Python爬取国家数据中心环境数据(全国城市空气质量小时报)并导入csv文件
1.开发环境:
python 3.5 + fiddler 4 (抓包工具)+ 火狐浏览器 + idea
2.分析要爬取的页面
2.1 首页 数据中心 点击 全国城市空气质量小时报 查看 fiddler4
表格中的内容就是要抓取的对象
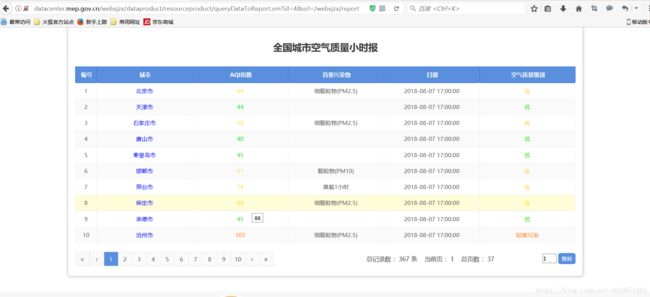
分析fiddler 4 看出请求的方式 请求参数 以及 返回的响应对象
注意:一定要抓 返回带有 上述表格 的url (直接请求的url 不含该表格 可以通过浏览器F12查看开发者模式分析)如图:
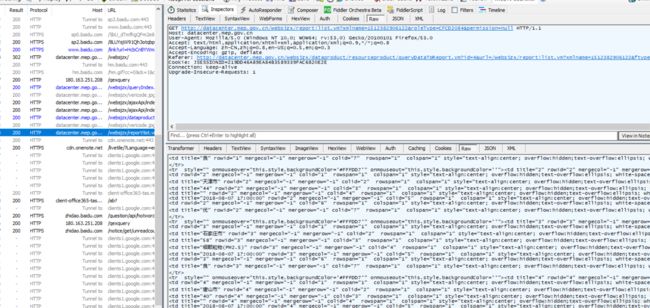
2.2 发出请求抓取数据 并将每个分页html保存至当前文件夹下 data目录
# code = utf-8
#####
# 在url界面发出post请求
# 构造data数据和请求数据 参照 火狐浏览器F12
#####
import requests
from urllib import parse
import time
def gethtml(pagenum=1, inpageno=0):
ISOTIMEFORMAT='%Y-%m-%d+%H'
localtime = time.strftime(ISOTIMEFORMAT,time.localtime())
str_time1 = time.strftime(ISOTIMEFORMAT,time.localtime()).split("+")
#请求里面的时间不能为当前时间 加以调整
str_time = str_time1[0] + " " + str(int(str_time1[1])-2) + ":00:00"
url = 'http://datacenter.mep.gov.cn/websjzx/report!list.vm?xmlname=1512382906122&roleType=CFCD2084&permission=null'
#data 和 headers 中可能有些值 没有什么用 但一并带上 防止出错
# 注意:只带一些有用的值 是过不去的
data = {
'pageNum': str(pagenum),
'orderby': "",
'ordertype': "",
'gisDataJson': '',
'inPageNo': str(inpageno),
'xmlname': '1512382906122',
'queryflag': 'open',
'isdesignpatterns': 'false',
'roleType': 'CFCD2084',
'permission': '0',
'AREA': '',
'V_DATE': str(str_time),
'E_DATE': str(str_time),
}
headers = {
"Host": "datacenter.mep.gov.cn",
"Connection": "keep-alive",
"Content-Length": "232",
"Cache-Control": "max-age=0",
"Origin": "http://datacenter.mep.gov.cn",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer": "http://datacenter.mep.gov.cn/websjzx/report!list.vm?xmlname=1512382906122&roleType=CFCD2084&permission=null",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "JSESSIONID=219DD46A89EA84B3589339FAC6820E2E",
}
#将 data 包装成 bytes
qs = parse.urlencode(data).encode("utf-8")
response = requests.post(url, headers=headers, data=qs)
html = response.content.decode("utf-8")
#将爬下来的网站保存
#以utf-8 创建文件 不然会报错
with open("./data/data"+localtime+"_"+str(pagenum)+".txt", 'w', encoding="utf-8") as f:
f.write(html)
f.close()
if pagenum < 37:
pagenum += 1
inpageno += 1
gethtml(pagenum, inpageno)
else:
return
if __name__ == '__main__':
gethtml()
2.3 利用正则表达式 分析页面 得到想要的数据
# code = utf-8
import os, re
def getdata(filename):
data = []
datalists = []
with open(filename, 'r', encoding='utf-8') as f1:
txt = f1.read()
f1.close()
res_tr = r'(.*)? '
m_tr = re.findall(res_tr, txt, re.S | re.M)
for line in m_tr:
###匹配表格标题
res_th = r'(.*?) '
m_th = re.findall(res_th, line, re.S | re.M)
#print(m_th)
#print(len(m_th))
for mm in m_th:
data.append(mm[2].strip("\" \""))
datalists.append(data)
data=[]
###匹配表格内容
res_td = r'(.*?) '
m_td = re.findall(res_td, line, re.S | re.M)
##print(len(m_td))
for nn in m_td:
data.append(nn[2].strip("\"\" \"\""))
if(len(data) == 6):
datalists.append(data)
#print(data)
data = []
return datalists[6:]
if __name__ == '__main__':
files = os.listdir('./data')
for filename in files:
datalists = getdata('./data/'+filename)
import csv
csvfile = open("data_8_7.csv", "a+",encoding='utf-8')
try:
writer = csv.writer(csvfile)
for datalist in datalists:
writer.writerow(datalist)
except IOError as e:
print(e)
finally:
csvfile.close()