无人驾驶避障方法研究
引言
老师和学生的关系是建立在一份错觉上。老师错以为自己可以教学生什么,而学生错以为能从老师那里学到什么。重要的是,维持这份错觉对双方而言都是件幸福的事。因为看清了真相,反而一点好处都没有。我们在做的事,不过是教育的扮家家酒而已。——东野圭吾 《恶意》
无人驾驶避障综述
嗯,很惨,距离上次做 国内外无人驾驶技术相关调研没多久,就来做无人驾驶避障调研。为什么调研我要发博客呢,因为在我看来调研的结果给实验室看了,也没什么作用,还不如发篇博客,给有志于做这个方向的读者们一个参考。。。
话不多说,开始进入正题。首先我找了篇吉林大学汽车工程学院的文章,里面对无人驾驶避障方法做了一个总结。文章发表时间是16年10月,还算挺“新”的一篇文章,有点参考价值。看完之后我想我们必须先要理解无人驾驶避障的含义,很明显我们根据无人驾驶避障的过程,可以将无人驾驶避障分成三个方面:
- 运动障碍物检测:对运动过程中环境中的运动障碍物进行检测,主要由车载环境感知系统完成。(很明显,从常识角度看,避开障碍物的第一步就是检测障碍物。)
- 运动障碍物碰撞轨迹预测:对运动过程中可能遇到的障碍物进行可能性评级与预测,判断与无人驾驶车辆的碰撞关系。(当你检测到障碍物后,你就得让机器判断是否会与汽车相撞)
- 运动障碍物避障:通过智能决策和路径规划,使无人驾驶车辆安全避障,由车辆路径决策系统执行。(判断了可能会与汽车发生碰撞的障碍物后,你就得去让机器做出决策来避障了)
接下来我们将会从这三个方面来大致阐述现如今都有哪些方法。
运动障碍物检测方法
其实运动障碍物检测这部分呢,要是看过我前面提到的调研就会明白,运动障碍物检测根据他们的sensor主要分成两类:
- 一种是基于激光雷达和毫米波雷达的
- 一种是基于立体视觉的
基于激光雷达
那么根据激光雷达的检测方法主要有三种:
地图差分法。地图差分法是指根据地图上不同障碍物在不同时刻的状态来分析障碍物分布,得到运动信息。有篇文章提出了动态环境中基于时空关联属性的动静态障碍实时检测方法。将不同时刻环境感知传感器的读数统一转换到世界坐标系中,分析障碍的时间属性和空间属性,就能够识别动态障碍和静态障碍。该方法不需要将传感器读数映射到栅格地图上,节省了存储和计算时间,提高了障碍识别效率。
实体类聚法。实物类聚法通过将激光雷达收集到的数据进行分类,将运动障碍物的实体信息根据分类进行汇总,每一个障碍物实体状态信息由很多个类别中的信息组成,从而对其进行一些状态描述
- 目标跟踪法。目标跟踪法指对障碍物进行轨迹跟踪从而获得运动信息。由于在多目标环境下数据的关联性和激光雷达传感器的必然误差,不同时刻的目标关联需要按情况分类讨论。
总之这个基于激光雷达的障碍物检测方法有个致命的缺陷就是成本高,优点就是精度高,哈哈哈~
基于立体视觉
近几年,计算机视觉很火,在无人驾驶障碍物检测这块也有很大的应用。但是讲道理,计算机视觉算是人工智能领域技术性很强的一块工作了。在过去的几年里,很多基于2D/3D视觉的传感器技术都被提出来应用到各种场景与应用中,也有不少文章对此做了许多针对新的阐述。比如说ITSC2014中有篇文章针对障碍物检测这个方向主要被分成了四类方法:
第一类是probabilistic occupancy maps,由ELFES首次提出。
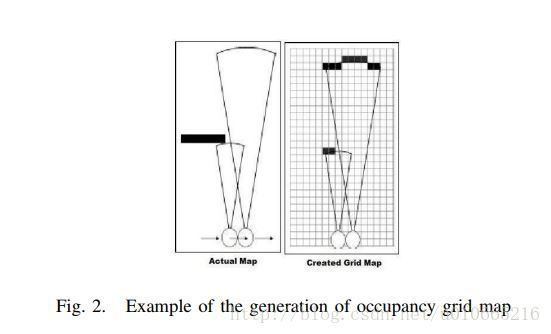
这个方法就是把机器眼中的世界,看成由很多小网格组成的大网格,该算法的目的就是来计算不同时间刻度下这些网格连接之间的相关性。具体算法,有兴趣地大家可以去看看(我是没兴趣的)第二类是digital elevation map,简称DEM。乍一看这个其实挺出名的,以前我们在学地理课时就常常看到这样的缩写,但是人家是digital elevation model,其实本质上是一样的,这是一个基于高度的网格表示法。如下图所示:
- 第三类叫做scene flow segmentation或者叫做光流更贴切些。毋庸置疑,做无人驾驶视觉相关算法的人应该都知道这个算法,很火。Optical Flow是图片序列或者视频中像素级的密集对应关系,例如在每个像素上估算一个2维的偏移矢量,得到的Optical Flow以2维矢量场表示。这个方法我个人感觉比较成熟了,毕竟CNN的优势摆在那里呢。感兴趣的人可以去看看ECCV2016 ,里面有训练CNN快速且准确地得到2维偏移矢量场的相关信息。
- 最后一类就是基于几何的聚类方法,这种方法就是对三维空间中点云形成的几何形状做聚类。这种方法简单迅速,也有不少文章做了相关评估,感兴趣的请戳:传送门。
就比如说人家斯坦福在2015年发表的一篇文章里就提出了用两个360度的摄像头来做障碍物检测。这个思想就是受到基于几何的聚类方法的启发。

上图被黄色覆盖的几何形状就是障碍物。


运动障碍物碰撞轨迹预测
前面我们从障碍物的表达及识别,讲述了四个国内外应用的方法。接下来我们来谈谈运动障碍物碰撞轨迹的预测。我想其实这个小标题应该改成运动障碍物的追踪。这个部分其实是与前面一部分障碍物的检测识别分不开的。无人车的感知系统需要实时识别和追踪多个运动目标(Multi-ObjectTracking,MOT),例如车辆和行人。物体识别是计算机视觉的核心问题之一,最近几年由于深度学习的革命性发展,计算机视觉领域大量使用CNN,物体识别的准确率和速度得到了很大提升,但总的来说物体识别算法的输出一般是有噪音的:物体的识别有可能不稳定,物体可能被遮挡,可能有短暂误识别等。自然地,MOT问题中流行的Tracking-by-detection方法就要解决这样一个难点:如何基于有噪音的识别结果获得鲁棒的物体运动轨迹。在ICCV 2015会议上,斯坦福大学的研究者发表了基于马尔可夫决策过程(MDP)的MOT算法来解决这个问题。
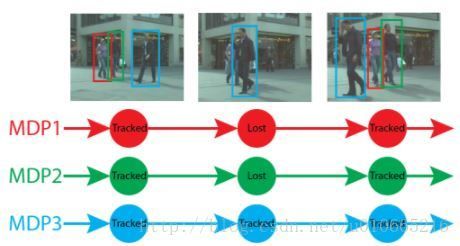
上面ICCV2015里面有一个demo视频,挺有意思的,感兴趣的可以点开看看。
运动障碍物避障
这个运动障碍物的避障,我想本质上它是一个路径规划的过程:在路段上有未知障碍物的情况下,按照一定的评价标准,寻找一条从起始状态到目标状态的无碰撞路径。路径规划分为两大类,全局规划与局部规划。为了提高全局重规划计算效率,一般在全局规划之外增加局部规划以提高规划系统的实时性。全局规划指已知全局环境信息,在有障碍物的全局地图中按照某种算法寻找合适的从起始位置到目标位置的无障碍无碰撞路径。局部路径规划是指在无法取得全局环境信息的情况下,只能利用多种传感器来获取移动机器人自身的状态信息的周围的局部环境信息,实时地规划理想的不碰撞局部路径,一般只在短时间内有效。势场法、模糊逻辑法、神经网络法、占据栅格法、空间搜索法和基于数据融合的直接规划方法。我们看下面这张图:
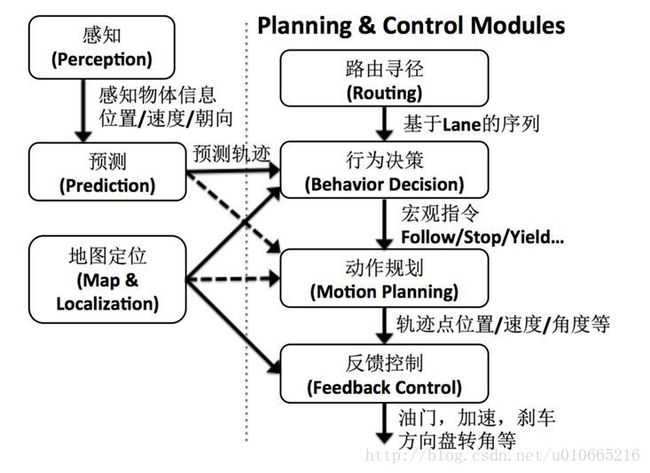
上图展示了一种无人车软件系统的典型功能模块划分。其中路径规划基本cover整个功能模块。因此这一部分涉及的内容超多。我们这次障碍物避障调研主要focus在感知、预测、地图定位、路径寻由及行为决策模块。
预测
预测模块的作用是对感知所探测到的物体进行行为预测,并且将预测的结果具体化为时间空间维度的轨迹传递给下游模块:行为决策模块。然后行为决策模块结合路由寻径模块从而进行行为决策。整个过程如下如所示:
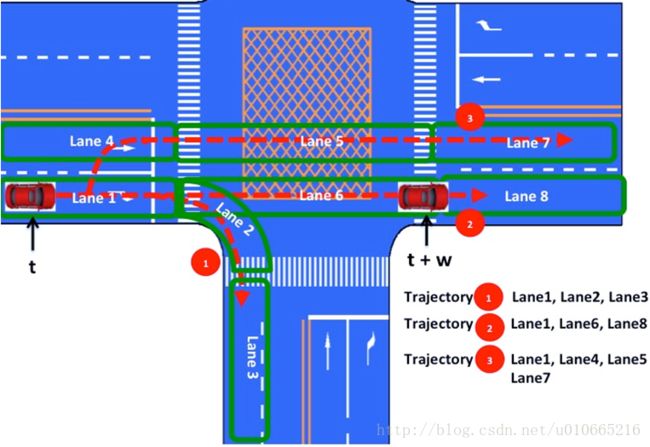
上面我们可以看到,这个行为决策就是咱们机器学习上的多分类选择问题。在t时刻的情况下,有路由寻径模块给出三个选择:
- lane1、lane2、lane3
- lane1、lane6、lane8
- lane1、lane4、lane5、lane7
这些选择就是结合高精地图的全局规划,然后再通过汽车周边传感器感知的信息进行局部规划,从而判断汽车是否右转、直行or并道。
路径寻由
前面我们将预测模块时,提到了路径寻由的模块。路径寻由本质上就是咱们数据结构算法里学到的A点到B点的路由问题。这个咱们不细讲了。路由寻径问题可以利用常见的A*搜索算法或者Dijkstra最短路径算法来进行实现。
行为决策
无人车的行为决策模块是一个信息汇聚的地方。由于需要考虑如此多种不同类型的信息以及受到非常本地化的交规限制,行为决策问题往往很难用一个单纯的数学模型来进解决。往往更适合行为决策模块的解决方法,是利用一些软件工程的先进观念来设计一些规则引擎系统。例如在DARPA无人车竞赛中,Stanford的无人车系统“Junior”利用一系列cost设计和有限状态机(Finite State Machine)来设计无人车的轨迹和操控指令。在近来的无人车规划控制相关工作中,基于马尔可夫决策过程(Markov Decision Process)的模型也开始被越来越多得应用到无人车行为层面的决策算法实现当中。简而言之,行为决策层面需要结合路由寻径的意图,周边物体和交通规则,输出宏观的行为层面决策指令供下游的动作规划模块去更具体地执行。其具体的指令集合设计则需要和下游的动作规划模块达成一致。
总结
嗯,讲道理,我自己都不知道做这些调研有啥用,某些人总以为我很闲,其实我是真的很忙啊,这年头想安心学些技术都不行,烦。。。
Reference
1.朱麒融. 无人驾驶汽车避障方法探析[J]. 科技资讯, 2016, 14(21):53-54.
2.肖正. 动态环境中移动机器人的时空关联地图构建的研究[D]. 中南大学, 2007.
3.Obstacle Avoidance Using Stereo Vision: A Survey
4.Bernini N, Bertozzi M, Castangia L, et al. Real-time obstacle detection using stereo vision for 5.autonomous ground vehicles: A survey[C]// IEEE International Conference on Intelligent Transportation Systems. IEEE, 2014:873-878.
6.Tapaswi M, Zhu Y, Stiefelhagen R, et al. MovieQA: Understanding Stories in Movies through Question-Answering[J]. 2016:4631-4640.
7.Bai M, Luo W, Kundu K, et al. Exploiting Semantic Information and Deep Matching for Optical Flow[C]// European Conference on Computer Vision. Springer International Publishing, 2016:154-170.
8.Broggi A, Buzzoni M, Felisa M, et al. Stereo obstacle detection in challenging environments: The VIAC experience[C]// Ieee/rsj International Conference on Intelligent Robots and Systems. IEEE, 2011:1599-1604.
9.Obstacle detection using stereo vision for self-driving cars
10.https://en.wikipedia.org/wiki/DARPA_Grand_Challenge