HADOOP:mapreduce的核心知识
Hadoop的核心是mapreduce和hdfs。
mapreduce
什么是mapreduce ?
MapReduce是一种编程模型,用于大规模数据集的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对(Mapper的输入键值)映射成一组新的键值对(Mapper的输出键值),指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组(即相同的键的数据发送到同一个reduce上,并进行合并处理)。
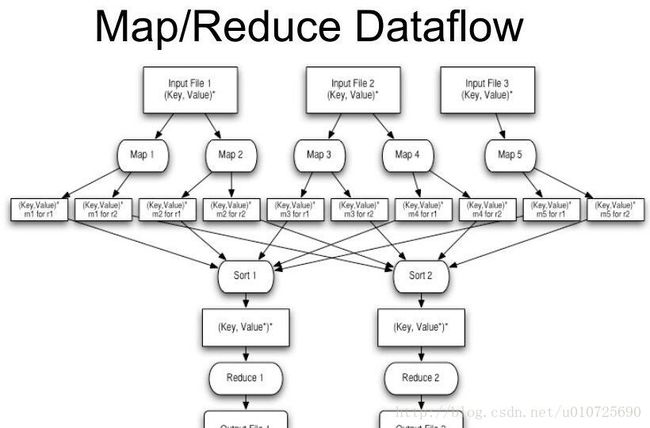
映射和化简
简单说来,一个映射函数就是对一些独立元素组成的概念上的列表。事实上,每个元素都是被独立操作的。这就是说,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并(key 相同的合并).
分布可靠
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的返回它所完成的工作和最新的状态。如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同Google File System中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。(避免副作用)。
化简操作工作方式与之类似,但是由于化简操作的可并行性相对较差,主节点会尽量把化简操作只分配在一个节点上,或者离需要操作的数据尽可能近的节点上。
Mapreduce的工作原理是什么?

一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
1.MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2.user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
3.被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
4.缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
5.master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6.reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7.当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
Mapreduce的工作流程是什么?
Map -> Reduce
MapReduce其实是分治算法的一种实现,所谓分治算法就是“就是分而治之”,将大的问题分解为相同类型的子问题(最好具有相同的规模),对子问题进行求解,然后合并成大问题的解。MapReduce就是分治法的一种,将输入进行分片,然后交给不同的task进行处理,然后合并成最终的解。具体流程图如下:

MapReduce实际的处理过程可以理解为Input->Map->Sort->Combine->Partition->Reduce->Output。
(1)Input阶段 数据以一定的格式传递给Mapper,有TextInputFormat,DBInputFormat,SequenceFileFormat等可以使用,在Job.setInputFormat可以设置,也可以自定义分分片函数。
(2)Map阶段 对输入的key,value进行处理,即map(k1,v1) -> list(k2,v2),使用Job.setMapperClass进行设置。
(3) Sort阶段 对于Mapper的输出进行排序,使用Job.setOutputKeyComparatorClass进行设置,然后定义排序规则
(4) Combine阶段 这个阶段对于Sort之后有相同key的结果进行合并,使用Job.setCombinerClass进行设置,也可以自定义Combine Class类。
(5) Partition阶段 将Mapper的中间结果按照Key的范围划分为R份(Reduce作业的个数),默认使用HashPatitioner(key.hashCode() & Integer.MAX_VALUE) % numPartitions),也可以自定义划分的函数。使用Job.setPartitionClass进行设置。
(6) Reduce阶段 对于Mapper的结果进一步进行处理,Job.setReducerClass进行设置自定义的Reduce类。
(7) Output阶段 Reducer输出数据的格式。
Mapreduce的编程模型是什么?

MapReduce将作业的整个运行过程分为两个阶段:Map阶段和Reduce阶段
Map阶段由一定数量的Map Task组成
输入数据格式解析:InputFormat
输入数据处理:Mapper
数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task组成
数据远程拷贝
数据按照key排序
数据处理:Reducer
数据输出格式:OutputFormat

InputFormat
InputFormat 负责处理MR的输入部分.
有三个作用:
1验证作业的输入是否规范.
2把输入文件切分成InputSplit. (处理跨行问题)
3提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理.
InputFormat类的层次结构:

Split与Block
Split与Block简介
Block: HDFS中最小的数据存储单位,默认是128MB
Split: MapReduce中最小的计算单元,默认与Block一一对应
Block与Split: Split与Block是对应关系是任意的,可由用户控制.
InputSplit 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
TextInputFormat
1.TextInputformat是默认的处理类,处理普通文本文件。
2.文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
3.默认以\n或回车键作为一行记录。
4.TextInputFormat继承了FileInputFormat。
其他输入类
- CombineFileInputFormat 相对于大量的小文件来说,hadoop更合适处理少量的大文件。CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
- KeyValueTextInputFormat 当输入数据的每一行是两列,并用tab分离的形式的时候, KeyValueTextInputformat处理这种格式的文件非常适合。
- NLineInputformat NLineInputformat可以控制在每个split中数据的行数。
- SequenceFileInputformat 当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat作为输入。
- 等等。。。具体可查看InputFormat 接口的实现类。
Combiner

每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量,因为从map端到reduce端会涉及到网络IO(文件传输)。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能,合并相同的key对应的value(wordcount例子),通常与Reducer逻辑一样。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
好处:①减少Map Task输出数据量(磁盘IO)②减少Reduce-Map网络传输数据量(网络IO)
【注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔(可有可无)的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。】
Partitioner
Partitioner决定了Map Task输出的每条数据交给哪个Reduce Task处理
默认实现:HashPartitioner是mapreduce的默认partitioner。计算方法是 reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。(hash(key) mod R 其中R是Reduce Task数目)
允许用户自定义 很多情况需自定义Partitioner比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理
Reduce的输出
TextOutputformat 默认的输出格式,key和value中间值用tab隔开的。
SequenceFileOutputformat 将key和value以sequencefile格式输出。
SequenceFileAsOutputFormat 将key和value以原始二进制的格式输出。
MapFileOutputFormat 将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
MultipleOutputFormat 默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。(还可以自定义输出格式,序列化会说到)
MapReduce编程模型总结
1.Map阶段
InputFormat(默认TextInputFormat)
Mapper
Combiner(local reducer)
Partitioner
2.Reduce阶段
Reducer
OutputFormat(默认TextOutputFormat)
shuffle是什么?

系统执行排序的过程(即将map输出作为输入传给reduce),称为shuffle.即这张图是官方对Shuffle过程的描述,hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心(心脏)。shuffle的主要工作是从Map结束到Reduce开始之间的过程。首先看下这张图,就能了解shuffle所处的位置。图中的partitions、copy phase、sort phase所代表的就是shuffle的不同阶段(大致范围)。也可以这样理解, Shuffle描述着数据从map task输出到reduce task输入的这段过程。
map 端的Shuffle细节:
1. 在map task执行时,它的输入数据来源于HDFS的block。(map函数产生输出时,利用缓冲的方式写入内存,并出于效率考虑的方式就行预排序。如上图。此处默认的内存大小为100M,可通过io.sort.mr 来设置,当此缓冲区编程 %80的时候 ,一个后台线程就会将内容写入磁盘。在写入磁盘之前,线程首先根据最终要传的reduce把这些数据划分成相应的分区(partition),在每个分区中,后台线程进行内排序,如果有combine,就会在排序后的分区内执行。)
在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对:相同的key 到底应该交由哪个reduce去做,是现在决定的,也就是partition 作用。MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。key/value对以及Partition的结果都会被写入缓冲区,当然写入之前,key与value值都会被序列化成字节数组。
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge(合并),也最终形成一个文件作为reduce task的输入文件。

在将压缩的map输出进行压缩是个好主意,默认情况下,是不压缩的,若启用压缩,需要手动配置将mapred.compress.map.output 设置为true,并配置mapred.compress.map.codec 。
reduce 端的Shuffle细节:
- Copy过程,简单地拉取数据。reduce 通过http的方式得到输出文件的分区。
- Merge阶段
- reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge(合并),也最终形成一个文件作为reduce task的输入文件。
partition是什么?
Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出.partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。这里其实可以理解归类。
Mapper的结果,可能送到Combiner做合并,Combiner在系统中并没有自己的基类,而是用Reducer作为Combiner的基类,他们对外的功能是一样的,只是使用的位置和使用时的上下文不太一样而已。Mapper最终处理的键值对
int getPartition(Text key, Text value, int numPartitions) ;就是指定Mappr输出的键值对到哪一个reducer上去。系统缺省的Partitioner是HashPartitioner,它以key的Hash值对Reducer的数目取模,得到对应的Reducer。这样保证如果有相同的key值,肯定被分配到同一个reducre上。如果有N个reducer,编号就为0,1,2,3……(N-1)。
combiner是什么?
combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义的。combine函数把一个map函数产生的<\key,value>对(多个key,value)合并成一个新的<\key2,value2>.将新的<\key2,value2>作为输入到reduce函数中这个value2亦可称之为values,因为有多个。这个合并的目的是为了减少网络传输。具体实现是由Combine类。
他们三者之间的关系是什么?
map的个数由谁来决定,如何计算?
在map阶段读取数据前,FileInputFormat会将输入文件分割成split。split的个数决定了map的个数。块大小、文件大小、文件数、以及splitsize大小有关。
影响map个数,即split个数的因素主要有:
1)HDFS块的大小,即HDFS中dfs.block.size的值。如果有一个输入文件为1024m,当块为256m时,会被划分为4个split;当块为128m时,会被划分为8个split。
2)文件的大小。当块为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
3)文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为128m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
4)splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节。
map个数的计算公式如下:
splitsize=max(minimumsize,min(maximumsize,blocksize))。如果没有设置minimumsize和maximumsize,splitsize的大小默认等于blocksize
reduce个数由谁来决定,如何计算?
当setNumReduceTasks( int a) a=1(即默认值),不管Partitioner返回不同值的个数b为多少,只启动1个reduce,这种情况下自定义的Partitioner类没有起到任何作用。
若a!=1: 当setNumReduceTasks( int a)里 a设置小于Partitioner返回不同值的个数b的话:比如说自定义的partitioner 返回10,但setNumReduceTasks(2) 这样就会抛出异常
java.io.IOException: Illegal partition某些key没有找到所对应的reduce去处。原因是只启动了a个reduce。
3. 同样,若partitioner 返回1(比如key设置为 NullWritable的时候),而设置了10个reduce,setNumReduceTasks(10),那么此时就会出现 结果文件为10个,只有一个有数据,其余九个为空文件。所以,reduce的个数可以自定义,但是计算的时候最好是和partitioner时一样,最好相差不要太多。
本文参考:
1. 百度百科
2. Hadoop权威指南第三版
3. http://blog.csdn.net/gaijianwei/article/details/45951695
4. http://blog.csdn.net/a1223031949/article/details/52741350
5. http://www.tuicool.com/articles/uaQVjqm