)begin
if(i<16)begin
wr_en<=1'b1;
a<=i;
case(i)
0,1,2,3:begin d<=1'b1;end
4,5,6,7:begin d<=1'b0;end
8,9,10,11:begin d<=1'b0;end
11,12,13,14,15:begin d<=1'b1;end
endcase
end
else begin
wr_en<=1'b0;
a<=i-16;
end
end
endmodule
 图11:例(1)的仿真结果
图11:例(1)的仿真结果
 图12:例(1)的仿真结果
图12:例(1)的仿真结果
例(3)是用SLICEM中的SRLC32E来做成32位移位寄存器,总共使用了1个LUT。它所谓的移位就是将上一级的电荷转移到下一级。如果电荷只有二分之一的高电平,它输出也是二分之一的高电平,这样很容易将逻辑错误传递下去,具体内容我会在有关亚稳态的章节讲。
module shift(
input clk,
input ce,
input shift_in,
input [4:0] a,
output Q,
output shift_out
);
SRLC32E #(
.INIT(32'h00000000) // Initial Value of Shift Register
) SRLC32E_inst (
.Q(Q), // SRL data output
.Q31(shift_out), // SRL cascade output pin
.A(a), // 5-bit shift depth select input
.CE(ce), // Clock enable input
.CLK(clk), // Clock input
.D(shift_in) // SRL data input
);
endmodule
例(4)是用SLICE中的reg来做32位移位寄存器(为避免综合成SRLC32E,要在reg前使用(* SHREG_EXTRACT = “no” *)语句,否则会被VIVADO优化成用SRLC32E), 它总共使用了9个LUT ,32个移位寄存器,4个MUX_F7。
module shift(
input clk,
input ce,
input shift_in,
input [4:0] a,
output Q,
output shift_out
);
(* SHREG_EXTRACT = "no" *)reg [31:0] dff;
always@(posedge clk) begin
if(ce) begin
dff[31:0]<={dff[30:0],shift_in};
end
end
assign shift_out=dff[31];
assign Q=dff[a];
endmodule接下俩我们对例(3),例(4)进行仿真。我们在测试用例中每个时钟(周期10ns)上升沿依次写入10101010。。。(记住,第一个数是1)。忽略寄存器未初始化所带来的不定态,正常来说我们会在第32拍得到移位后的结果10101010。。。我们可以看到例(3)仿真结果(图13)在310ns时输出第一个1,但是例(4)仿真结果(图14)在330ns时才输出第1个1,那么哪一个才是对的呢?对此我个人理解例(3)的仿真结果是正确的,在0ns的时候我们可以看到shift_in是0,而不是我们的初始值1,因此寄存器已经在0ns时打了1拍,在310ns输出1,刚好打了32拍。例(4)与预期不符的原因应该是仿真工具在0ns中没有打拍,而是在10ns时打第一拍(初学者应注意:10ns时的输入应该10ns前已经稳定好的那个数值,不是10ns下面所对应的数值),此时输入时0,所以在打第32拍(320ns)时输出是0。
`timescale 1ns / 1ps
module top_tb(
);
reg clk;
reg ce;
reg shift_in;
reg [4:0] a;
wire Q;
wire shift_out;
shift shift_inst(.clk(clk),.ce(ce),.shift_in(shift_in),.a(a),.Q(Q),.shift_out(shift_out));
initial
begin
clk=1;ce=1;shift_in=1;a=5'd31;
end
always
begin
#5 clk=~clk;
end
always@(posedge clk)
shift_in<=~shift_in;
endmodule
 图13:例(3)的仿真输出结果
图13:例(3)的仿真输出结果
 图14:例4的仿真结果
图14:例4的仿真结果
在实际的应用过程中,我们不可能只用到宽度只有几位的输入,我们不可能例化多个原语来将多个64x1DRAM单元拼在一起,也不太推荐直接用verilog语句定义寄存器的方式去写。此时我们应该学会使用与DRAM有关的IP,来自定义不同深度不同位宽的DRAM。下面我简单介绍一下VIVADO 中 DRAM IP的使用(生成 64x16的简单双端口RAM)。
- 在VIVADO工程下点击打开IP Catalog->搜索RAM->找到Distributed Memory Generator 并点击打开。(图15)
 图15:DRAM IP 生成步骤1
图15:DRAM IP 生成步骤1
- 在memory config ,先给这个IP起个帅气,让你印象深刻的,有代表意义的名字,如 SDP。然后再设置深度为64,宽度16。再将Memory Type设置为Simple dual port。如果有需要添加输入输出寄存器的话在Port config中设置,如果要初始化DRAM的值我们在RST&Initialization中设置,这里我们暂时没这需要,直接点OK就行(图16)
 图16:DRAM IP生成步骤2
图16:DRAM IP生成步骤2
- 期间有OK点OK,然后选择Out of context per IP(Global和Out of context per IP的区别就是一个随整个工程一起编译,另一个是作为一个模块单独编译),点击Generate等待IP编译完成。(图17)
 图17:DRAM IP生成步骤3
图17:DRAM IP生成步骤3
- 最后在IP SOURCE 中点击SDP->Instantiation Template-> SDP.veo(veo 为verilog,vho为vhdl)打开SDP这个IP的模板,并复制到自己的工程,根据需求自己做相应的修改。(图18)
 图18:生成DRAM IP步骤4
图18:生成DRAM IP步骤4
好的本章节的内容就到这里。记住本章节的DRAM 是 Distributed RAM 不是Dynamic RAM !!!
最后安利下我的公众号,内容会在本周末上线。
谢谢客官大老爷,点个赞再走呗(●'◡'●)
 我的二维码
我的二维码