NPD实现及其与pico一脉相承的关系
2017/8/1 更:推荐大家采用MTCNN算法代替NPD,其效果更佳,速度也较快,实现较多,代码与模型皆已开源。
pico参考论文:Object Detection with Pixel Intensity Comparisons Organized in Decision Trees.pdf
pico实现代码:https://github.com/nenadmarkus/pico
Pico(Pixel Intensity Comparison-based Object detection)发表于2014年,它也继承于Viola-Jones算法并对其做了一部分改进,最大的不同在于特征提取方式,不同于Viola-Jones的Haar特征,pico则是提取点对特征,对两个像素点进行对比。实验表明这种特征比Haar特征更为有效,且运算时间更短。
pico的亮点:
- 高运行速度、低模型尺寸
- 对图像无需预处理
- 无需计算积分图、HOG梯度直方图、图像放大、或其他的数据结构转换
- 所有的二叉决策树都基于同一种特征类型
- 对稍作修改就可以检测倾斜人脸
pico的训练逻辑:
- 初始化:
读入训练数据。
设置二叉决策树点对的取值范围
设置级连的层数 - 采样训练数据:
对于正例:读取中心点坐标、尺寸大小与其下标(正例与负例都存储于同一结构体,所以需要下标来得知正例位置)。
对于负例:中心点坐标会在负例图片上随机采样,尺寸则在正例图片的尺寸数组中随机采样,直至数量与正例相同。所有数据与正例一同存储,通过tvals的值判别其是正例还是负例。
无论正例还是负例,采样前会做筛选,对于第一次采样,所有数据都会通过,对于后面的采样,只有通过前一个层的筛选才可通过。
最后采样结束后会输出正例的通过率与负例的通过率,也就是其召回率与误检率。返回的值是误检率。- 训练新的层:
参数包括该层的最低召回率和最高误检率,树的最大数量。特别注明o是训练数据的得分。
层的训练结束条件是其误检率低于最高误检率,或树的数量大于该层树的最大数量,最低召回率决定该层的阈值。
训练过程算法如下所示:
1、初始化每个训练数据的权值并作归一化,其权值为其得分与其类别当前数据数目的比值,也就是说,假如负例较少,那么负例的数据权重会较大,假如某个数据的输出较高,说明该数据在之前的分类中表现较好(该数据在树上得到的叶子结点得分较高,某个叶子结点得分越高,说明其误差越低,分类效果越优),那么接下来它的权重也会较大。
2、单棵树的训练
参数tcodes、luts、thresholds是一棵树的基本组成部分,tcodes、luts是两个二维数组,thresholds是一维数组,这三个数组第一维都是树的下标,tcodes第二维是树上的所有非叶子结点,luts第二维是树上的所有叶子结点。
参数nodeidx为当前结点的id,d为当前结点深度,maxd为树的最大深度。
(a)首先随机生成检测点对
(b)对所有检测点对依次计算在所有训练数据上的平均误差,误差越小,说明预测越准确。
(c)找出使误差最小的检测点对,作为该结点的检测点对,将训练数据根据这个检测点对分布为两部分,一部分结果都为正,另一部分都为负。
(d)生成两棵子树
(e)当数据分到不能再分时,检测点对设为0,不做其他操作并直接生成两棵子树。
(f)当树的深度达到最大值时,生成叶子结点的值,该值越大,说明该结点的预测越准确。
(g)最后设置该树的阈值,若为该层最后一棵树,则其阈值为该层的阈值,否则为-1337。
3、更新所有训练数据的得分。
4、当召回率高于最小召回率,误检率低于最高误检率时,结束训练该层,同时生成该层的阈值。
- 训练新的层:
- 存储模型:
模型信息包括:
version:版本
bbox:特征点对提取空间
tdepth:树的深度
ntrees:树的数量
和所有树的信息,每棵树包含:
非叶子结点特征点对
叶子结点分数
该树的阈值
pico的检测逻辑:
- Pico 采用滑窗策略,图像大小维持不变,通过窗口不断移动与放大,实现对图像上所有区域的检测。
- 针对每一个窗口,使其通过所有树,每通过一棵树会得到一个结果,这个结果不断递加,当其小于阈值时,则拒绝该窗口,判定其非人脸。
- 若该窗口通过了所有树,其结果大于阈值,则接受该窗口,判定其为人脸,该结果为其置信度。
- 检测完所有窗口后做一次聚类, 假如两个区域的交集比上并集大于0.3,则判定该为同一人脸,结果取其坐标与大小的均值,置信度选择累加。
pico训练数据准备
正例采用AFLW数据集,共包含25000张已手工标注的人脸图片,其中59%为女性,41%为男性,大部分的图片都是彩色,只有少部分是灰色图片。
负例采用ImageNet上的训练数据,挑选了约4万张完全不包含人脸的背景图片。
在训练前所有正例与负例数据被预整理为指定格式文件,将标注与图片数据整合在一个文件中,方便以后的训练,数据预处理代码如下:
background.py genki.py
genki用以加载正例数据,background用以加载负例数据。
step1:
python genki.py path/to/genki > trdata
genki.py中需要的修改参数有两个,lin138:imlist存储的是图片地址,lin140-143分别读取图片中心点的坐标(x,y)与半径(人脸图片长宽的2/3),顺序与imlist对应。
每张人脸会对其做镜面变换,以及长宽和大小的7次变换,总计15次变换。
一张正图片的存储格式如下:
长宽(h,w)
二进制格式的图片字符串数据(w*h大小)
变换次数
所有变换生成的label(r,c,s)
镜像后的二进制格式的图片字符串数据(w*h大小)
镜像后变换次数
镜像后所有变换生成的label(r,c,s)
step2:
python background.py path/to/background >> trdata
background.py会将path/to/background目录下的图片添加至trdata中,不做变换。
一张负例图片的存储格式如下:
长宽(h,w)
二进制格式的图片字符串数据(w*h大小)
负例标识:0
这两步之后trdata 就包含了所需的所有正例数据、正例数据标注以及所有负例数据了。
可能会遇到的问题:
1、buffer报错
数据写入过程中,buffer在python2中不被支持,删掉.buffer即可。
2、python依赖问题
genki.py和background.py需要numpy和scipy支持,numpy和scipy需要blas、lapack,安装过程参考如下网页:
http://www.centoscn.com/image-text/install/2014/0410/2765.html
3、打开aflw.sqlite
这里注意mksqlite的后缀对应着不同的操作系统,mac的是mexmaci64,如果是其它,则不会被识别。
NPD代替pico
由于Pico的特征设计比较简单,所以其抗噪声能力较弱,论文以高斯噪声测试Pico的抗噪声能力,并对比V-J和LBPs特征,结果如下:

可以看出,随着噪声级别的提升,Pico的召回率迅速下降。
论文持观点表示在现代摄像设备上,高模糊图像比较罕见,所以该测试并不是很有意义,但是在我们的测试中发现,Pico不仅对模糊图像鲁棒性较差,对遮挡和曝光图像的鲁棒性同样较差。
目前在目标特征提取上,主要方法有如下五种:
以这五种特征为基础,又演变出众多其它特征提取方法,分支如下
- HOG
DPM, SIFT, PCA-SIFT, SURF - LBP
tLBP, dLBP, mLBP, Multi-block LBP, VLBP, RGB-LBP. - Haar-like
- CNN
- 基于像素点比较
Pico, NPD
新的特征选取:
NPD同样是基于像素点之间的比较,但是其设计相较于Pico的二值比较来说更为复杂,其计算方式如下:

该特征有以下几个特点:
- 其特征是反对称的,也就是说 f (x, y) 或者f (y, x) 都可以表述 x 和 y 两点的特征,举个例子来说,对于一张 p = h*w 大小的图片,其特征池大小为 p * (p-1)/2 。
- 其特征是有符号的,也就是说其特征表述是有方向性的。
- 其特征是尺度鲁棒的, 也就是说由于其特征分子是两像素点差值,所以对于光照具有较强的鲁棒性。
- 其特征值是归一化的。
最后指出,通过特征池是可以重建出原图的,也就是说特征池包含了原图片中的所有信息。
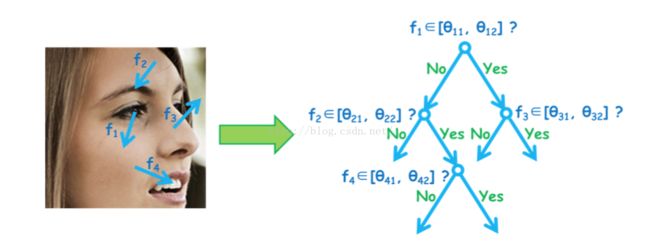
新的树形结构:深度二次树(Deep Quadratic Tree) :
以前的树形结构存在的局限,主要是以下两点:
- 没有获取到不同特征维度之间的联系。
- 简单的阈值设置忽略了其树内的分支流动顺序信息。
提出一种新的树内节点分裂计算方法:

其中,t为分裂阈值,联系一次二次方程的特性,通过设置系数,该函数用来检测x是否处于 [θ1 , θ2 ] 中, θ1 , θ2是两个已知的阈值,相比于 x < t 单边界比较, 该计算方法考虑到了两个边界 ,实现了一种更佳的分割策略。
由NPD这种特征设置,可以获得三种特征结构,分别是:
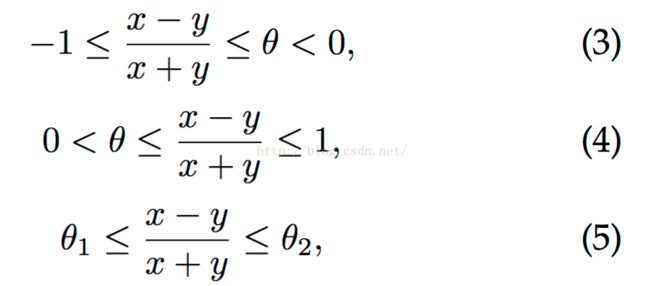
Eq(3)和Eq(4)分别表示了x的亮度低于y和x的亮度高于y(分别如下图f1和f2所示),这两种结构用传统的 x < t 这种方式就可以表达,但是对于Eq(5)来说, x < t 这种方式明显不可以,那么为何要提出Eq(5)这种结构呢?
如上图 f3 所示,对于脸部和背景图片的比较来说,其可能是脸部比背景暗也有可能比背景亮,所以单纯Eq(3)和Eq(4)这两种结构明显是不足以描述这种情况的,因此Eq(5)显得尤为重要,也因此要采用二次树这种结构。
在实践中,相比于 Eq(2)这种形式,更多的是将特征离散化到L大小的空间上(论文设置L=256),然后通过穷举找出两个最优阈值。
NPD算法实现
新的算法采用了新的架构模式,采用C++ 作为编程语言,之前的代码过于简单,pico代码中存在着多处使用全局变量,对内存消耗大的问题,新的代码结构更加清晰,注释更加完善,架构更加稳定。
不同于pico的Gentle-boost结构,NPD采用soft-cascade级连结构,在每一层过滤负例图片。
算法采用三层架构模式:
- 最外层是一个wraper,用于调用训练,图片检测与实时监测。
- 中间层是Detector容器,其成员变量包含了model信息,成员函数包含了窗口检测、模型读写,以及训练决策树stage的一系列操作。
- 最内层是单棵树的训练内核,代码精简高效,在训练过程中频繁掉用,迭代训练单棵树,最后组成检测器的多层stage。
三层架构之外,数据单独存储,不依托于任意一层,在每层之间传递调用,保持着良好的独立性,权值与得分以及图片信息分为正例负例分别保存,之间相互独立又有着一致的类型,使得操作简便,训练流畅。
配置文件也独立于所有文件之外,在整个程序中静态存在一个option类且不可修改,保证配置文件的统一性,并可在程序任意处读取。
类图:

重新训练模型
1、数据的选择
训练数据采用AFLW,对所有原图做变换,最终训练过程中生成20万正例,负例的生成采用之前生成的无人脸背景图替换掉AFLW所有人脸图片,每轮做随机采用,生成20万负例

左半部分为正例图片,右半部分为负例图片,所有负例会在负例图片上随机采样,最终所有图片都会被转为灰度格式。
2、参数设置
recall为1,不过滤掉任意正例图片,也就是说每一轮的阈值设置为正例最低score。
最大分类器数量为1500个。
每个弱分类器的深度最深为8层。
模版大小为24*24。
权重最大值为100。
每个弱分类器最小叶子数量为100。
3、训练环境
采用16核线下机训练,内存7G,单层训练时间大概为250秒,预计整个训练流程持续三到四天。
4、训练结果

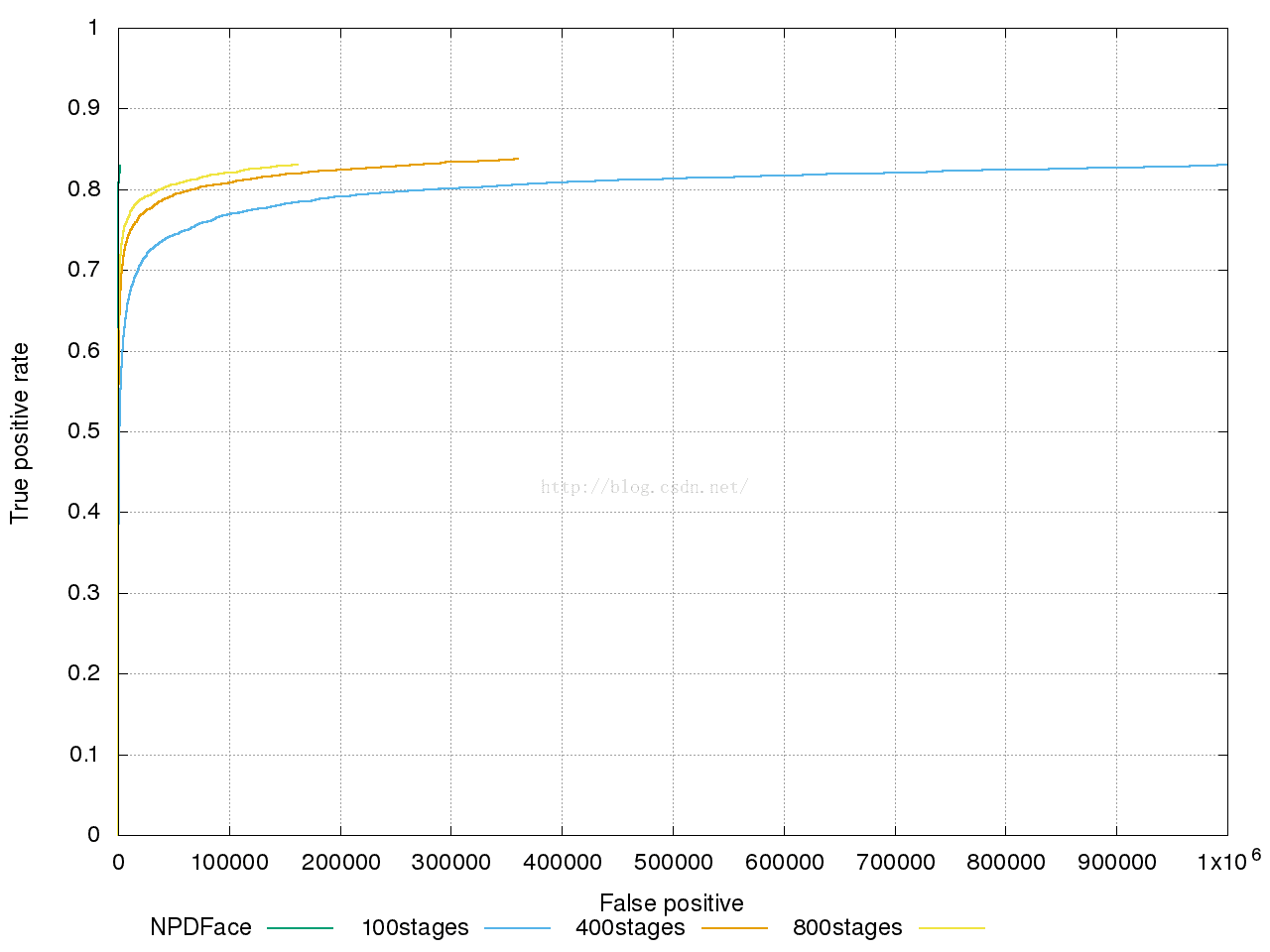
测试与调优
从结果来看,随着stage的增加,曲线正在收敛,但是收敛速度逐渐变慢,依次收敛速度,很难取得论文中模型的效果,推测问题出在负例采样上,因为采样方式采取随机patch,导致某些patch被多次采样,越到后期情况约为严重,所以导致了过拟合的情况,需要修改负例采样方式,降低负例拟合度,并重新训练模型。
改进:
1、修改mining策略为滑窗,随机尺度与步长。
2、初始负例采用hard样本。
模型训练结果:

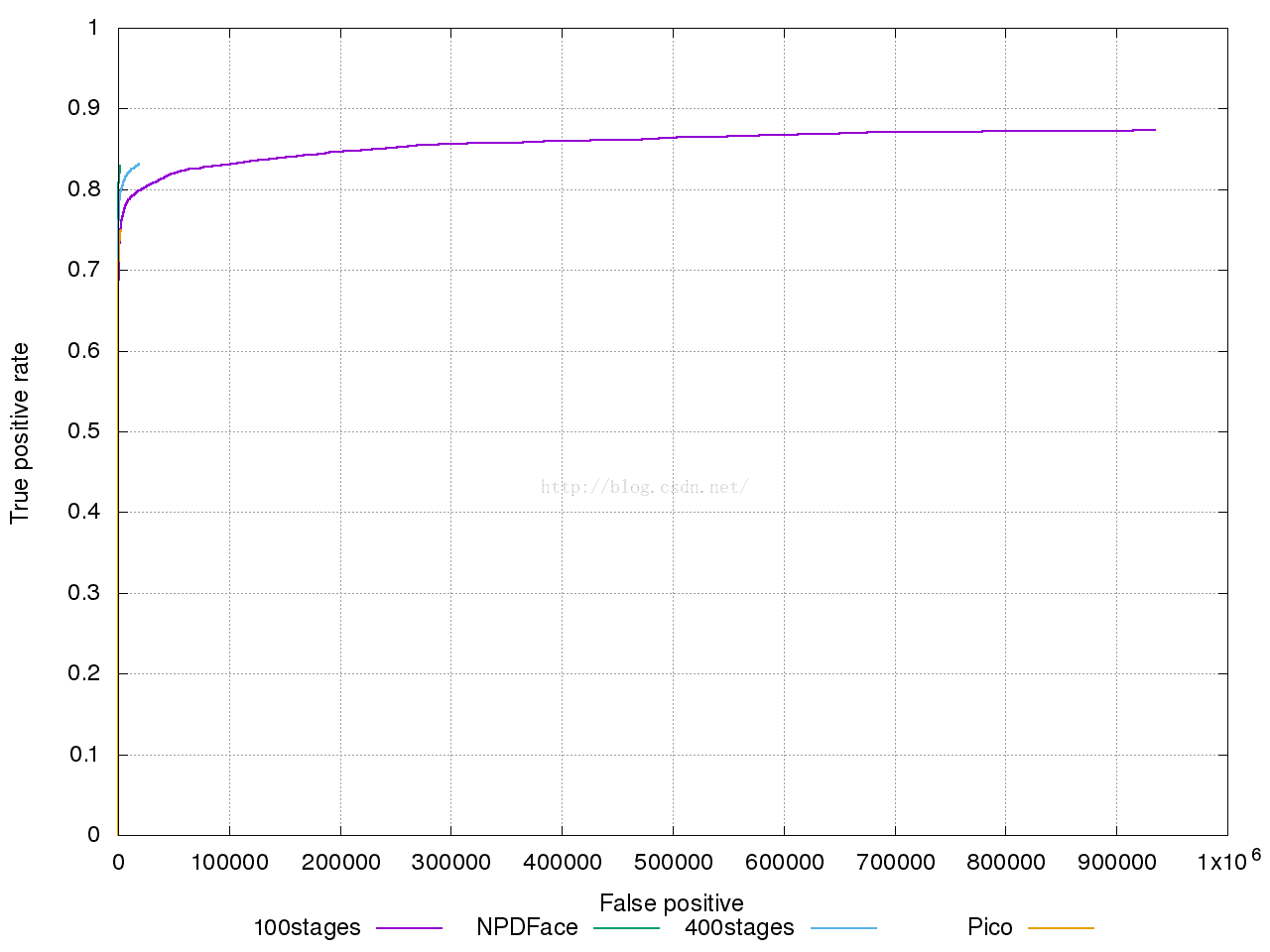
可以看到,结果有了明显改善,FP的收敛明显提高,但是FP在150时,提升速度很慢,有停滞趋势,且每轮mining时间过长,到后面stage的训练过程显得难以为继,并且由于初始的hard负例有拟合性,需要重新采集hard样本,修改mining策略为周期mining,重新训练。
最终训练结果:

最终的调优总结:
1、修改NMS算法,采用score作为权重,合并重合人脸区域,对最终的定位有明显帮助。
2、拟合人脸框为矩形可辅助曲线提升。
3、尽量采用指针,少用vector,减少数据拷贝,能有效提升检测速度。
最后附上Git地址:https://github.com/wincle/NPD