手把手教你入门Hadoop(附代码&资源)

作者:Piotr Krewski&Adam Kawa
翻译:陈之炎
校对:丁楠雅
本文约6000字,建议阅读10分钟。
本文为你介绍Hadoop的核心概念,描述其体系架构,指导您如何开始使用Hadoop以及在Hadoop上编写和执行各种应用程序。
作者:GETINDATA公司创始人兼大数据顾问彼得亚·雷克鲁斯基(Piotr Krewski)和GETINDATA公司首席执行官兼创始人亚当·卡瓦(Adam Kawa)
目录
内容简介
设计理念
HADOOP组件
HDFS
YARN
YARN 应用程序
监控 YARN 应用程序
用HADOOP处理数据
HADOOP 的其它工具
其它资源
内容简介
Hadoop是目前最流行的大数据软件框架之一,它能利用简单的高级程序对大型数据集进行分布式存储和处理。本文将介绍Hadoop的核心概念,描述其体系架构,指导您如何开始使用Hadoop以及在Hadoop上编写和执行各种应用程序。
Hadoop是阿帕奇(Apache)软件基金会发布的一个开源项目,它可以安装在服务器集群上,通过服务器之间的通信和协同工作来存储和处理大型数据集。因为能够高效地处理大数据,Hadoop近几年获得了巨大的成功。它使得公司可以将所有数据存储在一个系统中,并对这些数据进行分析,而这种规模的大数据分析用传统解决方案是无法实现或实现起来代价巨大的。
以Hadoop为基础开发的大量工具提供了各种各样的功能,Hadoop还出色地集成了许多辅助系统和实用程序,使得工作更简单高效。这些组件共同构成了Hadoop生态系统。
Hadoop可以被视为一个大数据操作系统,它能在所有大型数据集上运行不同类型的工作负载,包括脱机批处理、机器学习乃至实时流处理。
您可以访问hadoop.apache.org网站获取有关该项目的更多信息和详细文档。
您可以从hadoop.apache.org获取代码(推荐使用该方法)来安装Hadoop,或者选择Hadoop商业发行版。最常用的三个商业版有Cloudera(CDH)、Hortonworks(HDP)和MapR。这些商业版都基于Hadoop的框架基础,将一些组件进行了打包和增强,以实现较好的集成和兼容。此外,这些商业版还提供了管理和监控平台的(开源或专有的)工具。
设计理念
Hadoop在解决大型数据集的处理和存储问题上,根据以下核心特性构建:
分布式:存储和处理并非构建在一台大型超级计算机之上,而是分布在一群小型电脑上,这些电脑之间可以相互通信并协同工作。
水平可伸缩性:只需添加新机器就可以很容易地扩展Hadoop集群。每台新机器都相应地增加了Hadoop集群的总存储和处理能力。
容错:即使一些硬件或软件组件不能正常工作,Hadoop也能继续运行。
成本优化:Hadoop不需要昂贵的高端服务器,而且在没有商业许可证的情况下也可以正常工作。
编程抽象:Hadoop负责处理与分布式计算相关的所有纷杂的细节。由于有高级API,用户可以专注于实现业务逻辑,解决他们在现实世界中的问题。
数据本地化:Hadoop不会将大型数据集迁移到应用程序正在运行的位置,而是在数据所在位置运行应用程序。
Hadoop组件
Hadoop有两个核心组件:
HDFS:分布式文件系统
YARN:集群资源管理技术
许多执行框架运行在YARN之上,每个框架都针对特定的用例进行调优。下文将在“YARN应用程序”中重点讨论。
我们来看看它们的架构,了解一下它们是如何合作的。
HDFS
HDFS是Hadoop分布式文件系统。
它可以在许多服务器上运行,根据需要,HDFS可以轻松扩展到数千个节点和乃至PB(Petabytes 10的15次方字节)量级的数据。
HDFS设置容量越大,某些磁盘、服务器或网络交换机出故障的概率就越大。
HDFS通过在多个服务器上复制数据来修复这些故障。
HDFS会自动检测给定组件是否发生故障,并采取一种对用户透明的方式进行必要的恢复操作。
HDFS是为存储数百兆字节或千兆字节的大型文件而设计的,它提供高吞吐量的流式数据访问,一次写入多次读取。因此对于大型文件而言,HDFS工作起来是非常有魅力的。但是,如果您需要存储大量具有随机读写访问权限的小文件,那么RDBMS和Apache HBASE等其他系统可能更好些。
注:HDFS不允许修改文件的内容。只支持在文件末尾追加数据。不过,Hadoop将HDFS设计成其许多可插拔的存储选件之一。例如:专用文件系统MapR-Fs的文件就是完全可读写的。其他HDFS替代品包括Amazon S3、Google Cloud Storage和IBM GPFS等。
HDFS架构
HDFS由在选定集群节点上安装和运行的下列进程组成:
NameNode:负责管理文件系统命名空间(文件名、权限和所有权、上次修改日期等)的主进程。控制对存储在HDFS中的数据的访问。如果NameNode关闭,则无法访问数据。幸运的是,您可以配置多个NameNodes,以确保此关键HDFS过程的高可用性。
DataNodes:安装在负责存储和服务数据的集群中的每个工作节点上的从进程。
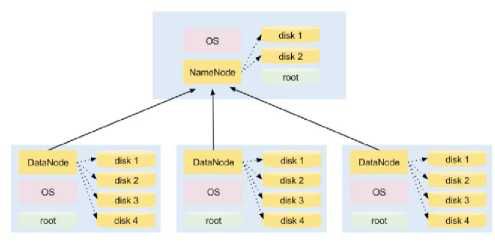
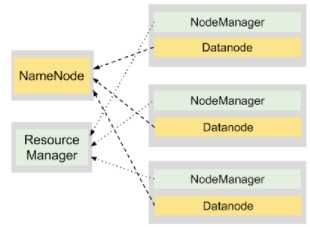
图1说明了在一个4节点的集群上安装HDFS。一个节点的主机节点为NameNode进程而其他三节点为DataNode进程
注:NameNode和DataNode是在Linux操作系统 (如RedHat、CentOS、Ubuntu等)之上运行的Java进程。它们使用本地磁盘存储HDFS数据。
HDFS将每个文件分成一系列较小但仍然较大的块(默认的块大小等于128 MB--更大的块意味着更少的磁盘查找操作,从而导致更大的吞吐量)。每个块被冗余地存储在三个DataNode上,以实现容错(每个文件的副本数量是可配置的)。
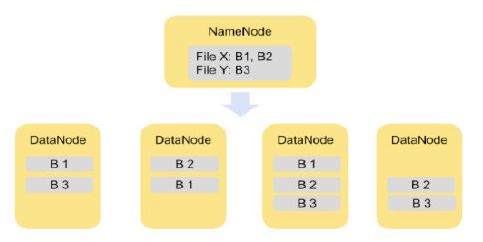
图2演示了将文件分割成块的概念。文件X被分割成B1和B2块,Y文件只包含一个块B3。在集群上将所有块做两个备份。
与HDFS交互
HDFS提供了一个简单的类似POSIX的接口来处理数据。使用HDFS DFS命令执行文件系统操作。
要开始使用Hadoop,您不必经历设置整个集群的过程。Hadoop可以在一台机器上以
所谓的伪分布式模式运行。您可以下载sandbox虚拟机,它自带所有HDFS组件,使您可以随时开始使用Hadoop!只需按照以下链接之一的步骤:
mapr.com/products/mapr-sandbox-hadoop
hortonworks.eom/products/hortonworks-sandbox/#install
cloudera.com/downloads/quickstart_vms/5-12.html
HDFS用户可以按照以下步骤执行典型操作:
列出主目录的内容:
$ hdfs dfs -ls /user/adam
将文件从本地文件系统加载到HDFS:
$ hdfs dfs -put songs.txt /user/adam
从HDFS读取文件内容:
$ hdfs dfs -cat /user/adam/songs.txt
更改文件的权限:
$ hdfs dfs -chmod 700 /user/adam/songs.txt
将文件的复制因子设置为4:
$ hdfs dfs -setrep -w 4 /user/adam/songs.txt
检查文件的大小:
'$ hdfs dfs -du -h /user/adam/songs.txt Create a subdirectory in your home directory.
$ hdfs dfs -mkdir songs
注意,相对路径总是引用执行命令的用户的主目录。HDFS上没有“当前”目录的概念(换句话说,没有“CD”命令):
将文件移到新创建的子目录:
$ hdfs dfs -mv songs.txt songs
从HDFS中删除一个目录:
$ hdfs dfs -rm -r songs
注:删除的文件和目录被移动到trash中 (HDFS上主目录中的.trash),并保留一天才被永久删除。只需将它们从.Trash复制或移动到原始位置即可恢复它们。
您可以在没有任何参数的情况下键入HDFS DFS以获得可用命令的完整列表。
如果您更喜欢使用图形界面与HDFS交互,您可以查看免费的开源HUE (Hadoop用户体验)。它包含一个方便的“文件浏览器”组件,允许您浏览HDFS文件和目录并执行基本操作。
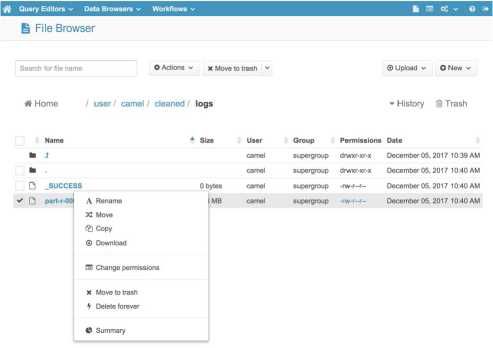
您也可以使用HUE的“上传”按钮,直接从您的计算机上传文件到HDFS。
YARN
YARN (另一个资源协商器)负责管理Hadoop集群上的资源,并允许运行各种分布式应用程序来处理存储在HDFS上的数据。
YARN类似于HDFS,遵循主从设计,ResourceManager进程充当主程序,多个NodeManager充当工作人员。它们的职责如下:
ResourceManager
跟踪集群中每个服务器上的LiveNodeManager和可用计算资源的数量。
为应用程序分配可用资源。
监视Hadoop集群上所有应用程序的执行情况。
NodeManager
管理Hadoop集群中单个节点上的计算资源(RAM和CPU)。
运行各种应用程序的任务,并强制它们在限定的计算资源范围之内。
YARN以资源容器的形式将集群资源分配给各种应用程序,这些资源容器代表RAM数量和CPU核数的组合。
在YARN集群上执行的每个应用程序都有自己的ApplicationMaster进程。当应用程序被安排在集群上并协调此应用程序中所有任务的执行时,此过程就开始了。
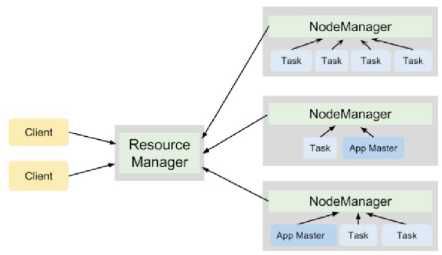
图3展示了YARN进程在4节点集群上运行两个应用程序的协作情况,共计产生7个任务。
HADOOP = HDFS + YARN
在同一个集群上运行的HDFS和YARN为我们提供了一个存储和处理大型数据集的强大平台。
DataNode和NodeManager进程配置在相同的节点上,以启用本地数据。这种设计允许在存储数据的机器上执行计算,从而将通过网络发送大量数据的必要性降到最低,使得执行时间更快。
YARN 应用程序
YARN仅仅是一个资源管理器,它知道如何将分布式计算资源分配给运行在Hadoop集群上的各种应用程序。换句话说,YARN本身不提供任何处理逻辑来分析HDFS中的数据。因此,各种处理框架必须与YARN集成(通过提供ApplicationMaster实现),以便在Hadoop集群上运行,并处理来自HDFS的数据。
下面介绍几个最流行的分布式计算框架,这些框架都可以在由YARN驱动的Hadoop集群上运行。
MapReduce:Hadoop的最传统和古老的处理框架,它将计算表示为一系列映射和归约的任务。它目前正在被更快的引擎,如Spark或Flink所取代。
Apache Spark:用于处理大规模数据的快速通用引擎,它通过在内存中缓存数据来优化计算(下文将详细介绍)。
Apache Flink:一个高吞吐量、低延迟的批处理和流处理引擎。它以其强大的实时处理大数据流的能力脱颖而出。下面这篇综述文章介绍了Spark和Flink之间的区别:dzone.com/ports/apache-Hadoop-vs-apache-smash
Apache Tez:一个旨在加速使用Hive执行SQL查询的引擎。它可在Hortonworks数据平台上使用,在该平台中,它将MapReduce替换为Hive.k的执行引擎。
监控YARN应用程序
使用ResourceManager WebUI可以跟踪运行在Hadoop集群上的所有应用程序的执行情况,默认情况下,它在端口8088。
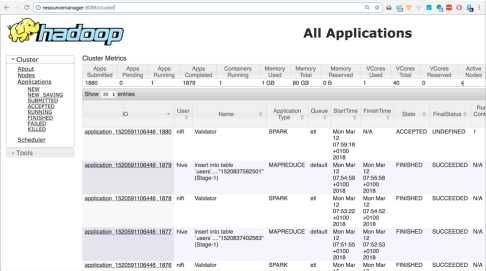
每个应用程序都可以读取大量重要信息。
使用ResourceManager WebUI,可以检查RAM总数、可用于处理的CPU核数量以及
当前Hadoop集群负载。查看页面顶部的“集群度量”。
单击"ID"列中的条目,可以获得有关所选应用程序执行的更详细的度量和统计数据。
用HADOOP处理数据
有许多框架可以简化在Hadoop上实现分布式应用程序的过程。在本节中,我们将重点介绍最流行的几种:HIVE和Spark。
HIVE
Hive允许使用熟悉的SQL语言处理HDFS上的数据。
在使用Hive时,HDFS中的数据集表示为具有行和列的表。因此,对于那些已经了解SQL并有使用关系数据库经验的人来说,Hive很容易学习。
Hive不是独立的执行引擎。每个Hive查询被翻译成MapReduce,Tez或Spark代码,随后在Hadoop集群中得以执行。
HIVE 例子
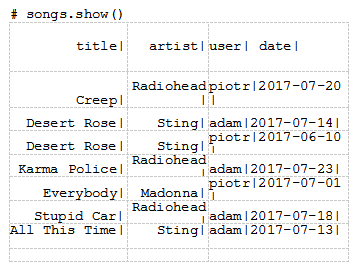
让我们处理一个关于用户在一段时间里听的歌曲的数据集。输入数据由一个名为Song s.tsv的tab分隔文件组成:
Creep" Radiohead piotr 2017-07-20 Desert Rose" Sting adam 2017-07-14 Desert Rose" Sting piotr 2017-06-10 Karma Police" Radiohead adam 2017-07-23 Everybody" Madonna piotr 2017-07-01 Stupid Car" Radiohead adam 2017-07-18 All This Time" Sting adam 2017-07-13
现在用Hive寻找2017年7月份两位最受欢迎的艺术家。
将Song s.txt文件上传HDFS。您可以在HUE中的“File Browser”帮助下完成此操作,也可以使用命令行工具键入以下命令:
# hdfs dfs -mkdir /user/training/songs
# hdfs dfs -put songs.txt /user/training/songs
使用Beeline客户端进入Hive。您必须向HiveServer 2提供一个地址,该进程允许远程客户端(如Beeline)执行Hive查询和检索结果。
# beeline
beeline> !connect jdbc:hive2://localhost:10000
在Hive中创建一个指向HDFS数据的表(请注意,我们需要指定文件的分隔符和位置,以便Hive可以将原始数据表示为表):

使用Beeline开始会话后,您创建的所有表都将位于“默认”数据库下。您可以通过提供特定的数据库名称作为表名的前缀,或者键入“use
Check if the table was created successfully: beeline> SHOW tables; Run a query that finds the two most popular artists in July, 2017:
检查表创建是否成功:beeline>>显示表;运行一个查询,找到在2017年7月份两位最受欢迎的艺术家:
SELECT artist, COUNT(\*) AS total FROM songs
WHERE year(date) = 2017 AND month(date) = 7 GROUP BY artist ORDER BY total DESC LIMIT 2;
您可以使用ResourceManager WebUI监视查询的执行情况。根据配置,您将看到MapReduce作业或Spark应用程序在集群上的运行情况。
注:您还可以从HUE中编写和执行Hive查询。有一个专门用于Hive查询的编辑器,具有语法自动完成和着色、保存查询、以及以行、条形或饼图形显示结果等基本功能。
SPARK
Apache Spark是一个通用的分布式计算框架。它与Hadoop生态系统友好集成,Spark应用程序可以很容易地在YARN上运行。
与传统的Hadoop计算范式MapReduce相比,Spark在满足不同的数据处理需求的同时提供了出色的性能、易用性和通用性。
Spark的速度主要来自它在RAM中存储数据的能力,在后续执行步骤中对执行策略和串行数据进行优化。
让我们直接到代码中去体验一下Spark。我们可以从Scala、Java、Python、SQL或RAPI中进行选择。这个例子是用Python写的。启动Spark Python shell(名为pyspark)
输入 # pyspark.
片刻之后,你会看到一个Spark提示。这意味着Spark应用程序已在YARN上启动。(您可以转到ResourceManager WebUI进行确认;查找一个名为“PySparkShell”的正在运行的应用程序)。
如果您不喜欢使用shell,则可以查看基于web的笔记本,如jupyter.org或Zeppelin(zeppelin.apache.org)。
作为使用Spark的Python DataFrame API的一个示例,我们实现与Hive相同的逻辑,找到2017年7月两位最受欢迎的艺术家。
首先,我们必须从Hive表中读取数据# songs = spark.table(MsongsM)
Spark中的数据对象以所谓的dataframe的方式呈现。Dataframes是不可变的,是通过从不同的源系统读取数据或对其他数据文件应用转换而生成的。
调用Show()方法预览dataframe的内容:
为了获得预期的结果,我们需要使用多个直观的函数:
# from pyspark.sql.functions import desc
# songs.filter(Myear(date) = 2017 AND month(date) = 7") \
.groupBy(MartistM) \
.count() \
.sort(desc("count")) \
.limit(2) \
.show()
Spark的dataframe转换看起来类似于SQL操作符,因此它们非常容易使用和理解。
如果您对相同的dataframe执行多个转换(例如创建一个新的数据集),您可以通过调用dataframe上的cache()方法(例如Song s.cache()),告诉Spark在内存中存储它。Spark会将您的数据保存在RAM中,并在运行后续查询时避免触及磁盘,从而使您获得更好的性能。
Dataframes只是Spark中可用的API之一。此外,还有用于近实时处理(Spark流)、机器学习(MLIB)或图形处理(图形帧)的API和库。
由于Spark的功能丰富,您可以使用它来解决各种各样的处理需求,保持在相同的框架内,并在不同的上下文(例如批处理和流)之间共享代码片段。
Spark可以直接将数据读写到许多不同的数据存储区,而不仅仅是HDFS。您可以轻松地从MySQL或Oracle表中的记录、HBASE中的行、本地磁盘上的JSON文件、ElasticSearch中的索引数据以及许多其他的数据中创建数据。
Hadoop的其他工具
Hadoop生态系统包含许多不同的工具来完成现代大数据平台的特定需求。下文列举了一些前面章节中没有提到的流行和重要项目的列表。
Sqoop:从关系数据存储区和HDFS/HFE及其他方式迁移数据的不可缺少的工具。
您可以使用命令行与Sqoop交互,选择所需的操作并提供一系列控制数据迁移过程的必要参数。
从MySQL表导入有关用户的数据只需键入以下命令:
# sqoop import \
--connect jdbc:mysql://localhost/streamrock \
--username $(whoami) -P \
--table users \
--hive-import
注:Sqoop使用MapReduce在关系型数据库和Hadoop之间传输数据。你可以跟踪由ResourceManager WebUI Sqoop提交的MapReduce应用。
Oozie:Hadoop的协调和编排服务。
使用Oozie,您可以构建一个在Hadoop集群上执行的不同操作的工作流(例如HDFS命令、Spark应用程序、Hive查询、Sqoop导入等等),然后为自动执行安排工作流。
HBase:一个建立在HDFS之上的NoSQL数据库。它允许使用行键对单个记录进行非常快速的随机读写。
Zookeeper:Hadoop的分布式同步和配置管理服务。大量的Hadoop服务利用Zookeeper正确有效地在分布式环境中工作。
小结
Apache Hadoop是用于大数据处理的最流行的平台,这得益于诸如线性可伸缩性、高级APIs、能够在异构硬件上运行(无论是在前端还是在云中)、容错和开源等特性。十多年来,Hadoop已经被许多公司成功地应用于生产中。
Hadoop生态系统提供了各种开源工具,用于收集、存储和处理数据,以及集群部署、监视和数据安全。多亏了这个令人惊叹的工具生态系统,每一家公司现在都可以以一种分布式和高度可伸缩的方式轻松、廉价地存储和处理大量的数据。
其他资源
hadoop.apache.org
hive.apache.org
spark.apache.org
spark.apache.org/docs/latest/sql-programming-guide.html
dzone.com/articles/apache-hadoop-vs-apache-spark
dzone.com/articles/hadoop-and-spark-synergy-is-real
sqoop.apache.orgdzone.com/articles/sqoop-import-data-from-mysql-to-hive
oozie.apache.org
tez.apache.org
主要的工具包:
Cloudera: cloudera.com/content/cloudera/en/products- and-services/cdh.html
MapR: mapr.com/products/mapr-editions
Hortonworks: hortonworks.com/hadoop/
本文由GetInData的创始人兼大数据顾问彼得亚·雷克鲁斯基(PiotrKrewski)与GetInData首席执行官兼创始人亚当·卡瓦(Adam Kawa)撰写
彼得亚(Piotr)在编写运行于Hadoop集群上的应用程序以及维护、管理和扩展Hadoop集群方面具有丰富的实践经验。他是GetInData的联合创始人之一,帮助公司构建可伸缩的分布式体系结构,用于存储和处理大数据。Piotr还担任Hadoop讲师,为管理员、开发人员和使用大数据解决方案的分析师提供GetInData专业培训。
亚当(Adam)于2010找到他在 Hadoop的首份工作后,成为了大数据的粉丝。自那以后,他一直在Spotify(他自豪地经营着欧洲最大和发展最快的Hadoop集群之一)、Truecaller、华沙大学、Cloudera培训合作伙伴等大数据公司工作。三年前,他创立了GetinData:一家帮助客户运用数据驱动的公司,并提出了创新的大数据解决方案。亚当也是一位博主,华沙Hadoop用户组的联合组织者,并经常在大型数据会议上发言。
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织