UVa221 Urban Elevations 细述原理
先讲原理:
我们来个简单的模型(假设下面四个楼房一样高):
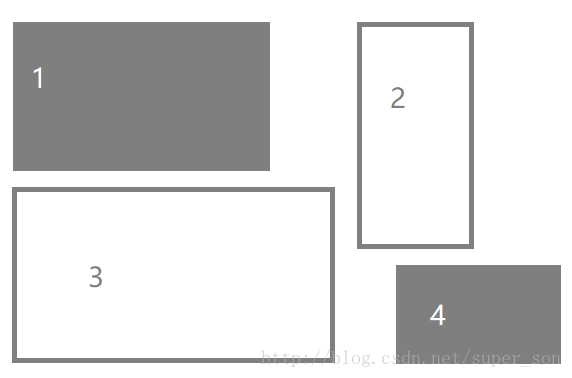
现在我们来想想,如果我们从前向后看,能看到几个楼房?(楼房都一样高)
显然是3号、2号和4号。
那么怎么让计算机解决这个问题呢?
我们判断建筑物是否可见,我们是不是可以枚举从 3号楼最左端到4号楼的最右端 所有的x坐标,看看该建筑物是否在x轴的某个范围内可见,这个在我们人脑中想一下就可以得出答案,但是计算机可不能这样处理问题,因为从 3号楼最右端到4号楼的最左端 的x坐标有无数个,这样一来我们只能将问题 离散化 ,怎么离散化呢?看下图:
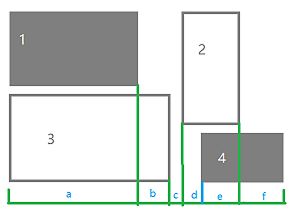
我们将 3号楼最左端到4号楼的最右端 的区间给分割成6个小区间,这样一来我们就会发现每个区间只有两种状态:1. 存在楼房,2. 不存在楼房。
那么我们怎么知道这个区间内是否存在楼房呢?我们可以在区间中任意取一点,然后判断这点是否属于某栋楼房的范围,这个点我们就可以取中点。
现在我们最后的问题是怎么判断某栋楼是否在某个区间中可见,必须满足下面两个条件:
- 建筑物必须包含这个区间(前面讲到,只须判断区间中点是否在建筑物范围内即可)
- 建筑物的南面不能有和其处于同一区间并且比其高的建筑物(这个我们只须遍历所有楼房即可)
现在我们来看看怎么通过代码实现这个过程:
先看main()函数:
#include首先,我们使用的是结构体数组,并且在其中重载了 < 运算符,这是为了方便我们后来使用sort()函数进行排序。然后我们读入数据,每读入一个楼房,就将其x, y, w, d, h都记录进结构体数组。并为其分配一个id,然后将其x 和 x+w存入 double x[maxn*2]; 这个数组。然后我们使用sort()函数并按照我们重载的小于运算符来排序结构体数组。接着又是一个sort()函数,这是为使用unique()函数做准备,(对unique()函数不清楚的可以参考http://blog.csdn.net/u014598631/article/details/34884809),当x数组经过去重处理之后,里面就相当于是一条数轴。相邻的两个元素是一个小区间。然后我们看看下面两个函数:
bool cover(int i, double mx) {
return b[i].x <= mx && b[i].x+b[i].w >= mx;
}
//判断建筑物i在x=mx处是否可见
bool visible(int i,double mx) {
if(!cover(i, mx)) return false;
for(int k = 0; k < n; ++k)
if(b[k].y < b[i].y && b[k].h >= b[i].h && cover(k, mx)) return false;
return true;
}现在我们可以看看main()中循环内的内容了,方法是遍历结构体数组,对其中的每个元素都判断是否可见于 x 中的某个区间中,怎么个判断法呢?前面讲过了,所以上面的两个函数也就不难理解了。