Python实现常见排序算法速度比较
1.排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升。
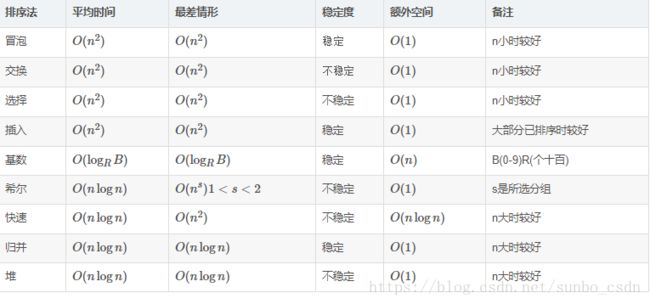
下面分类列举下常见排序算法:
①冒泡排序
冒泡排序的原理是对序列进行遍历,遍历过程中如果发现相邻两个元素,左边的元素大于右边,则进行交换,一次遍历之后最大的元素被移动到对尾,然后进行第二次遍历,直到队列有序。
#冒泡排序
def bubble_sort(list):
l = len(list)
for i in range(l-1,0,-1):
for j in range(i):
if list[j] > list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
return list②选择排序
选择排序的原理是是先找到起始数组中最小的元素,将它交换到i=0;然后寻找剩下元素中最小的元素,将它交换到i=1的位置…… 直到找到第二大的元素,将它交换到n-2的位置。这时,整个数组的排序完成。
#选择排序
def select_sort(list):
length = len(list)
for i in range(length):
min = i
for j in range(i,length):
if list[j] < list[min]:
min = j
list[i],list[min] = list[min],list[i]
return list
③快速排序
任意设置一个基准元素,一般是第一个或者最后一个,将序列以该基准元素为基准,分割成比他小的一部分和比他大的一部分,此时,该基准元素所在的位置就是排序终了之后的准确位置,在对左右两边的序列继续执行同样的操作,直整个个序列有序。
#快速排序
def quick_sort(list):
if list == []:
return []
else:
first = list[0]
left = quick_sort([l for l in list[1:]if l < first])
right = quick_sort([l for l in list[1:] if l > first])
return left +[first] + right④插入排序
将序列的第一个元素当做已经排序好的序列,然后从后面的第二个元素开始,逐个元素进行插入,直到整个序列有序为止。
#插入排序
def insert_sort(list):
length = len(list)
for i in range(1,length):
for j in range(i):
if list[j] > list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
return list⑤堆排序
它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
#堆排序
def heap_sort(array):
def heap_adjust(parent):
child = 2 * parent + 1 # left child
while child < len(heap):
if child + 1 < len(heap):
if heap[child + 1] > heap[child]:
child += 1 # right child
if heap[parent] >= heap[child]:
break
heap[parent], heap[child] = \
heap[child], heap[parent]
parent, child = child, 2 * child + 1
heap, array = array.copy(), []
for i in range(len(heap) // 2, -1, -1):
heap_adjust(i)
while len(heap) != 0:
heap[0], heap[-1] = heap[-1], heap[0]
array.insert(0, heap.pop())
heap_adjust(0)
return array⑥归并排序
归并排序是对数组进行拆分再拆分,直到不能再拆分,然后分别对最小粒度的子数组进行合并,然后再合并稍微大一点的数组,直到最终合成一个最大的数组。分两个函数完成,一个负责拆分,一个负责排序合并。
#归并排序
def merge_sort(array):
def merge_arr(arr_l, arr_r):
array = []
while len(arr_l) and len(arr_r):
if arr_l[0] <= arr_r[0]:
array.append(arr_l.pop(0))
elif arr_l[0] > arr_r[0]:
array.append(arr_r.pop(0))
if len(arr_l) != 0:
array += arr_l
elif len(arr_r) != 0:
array += arr_r
return array⑦希尔排序
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
def shell_sort(slist):
gap = len(slist)
while gap > 1:
gap = gap // 2
for i in range(gap, len(slist)):
for j in range(i % gap, i, gap):
if slist[i] < slist[j]:
slist[i], slist[j] = slist[j], slist[i]
return slist
2.测试验证
import time
from main import *
import sys
sys.setrecursionlimit(100000000)
def timeCount(func):
def wrapper(*arg,**kwarg):
start = time.clock()
func(*arg,**kwarg)
end =time.clock()
print ('used:', end - start)
return wrapper
class Executor(object):
def __init__(self, func, *args, **kwargs):
self.func = func
self.args = args
self.kwargs = kwargs
self.do()
@timeCount
def do(self):
print('-----start:', self.func, '-----')
self.ret = self.func(*self.args, **self.kwargs)
def __del__(self):
print('-----end-----')
class TestClass(object):
list =[]
def testreadlist(self):
for line in open('list.txt'):
self.list.append(line.strip())
print(self.list)
#冒泡排序
def testbubble(self):
Executor(bubble_sort,self.list)
#快速排序
def testquick(self):
Executor(quick_sort,self.list)
#选择排序
def testselect(self):
Executor(select_sort,self.list)
#插入排序
def testinsert(self):
Executor(insert_sort,self.list)
#堆排序
def testhead(self):
Executor(heap_sort,self.list)
#归并排序
def testmerge(self):
Executor(merge_sort,self.list)
#希尔排序
def testshell(self):
Executor(shell_sort,self.list)
def main(self):
self.testreadlist()
self.testbubble()
self.testquick()
self.testselect()
self.testinsert()
self.testhead()
self.testmerge()
self.testshell()
if __name__ =='__main__':
TestClass().main()
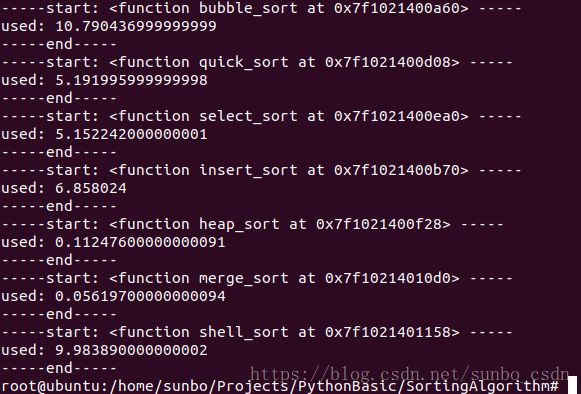
这里测试的200条数据和10000条数据进行的测试,但从计算速度上来看
1.归并排序效率最快
2.冒泡排序和希尔排序速度最慢
当然,对于上面提到的这些排序算法,并没有优劣之分,主要看关注点,也就是需求。综合去看待这些算法,我们可以通过以下几个方面(不完全)判断:时间复杂度,空间复杂度,待排序数组长度,待排序数组特点,程序编写复杂度,实际程序运行环境,实际程序可接受水平等等。说白了就是考虑各种需求和限制条件,程序快不快,占得空间,排序的数多不多,规律不规律,数据重合的多不多,运行的机器高配还是低配,客户或者用户对运行时间的底线等等。