Java Web SSH-Hibernate框架复习
Java Web SSH-Hibernate框架复习
四. Hibernate入门
1. 框架的概念:
是一个提供了可重用的公共结构的半成品。提供了可重用的设计。
保证了程序结构的风格统一,在结构统一和创造力之间维持一个平衡点。
2.
数据持久化:

是将内存中的数据模型转换为存储模型,又或将存储模型转换为内存中的数据模型的统称。文件保存和数据读取都属于持久化操作。
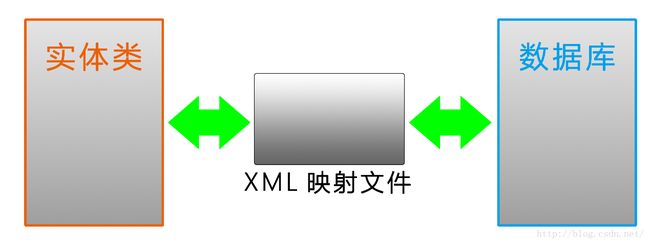
3. ORM:
对象/关系映射。在对象模型和关系型数据库之间建立对应关系。通过JB(Java Bean)操作数据库表中的数据。
4. Hibernate框架的优缺点:
优点:
1) 功能强大,是Java App与数据库之间的桥梁,和JDBC相比代码量减少,提高了开发速度,节约了成本;
2) 支持OO(Object Oriented-面向对象)特性;
3) 可移植性好,由于几乎没有手动编写SQL语句,则更换数据库后通常仅需要修改Hibernate的配置文件即可;
4) 开源。
缺点:
1) 不适合大量运用存储过程;
2) 大量的增删改不适合使用Hibernate;
3) 不适用于小型项目。
5. Hibernate开发环境的配置:
需要配置hibernate-config.xml文件及其数据库对应到Java应用程序中的hbm.xml(数据表实体映射文件)。
具体配置步骤请移步百度云 。
Hibernate配置文件位于项目src根目录下;持久化类对应的映射文件位于和持久化类同目录下。
Hibernate配置文件结构:
org.hibernate.dialect.Oracle9Dialect
jdbc:oracle:thin:@localhost:1521:orcl
scott
admin
oracle.jdbc.driver.OracleDriver
scott
true
true
Hibernate映射文件结构:
以部门表Dept为例:
6.可以使用HibernateUtil或HibernateSessionFactory获取Session对象来操作数据库。
7.使用Hibernate实现按主键查询:
进行修改或删除时,需要先根据(主键)编号加载对象到内存中,可以使用get()或load()方法。
两者比较:
|
|
|
get() |
load() |
| 相同点 |
都是用于加载对象到内存中的 |
||
| 延迟加载下在类级别中总是立即加载 |
|||
| 不同点 |
若数据不存在 |
返回NULL |
抛出ObjectNotFoundException异常 |
| 执行后的返回值情况 |
要么返回所查询的对象,要么返回NULL |
代理类的对象 |
|
Hibernate在增删改操作时都需要在事务环境中完成,要注意最后的事务提交和失败后的事务回滚。
8. Hibernate中Java对象的三种状态:
瞬时状态
在内存中孤立的存在,是携带信息的载体,不和数据库的数据有任何关系。
持久状态
处于该状态的对象在数据库中具有对应的记录,并拥有一个持久化标识当使用delete()方法删除时,对应的持久化对象将转变为瞬时状态(因为数据库中与此对应的数据被删除了,该对象与数据库已没有任何的关系)
特点:
1) 与Session实例相关联;
2) 在数据库中由于其相关联的记录。
游离状态(脱管状态)
当与某持久化对象关联的Session对象被关闭、清空后,该持久化对象就会变为游离对象(脱管对象)。当游离对象(脱管对象)被重新关联上Session之后,又会变为持久对象。
特点:
1) 本质上与瞬时对象相同;
2) 在无任何变量引用时,JVM会将其回收;
3) 比瞬时对象多了一个与数据库中记录对应的标识值。
9. 三种状态之间的互相转换:

10. 脏检查和刷新缓存
状态前后发生变化的对象,在Hibernate中称为“脏对象”。
在事务提交时会对Session缓存中处于持久状态的对象进行检测,判断对象是否发生了改变,这便称为“脏检查”。目的是为了内存中的对象与数据库中的数据保持一致。
当在调用commit()方法时,Hibernate会先调用Session的flush()方法刷新缓存,进行脏检查,然后再向数据库提交事务。
但并不需要显式地调用flush()方法进行事务的提交。
11. 更新数据的方法
update()
对游离状态的对象进行更新,没有OID时会抛出异常;
saveOrUpdate()
同时具有更新和插入的功能,根据传入的对象状态自动判断执行的方法;
merge()
在不影响Session缓存中数据的情况下将游离对象的属性复制一份到持久化对象中,然后进行操作。总之不会影响到源对象的状态。
注意:
当Session对象中有两个具有相同ID的实例时,使用update()方法更新数据会抛出异常。此时仅能使用merge()方法,它会覆盖其中一个实例,保留剩余的一个实例;
例:
UserInfou1 = new UserInfo(“张三”);
UserInfou1 = new UserInfo(“李四”);
session.update(u1);
session.update(u2);
上述代码会抛出异常,update()方法不允许出现两个具有相同ID的实例(都是UserInfo对象,那么在内存中的ID都一定是相同的,这样会抛出异常)
saveOrUpdate()方法执行后返回void;merge()方法执行后返回一个对象;
saveOrupdate()方法会自动判断对象是否被持久化过,若持久化过则更新此对象,否则将此对象插入到数据库中;
merge()方法替代了旧有的saveOrUpdateCopy()方法,原有对象和其副本都不受影响。
五. HQL实用技术
1. Hibernate支持三种查询方式:
HQL(Hibernate Query Language)【OO】(Object Oriented-面向对象)
Criteria(对象查询)【OO】(Object Oriented-面向对象)
原生SQL
Criteia适用于查询一个表中的数据;
HQL适用于查询多张表联合查询的数据;
原生SQL适用于当以上两种查询都不能满足实际情况时要采用的查询方式。
2. HQL语句的特性:
对查询语句的大小写不敏感,但对类的全限定名区分大小写(org.proj.Dept 和org.proj.DEPT代表的是不同的持久化类)。
3. HQL的查询语法规范:
在HQL中不支持直接将查询的条件列设为星号直接查询所有列,这样是不可取的,会抛出异常。因为HQL不是SQL语句。但支持在函数中的参数使用星号查询。
例:
Select * from Dept //这种写法不被HQL所支持,不允许直接单独写星号作为查询列
Select count(*) from Dept //这种写法可以被HQL所支持
查询部分列:
Select dept.dName from Dept dept
这句HQL语句查询了Dept持久化类中的dName的属性值,并为Dept这个持久化类起了别名为dept
4. 执行HQL语句
步骤:
1) 构造Session对象;
2) 构造HQL语句,存入String中;
3) 根据Session对象构造Query对象;
4) 调用Query对象的list()方法或iterate ()方法执行查询并返回结果。
使用list()和iterator()方法的区别:
|
|
|
list()方法 |
iterate()方法 |
| 不同点 |
查询机制 |
一次查出所有记录 |
首先查询符合条件的主键值,当实际需要这个主键值对应的数据时,才会继续查询 |
| 效率 |
效率低 |
效率高,省内存 |
|
| 相同点 |
都继承于Query接口,都用于查询HQL语句并返回相应的结果 |
||
5. HQL语句的参数绑定
| 支持绑定的形式 |
语法 |
示例 |
备注 |
| 按参数位置绑定 |
Query.setXXX(int index,Object parameter ) |
query.setString(0,”张三”) |
使用占位符(?)且索引从0开始 |
| 按参数名称绑定 |
Query.setXXX (“parameter name in HQL ”,Object parameter value ) |
query.setInteger(“deptNumber”,1) |
参数1代表在HQL语句中的明明参数的名称,参数2代表要传入的实际值 |
| 绑定各种类型的参数 |
Query.setParameter(int index /“parameter name in HQL ”, Object parameter value) |
query.setInteger(2,”Sales ”);(按位置) query.setInteger(“deptName”,”Sales ”);(按参数名)
|
当不确定参数是何种类型时使用,且可以按照位置和名称进行绑定 |
| Query.setProperties() |
DeptCondition dc = new DeptCondition(); dc.setDeptName(“销售部”); query.setProperties(dc ); |
绑定命名参数和一个对象的属性值(在要匹配的属性值较多的情况下使用) |
6. HQL的动态查询
思路:
动态查询肯定需要很多个条件的拼接,那么为了方便,所以需要建立一个专门存放查询条件的类,之后使用setProperties()方法设置到Query对象中去进行查询。
使用HQL动态查询代码(本段代码中并未使用到查询条件类,视情况而定):
packageChapt5_Computer_Practice3.Implements;
importjava.util.List;
importorg.hibernate.Query;
importorg.hibernate.Session;
importorg.hibernate.SessionFactory;
importorg.hibernate.cfg.Configuration;
importChapt5_Computer_Practice3.Hibernate.Entity.House;
importChapt5_Computer_Practice3.Tools.DateTimeTools;
/**
* 房屋业务类
*
* @author SteveJrong
*
*/
publicclass HouseBusiness {
/**
* 根据租金、联系人和发布日期获取房屋信息
*/
public void getInfoByZuJinAndContentAndPubDate(){
SessionFactory sessionFactory= null;
Session session = null;
// 创建Session工厂SessionFactory
sessionFactory = newConfiguration().configure().buildSessionFactory();
session =sessionFactory.openSession();
// 实例化House对象用于设置属性参数值
House h = new House();
// 设置House对象的价格属性
h.setPrice(2000);
// 设置House对象的联系人属性
h.setContact("张三");
// 设置House对象的发布日期属性
h.setPubdate(DateTimeTools.getThisYearsLastMonthDateTimes());
// 定义并拼接HQL语句
StringBuilder hql = new StringBuilder("fromHouse where 1=1");
// 当House对象的价格属性不为空时,则拼接关于价格的HQL语句
if (h.getPrice() != null) {
hql.append("and price < :price ");
}
// //当House对象的联系人属性不为空时,则拼接关于联系人的HQL语句
if (h.getContact() != null) {
hql.append("and contact = :contact ");
}
// //当House对象的发布日期属性不为空时,则拼接关于发布日期的HQL语句
if (h.getPubdate() != null) {
hql.append("and pubdate >= to_date('"
+DateTimeTools.getThisYearsLastMonthDateTimesOfString()
+"','yyyy-mm-dd') and pubdate <= to_date(to_char(sysdate,'yyyy-mm-dd'),'yyyy-mm-dd')");
}
// 创建Query对象,参数为拼接的HQL语句
Query query =session.createQuery(hql.toString());
// 调用Query对象的setProperties()方法绑定命名参数和对象的属性值
//House的对象h中封装了所要查询的各种条件
query.setProperties(h);
// 返回结果
List houseList =query.list();
System.out.println("编号\t标题\t\t描述\t\t价格\t发布日期\t\t\t面积\t联系人");
// 打印输出
for (House h2 : houseList) {
System.out.println(h2.getId()+ "\t" + h2.getTitle() + "\t"
+h2.getDescription() + "\t" + h2.getPrice() + "\t"
+h2.getPubdate() + "\t" + h2.getFloorage() + "\t"
+h2.getContact());
}
}
}
7. uniqueResult()获取唯一结果。其获取的结果要么是一个对象(查询一个唯一对象)要么是一个单一值(使用了聚合函数)。
8. HQL的分页
使用Query接口的setFirstResult()方法和setMaxResults()方法实现分页。
分页代码:
package Chapt5_Computer_Practice4.Hibernate.Implements;
importjava.util.List;
importorg.hibernate.Query;
importorg.hibernate.Session;
importChapt5_Computer_Practice4.Hibernate.Configurations.HibernateSessionFactory;
importChapt5_Computer_Practice4.Hibernate.Entity.Users;
/**
* 用户业务类
*
* @author SteveJrong
*
*/
publicclass UsersBusiness {
/**
* 使用分页显示房屋信息
*/
public voidgetHouseInfoUsingSplitPage() {
Session session =HibernateSessionFactory.getSession();
String hql = "from Usersorder by id";
Query query =session.createQuery(hql);
//query.setFirstResult((pageIndex- 1) * pageSize); //pageIndex表示当前页码;pageSize表示每页显示的条数
query.setFirstResult((1 - 1)* 3);
//query.setMaxResults(pageSize);
//pageSize表示每页显示的条数
query.setMaxResults(3);
List usersList =query.list();
for (Users u : usersList) {
System.out.println(u.getName());
}
}
}
9. HQL的投影查询
何时使用:
有时并不需要查询出全部的属性,而只需要查询某些属性就能满足需求时采用的查询方式。
其返回值是List
另一种投影查询方式:
HQL语句中实例化一个持久化类的对象:
String HQL=“select new Emp(empName,empSal)from Emp”;
Query =session.createQuery(HQL);
List
此时虽然查询的是多个列,但在HQL语句中实例化了要查询的持久化类的对象,并将查询的列作为参数传入到持久化类中去,那么查询出来的就是一类对象而不是Object[]类型的数据了。
10. 当涉及到两张(及以上)的表查询时,要使用Map集合来存储。
六. Hibernate关联映射
1. 针对关联映射,请参看另一篇文章:http://blog.csdn.net/u010737252/article/details/48180593
2. 针对延迟加载,请参看另一篇文章:http://blog.csdn.net/u010737252/article/details/48113557
3. 要点总结:
1) 关联关系应由字表来做为主动方负责;
2) 一对一、一对多的关联映射中,当在主表属性标签的inverse=false时,将由主表做为主动方负责维护关系。此时,与子表做为主动方的不同是,会在insert into外多加一句update语句进行子方数据的删除;
3) 主动方一般位于子表中(有特殊需求的情况除外),即子表中的inverse属性的值为false(或不写)。为什么要以子表作为主动方去维护表间关系呢?
解答:
因为当子表做出改变时,会通过外键引用主表,使得在主表中也获得一条数据;当父表(主表)主动维护关系时,由于主表仅有主键,因而一般情况检测不到有子表的存在,所以会多出语句来保证两表间的数据一致性。
4) 有Set集合的表明为双向关联,因为双向关联可以根据A类中引用的B类的属性而点(.)【面向对象】出B类的属性;
5) 没有Set集合的,但在A类(或B类)中有对方类的属性引用的,为单向关联;
6) 通常在“一”的一方有Set集合;在“多”的一方有引用另一方的对象;
7) 有实体的为“多对一”;有集合的为“一对多”。
七. Hibernate性能优化
1. 一对一关联映射
一对一映射的两种映射方式:
按照外键映射
按照主键映射
为了更好地理解一对一映射方式,举例说明两种映射方式的不同:
按照外键映射
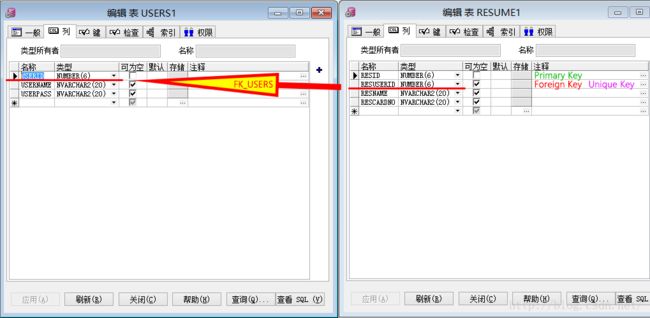
顾名思义,既然是外键映射,所以需要在某一张表中多余一列用于关联,以员工和档案为例的一对一关系进行举例说明。
表结构:
表结构分析:
在USERS1表中有一个主键USERID为员工的编号,除此之外并无其他主外键关系;
在RESUME1表中除了有主键RESID(档案编号)之外,还有一个列RESUSERID,它既是USERS1表的引用主键的外键,同时又是唯一约束,这样就能确保档案中的每一条记录都是唯一不重复的。
所以,在按照外键映射的情况下,键约束情况如下表所示:
| 表名称 |
USERS1 |
RESUME1 |
| 键约束 |
USERID主键 |
RESID主键 |
| - |
RESUSERID外键,参照USERS1表的USERID |
|
| - |
RESUSERID唯一键 |

两个类的关系:
Users1实体类:
packageEntity;
/**
* 员工实体
*
* @version 1.01 beta 2015-10-2 下午1:35:15
* @author Steve Jrong
*/
publicclass Users1 implements java.io.Serializable {
/**
* 员工编号
*/
private Integer userid;
/**
* 员工姓名
*/
private String username;
/**
* 员工密码
*/
private String userpass;
/**
* 在员工实体中引用的档案对象
*/
private Resume1 resume1;
// Constructors
/** default constructor */
public Users1() {
}
/** minimal constructor */
public Users1(Integer userid) {
this.userid = userid;
}
public Users1(Integer userid, String username,String userpass) {
this.userid = userid;
this.username = username;
this.userpass = userpass;
}
/** full constructor */
public Users1(Integer userid, String username,String userpass,
Resume1 resume1) {
this.userid = userid;
this.username = username;
this.userpass = userpass;
this.resume1 = resume1;
}
// Property accessors
public Integer getUserid() {
return this.userid;
}
public void setUserid(Integer userid) {
this.userid = userid;
}
public String getUsername() {
return this.username;
}
public void setUsername(String username) {
this.username = username;
}
public String getUserpass() {
return this.userpass;
}
public void setUserpass(String userpass) {
this.userpass = userpass;
}
public Resume1 getResume1() {
return this.resume1;
}
public void setResume1(Resume1 resume1) {
this.resume1 = resume1;
}
}Resume1实体类:
packageEntity;
/**
* 员工档案实体
*
* @version 1.01 beta 2015-10-2 下午1:31:55
* @author Steve Jrong
*/
publicclass Resume1 implements java.io.Serializable {
/**
* 档案编号
*/
private Integer resid;
/**
* 在档案实体中引用的员工对象
*/
private Users1 users1;
/**
* 档案名称
*/
private String resname;
/**
* 档案具体的内部编号
*/
private String rescardno;
// Constructors
/** default constructor */
public Resume1() {
}
/** minimal constructor */
public Resume1(Integer resid) {
this.resid = resid;
}
public Resume1(Integer resid, String resname,String rescardno) {
this.resid = resid;
this.resname = resname;
this.rescardno = rescardno;
}
/** full constructor */
public Resume1(Integer resid, Users1 users1,String resname,
String rescardno) {
this.resid = resid;
this.users1 = users1;
this.resname = resname;
this.rescardno = rescardno;
}
// Property accessors
public Integer getResid() {
return this.resid;
}
public void setResid(Integer resid) {
this.resid = resid;
}
public Users1 getUsers1() {
return this.users1;
}
public void setUsers1(Users1 users1) {
this.users1 = users1;
}
public String getResname() {
return this.resname;
}
public void setResname(String resname) {
this.resname = resname;
}
public String getRescardno() {
return this.rescardno;
}
public void setRescardno(String rescardno) {
this.rescardno = rescardno;
}
}配置文件:
Resume1持久化类对应的映射文件:
Users1持久化类对应的映射文件:
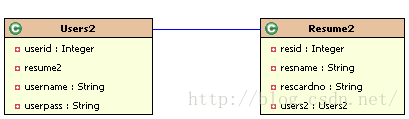
按照主键映射
表结构:
表结构说明:
在USERS2表中有一个主键USERID,除此之外这个主键还是一个外键,它参照了RESUME2表的主键RESID(USERS2表和RESUME表共享一个主键)。那么既然都共享一个主键了,那么也就保证了数据的不重复,一一对应的关系。
所以,在按照主键映射的情况下,键约束情况如下表所示:
| 表名称 |
USERS2 |
RESUME2 |
| 键约束 |
USERID主键 |
RESID主键 |
| USERID外键,参展RESUME2表的RESUID主键 |
- |
实体类:

两个类的关系:
实体类:
Users2持久化类:
packageEntity;
/**
* 员工实体类
*
* @version 1.01 beta 2015-10-2 下午4:11:35
* @author Steve Jrong
*/
publicclass Users2 implements java.io.Serializable {
/**
* 员工编号
*/
private Integer userid;
/**
* 在员工类中引用的员工档案对象
*/
private Resume2 resume2;
/**
* 员工姓名
*/
private String username;
/**
* 员工密码
*/
private String userpass;
// Constructors
/** default constructor */
public Users2() {
}
/** minimal constructor */
public Users2(Integer userid, Resume2 resume2){
this.userid = userid;
this.resume2 = resume2;
}
/** full constructor */
public Users2(Integer userid, Resume2 resume2,String username,
String userpass) {
this.userid = userid;
this.resume2 = resume2;
this.username = username;
this.userpass = userpass;
}
// Property accessors
public Users2(String string, String string2) {
// TODO Auto-generated constructorstub
this.username = string;
this.userpass = string2;
}
public Integer getUserid() {
return this.userid;
}
public void setUserid(Integer userid) {
this.userid = userid;
}
public Resume2 getResume2() {
return this.resume2;
}
public void setResume2(Resume2 resume2) {
this.resume2 = resume2;
}
public String getUsername() {
return this.username;
}
public void setUsername(String username) {
this.username = username;
}
public String getUserpass() {
return this.userpass;
}
public void setUserpass(String userpass) {
this.userpass = userpass;
}
}
Resume2持久化类:
packageEntity;
/**
* 员工档案持久化类
*
* @version 1.01 beta 2015-10-2 下午4:13:30
* @author Steve Jrong
*/
publicclass Resume2 implements java.io.Serializable {
/**
* 档案编号
*/
private Integer resid;
/**
* 档案名称
*/
private String resname;
/**
* 内部的档案编号
*/
private String rescardno;
/**
* 在员工档案中引用的员工对象
*/
private Users2 users2;
// Constructors
/** default constructor */
public Resume2() {
}
/** minimal constructor */
public Resume2(Integer resid) {
this.resid = resid;
}
/** full constructor */
public Resume2(Integer resid, String resname,String rescardno,
Users2 users2) {
this.resid = resid;
this.resname = resname;
this.rescardno = rescardno;
this.users2 = users2;
}
// Property accessors
public Resume2(String string, String string2,int i) {
this.resname = string;
this.rescardno = string2;
this.resid = i;
// TODO Auto-generated constructorstub
}
public Integer getResid() {
return this.resid;
}
public void setResid(Integer resid) {
this.resid = resid;
}
public String getResname() {
return this.resname;
}
public void setResname(String resname) {
this.resname = resname;
}
public String getRescardno() {
return this.rescardno;
}
public void setRescardno(String rescardno) {
this.rescardno = rescardno;
}
public Users2 getUsers2() {
return this.users2;
}
public void setUsers2(Users2 users2) {
this.users2 = users2;
}
}持久化类对应的映射文件:
Users2:
resume2
2. 组件的映射
为了尽可能的减少数据库表的数目和彼此之间的关系,则需要使用组件来代替。
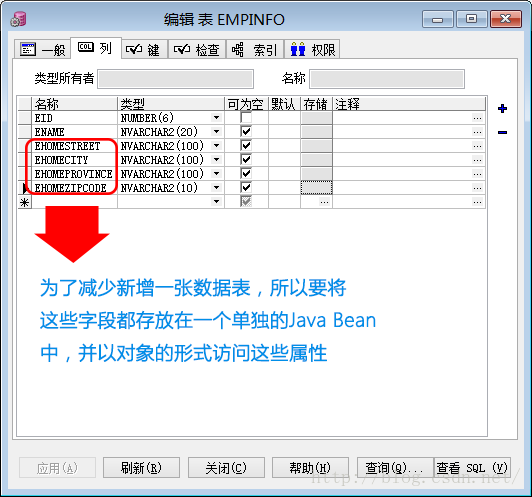
组建映射的包结构:
主类Empinfo和组件类EmpHomeAddress的具体实现:
Empinfo实体类:
packageEntity;
/**
* 员工信息实体类
*
* @version 1.01 beta 2015-10-2 下午5:10:25
* @author Steve Jrong
*/
publicclass Empinfo implements java.io.Serializable {
/**
* 员工编号
*/
private Integer eid;
/**
* 员工姓名
*/
private String ename;
/**
* ehome属性对应组件类EmpHomeAddress中的属性
*/
private EmpHomeAddress ehome;
// Constructors
public EmpHomeAddress getEhome() {
return ehome;
}
public void setEhome(EmpHomeAddress ehome) {
this.ehome = ehome;
}
/** default constructor */
public Empinfo() {
}
/** minimal constructor */
public Empinfo(Integer eid) {
this.eid = eid;
}
/** full constructor */
public Empinfo(Integer eid, String ename) {
this.eid = eid;
this.ename = ename;
}
public Empinfo(String ename) {
this.ename = ename;
}
// Property accessors
public Integer getEid() {
return this.eid;
}
public void setEid(Integer eid) {
this.eid = eid;
}
public String getEname() {
return this.ename;
}
public void setEname(String ename) {
this.ename = ename;
}
}Empinfo实体类对应的映射文件:
EmpHoneAddress组件类:
packageEntity;
/**
* 从Empinfo表中拆分打包的组件类
*
* @version 1.01 beta 2015-10-2 下午5:11:50
* @author Steve Jrong
*/
publicclass EmpHomeAddress {
/**
* 组件类中引用的主类的对象
*/
private Empinfo empinfo;
/**
* 所属街道
*/
private String ehomestreet;
/**
* 所在城市
*/
private String ehomecity;
/**
* 所在省
*/
private String ehomeprovince;
/**
* 所在地区的邮政编码
*/
private String ehomezipcode;
public Empinfo getEmpinfo() {
return empinfo;
}
public void setEmpinfo(Empinfo empinfo) {
this.empinfo = empinfo;
}
public String getEhomestreet() {
return ehomestreet;
}
public void setEhomestreet(String ehomestreet){
this.ehomestreet = ehomestreet;
}
public String getEhomecity() {
return ehomecity;
}
public void setEhomecity(String ehomecity) {
this.ehomecity = ehomecity;
}
public String getEhomeprovince() {
return ehomeprovince;
}
public void setEhomeprovince(Stringehomeprovince) {
this.ehomeprovince = ehomeprovince;
}
public String getEhomezipcode() {
return ehomezipcode;
}
public void setEhomezipcode(Stringehomezipcode) {
this.ehomezipcode = ehomezipcode;
}
}
组件类的特征:
1) 组件类(EmpHomeAddress类)没有OID(对象标识符),在数据库中也没有对应的表,且不需要创建它的映射文件;
2) 组件类(EmpHomeAddress类)的生命周期依赖主类(Empinfo类)的生命周期;
3) 其他持久化类不允许再继续关联当前已被关联(作为某一个类的组件)的组件类。但组件类可以继续关联其他的持久化类。
3. Hibernate缓存
Hibernate缓存的分类:

一级缓存的作用:
1) 减少应用程序对数据库的访问频率;
2) 保证缓存中的数据与数据库的数据保持一致。
如何配置二级缓存?
1) 添加ehcache.xml文件,放于src目录下:
2) 在已有的Hibernate配置文件中加入以下元素及其属性:
true
org.hibernate.cache.EhCacheProvider
3) 在要设置缓存的持久化类对应的配置文件中,为
usage=”transactional(事务缓存)/read-wirte(读和写缓存)/nonstrict-read-write(非严格的读和写缓存)/read-only(只读缓存)”。
1. 何时使用二级缓存?
1) 很少修改的数据;
2) 非关键数据;
3) 常量数据。
2. 以下情况不适合使用二级缓存:
1) 经常修改的数据;
2) 财务方面的数据;
3) 与其他应用共享的数据。
3. HQL查询
HQL支持的查询类型:
| 连接类型 |
HQL语法 |
适用范围 |
| 内连接 |
inner join/join |
适用于有关联关系的持久化类,并在映射文件中做了相应的映射 |
| 迫切内连接 |
inner join fetch/join fetch |
|
| 左外连接 |
left outer join/left join |
|
| 迫切左外连接 |
left outer join fetch/left join fetch |
|
| 右外连接 |
right outer join/right join |
*当使用了迫切连接之后,延迟加载就会失效。
知识拓展:
笛卡儿积:
集合x和集合y的乘积。
集合A={1,2};
集合B={a,b,c};
集合为:CP={(1,a),(1,b),(1,c),(2,a),(2,b),(2,c)};
4. Hibernate的查询性能优化:
| 性能优化项 |
Query接口的list()方法 |
Query接口的iterate()方法 |
| 查询数据优选 |
√ |
|
| 使用/不使用的原因 |
list()方法尽管在查询时若没数据会放到session缓存中去,但每次查询都不从session中取数据而是每次和数据库交互 |
iterate()方法不会发送大量的SQL语句一次性查询出来所有数据,而是先查询出符合条件的编号,然后根据实际情况再继续查询;而且首次放入session缓存中后每次都从缓存中抽取数据(如果有数据的话) |
针对HQL的优化策略:
1) 避免使用not关键字,尽量使用逻辑运算符代替;
2) 谨慎使用or关键字;
3) 谨慎使用having子句(若要使用最好在where条件中加入查询条件,在having中加入条件会将已经查询好的数据进行处理,这段时间可能耗时较长);
4) 谨慎使用district关键字(处理重复行也可能耗时较长)。
5. 批量处理数据
| 处理方式 |
特性 |
优点 |
备注 |
| HQL |
直接操作数据库,没有session缓存参与 |
跨数据库的;面向对象的;局限性:不支持连接和子查询,只能用于单个类 |
使用Query接口的executeUpdate()方法执行增删改 |
| JDBC API |
有Session对象与session缓存参与 |
最灵活 |
使用Session的doWork()方法执行Work对象的execute()方法进行操作 |
| Session |
使用Session的 |
将关系数据加载到内存中操作,适于处理复杂的业务 |
处理完一小批数据后要注意调用Session对象的flush()和clear()方法同步数据 |
八. Hibernate数据操作技巧
1. 聚合函数
count() - 计数。注意:返回值为long类型的,而不是int类型;
sum() - 求和。注意:返回值为double类型的,而不是int类型;
min() - 求最小值。注意:返回值为double类型的,而不是int类型;
max() - 求最大值。注意:返回值为double类型的,而不是int类型;
avg() - 求平均值。注意:返回值为double类型的,而不是int类型。
2. 分组查询
HQL也支持SQL中的分组查询(使用面向对象的方式)。
3. 子查询
HQL中子查询的关键字:
| HQL子查询关键字 |
备注 |
| all |
子查询返回所有记录 |
| any |
子查询返回任意一条记录 |
| some |
子查询返回任意一条记录 |
| in |
子查询返回任意一条记录 |
| exists |
子查询至少要有一条记录 |
4. 集合操作
HQL支持更高级的集合函数或属性。
| HQL集合操作函数/属性 |
备注 |
| size()/size |
获取集合中的元素数 |
| minIndex()/minIndex |
针对有索引的集合,获取最小的索引 |
| maxIndex()/maxIndex |
针对有索引的集合,获取最大的索引 |
| minElement()/minElement |
获取集合中值最小的元素 |
| maxElement()/maxElement |
获取集合中值最大的元素 |
| elements() |
获取集合中所有的元素 |
5. 查询方法
|
|
list()方法 |
iterator()方法 |
uniqueResult()方法 |
| 返回值 |
如果查询的是单一表中的对象则返回一个对象;否则返回Object[]对象数组 |
||
| 返回值示例 |
List<[对象]>/List |
Iterator<[对象]>/ Iterator |
Object[] |
6. HQL的查询方式
原生SQL查询(满足特殊要求)和HQL查询(跨平台)。
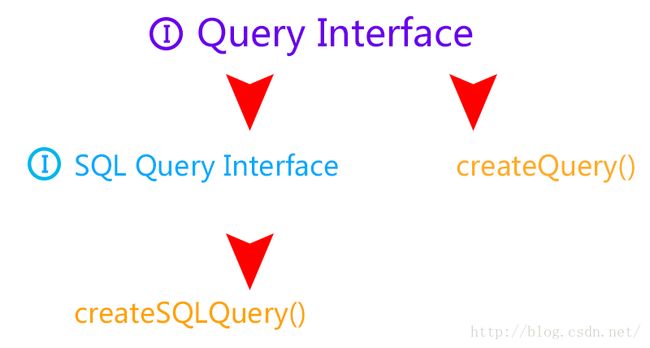
原生SQL查询使用Query接口的createSQLQuery()方法进行查询;HQL查询则使用Query接口的createQuery()方法查询。
适用于HQL查询的SQLQuery()方法还支持addEntity()方法和addJoin()方法,分别用于支持将查询结果映射为类和支持多表连接查询。
7. Hibernate支持的查询方式
Hibernate支持命名查询,需要在查询的实体类的映射文件中配置要执行的SQL/HQL语句,可以将业务代码和SQL/HQL语句分离,达到降低耦合、降低复杂度的作用。
8. Hibernate操作大对象
Hibernate支持Oracle数据库中的CLOB(字符串大对象)和BLOB(二进制数据大对象)大对象数据类型。
字段和类型映射对照表
| Java数据类型 |
Oracle数据类型 |
| byte[] |
BLOB |
| java.lang.String |
CLOB |
| java.sql.Clob |
CLOB |
| java.sql.Blob |
BLOB |
当按照MyEclipse反向工程工具映射好实体类后,发现在Oracle数据库中对应字段的CLOB在Java程序中映射成了String类型,而BLOB也映射成了String类型,此事需要手动更改持久化类中属性的类型和映射文件中的类型。
9. BLOB类型从Java App中读取时不能直接读取,需要先将二进制数据写入到磁盘上的文件中,再读取文件。
九. Criteria查询及注解
1.
Criteria查询数据的步骤:

2. Criteria和HQL的异同点:
|
|
Criteria查询 |
HQL查询 |
| 适用场合 |
单表查询 |
多表连接查询 |
| 获取结果的方法 |
Criteria仅支持list()方法,不支持迭代器 |
HQL用到的Query接口支持list()和iterate() |
|
|
|
|
3. 投影查询
投影查询需要用到Projection接口和Projections(静态)类。
例:
查询时设置单一列:
.setProjection(Property.forName(“[持久化类的某一属性名]”)).list();
查询时设置查询多个列:
.setProjection(Projections.projectionList().add(Property.forName(“[持久化类的某一属性名]”)).add(Property.forName(“持久化类的某一属性名”)));
4. DetachedCriteria查询
作用:为了将各种查询条件在进入业务层之前封装好(即在Web层就已经能够把各种条件整理好并准备发送到业务逻辑层),避免业务层和查询条件过于紧耦合。
特性:
创建时不再需要Session对象了,在使用时调用DetachedCriteria对象的getE xecutableCriteria([Session对象])方法进行查询,也就是在真正要用的时候才需要Session对象传入。
5. 注解
作用:为了替换复杂而又臃肿的hbm.xml文件而推出。
常用注解列表
| 注解标记 |
备注 |
| @Entity |
将一个类声明为持久化类 |
| @Id |
持久化类的标识属性 |
| @GeneratedValue |
标识属性(主键)的生成策略 AUTO:自动; TABLE:使用表保存ID值; INDENITY:使用支持自增的数据库的自增列; SEQUENCE:使用序列创建主键。 |
| @UniqueConstraint |
定义唯一约束 |
| @Transient |
忽略某些属性,无需持久化 |
下面举例说明在学习过程中遇到cascade属性的问题:
Dept类和Emp类是一对多的关系:
packagehibernate.entity;
importjava.util.HashSet;
import java.util.Set;
importjavax.persistence.CascadeType;
importjavax.persistence.Column;
importjavax.persistence.Entity;
importjavax.persistence.FetchType;
importjavax.persistence.Id;
importjavax.persistence.OneToMany;
importjavax.persistence.Table;
/**
* Dept entity. @author MyEclipse PersistenceTools
*/
@Entity
@Table(name= "DEPT", schema = "SCOTT")
publicclass Dept implements java.io.Serializable {
// Fields
private Byte deptno;
private String dname;
private String loc;
private Set emps = newHashSet(0);
// Constructors
/** default constructor */
public Dept() {
}
/** minimal constructor */
public Dept(Byte deptno) {
this.deptno = deptno;
}
/** full constructor */
public Dept(Byte deptno, String dname,String loc, Set emps) {
this.deptno = deptno;
this.dname = dname;
this.loc = loc;
this.emps = emps;
}
// Property accessors
@Id
@Column(name = "DEPTNO",unique = true, nullable = false, precision = 2, scale = 0)
public Byte getDeptno() {
return this.deptno;
}
public void setDeptno(Byte deptno) {
this.deptno = deptno;
}
@Column(name = "DNAME",length = 14)
public String getDname() {
return this.dname;
}
public void setDname(String dname) {
this.dname = dname;
}
@Column(name = "LOC", length= 13)
public String getLoc() {
return this.loc;
}
public void setLoc(String loc) {
this.loc = loc;
}
/**
* 按照正常的思路来说,Dept是“一”的一方,而Emp是“多”的一方,那么主动方就用该是“多”的一方(即Emp)
* 但现在看到的情况却是在Dept(“一”的这一方)加上了cascade属性,按照正常思路来说cascade一般要在
* “多”的一方加,因为只有“多”的一方变动几率大(员工是经常保存的,而部门却不会经常变动)。
*/
/*
* 其实这里可以这样理解:
* 此处的cascade属性是为对方类(Emp持久化类)指定的。虽然是在“一”的一方写着cascade属性,实则是设置
* 了Emp类的cascade属性罢了。
*/
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.LAZY, mappedBy = "dept")
public Set getEmps() {
return this.emps;
}
public void setEmps(Setemps) {
this.emps = emps;
}
} packagehibernate.entity;
importjava.util.Date;
importjavax.persistence.Column;
importjavax.persistence.Entity;
importjavax.persistence.FetchType;
importjavax.persistence.Id;
importjavax.persistence.JoinColumn;
importjavax.persistence.ManyToOne;
importjavax.persistence.Table;
importjavax.persistence.Temporal;
importjavax.persistence.TemporalType;
/**
* Emp entity. @author MyEclipse PersistenceTools
*/
@Entity
@Table(name= "EMP", schema = "SCOTT")
publicclass Emp implements java.io.Serializable {
// Fields
private Short empno;
private Dept dept;
private String ename;
private String job;
private Short mgr;
private Date hiredate;
private Double sal;
private Double comm;
// Constructors
/** default constructor */
public Emp() {
}
/** minimal constructor */
public Emp(Short empno) {
this.empno = empno;
}
/** full constructor */
public Emp(Short empno, Dept dept,String ename, String job, Short mgr,
Date hiredate,Double sal, Double comm) {
this.empno = empno;
this.dept = dept;
this.ename = ename;
this.job = job;
this.mgr = mgr;
this.hiredate = hiredate;
this.sal = sal;
this.comm = comm;
}
// Property accessors
@Id
@Column(name = "EMPNO",unique = true, nullable = false, precision = 4, scale = 0)
public Short getEmpno() {
return this.empno;
}
public void setEmpno(Short empno) {
this.empno = empno;
}
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "DEPTNO")
public Dept getDept() {
return this.dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
@Column(name = "ENAME",length = 10)
public String getEname() {
return this.ename;
}
public void setEname(String ename) {
this.ename = ename;
}
@Column(name = "JOB", length= 9)
public String getJob() {
return this.job;
}
public void setJob(String job) {
this.job = job;
}
@Column(name = "MGR",precision = 4, scale = 0)
public Short getMgr() {
return this.mgr;
}
public void setMgr(Short mgr) {
this.mgr = mgr;
}
@Temporal(TemporalType.DATE)
@Column(name = "HIREDATE",length = 7)
public Date getHiredate() {
return this.hiredate;
}
public void setHiredate(Date hiredate){
this.hiredate = hiredate;
}
@Column(name = "SAL",precision = 7)
public Double getSal() {
return this.sal;
}
public void setSal(Double sal) {
this.sal = sal;
}
@Column(name = "COMM",precision = 7)
public Double getComm() {
return this.comm;
}
public void setComm(Double comm) {
this.comm = comm;
}
}
十. MyBatis入门
1. MyBatis和Hibernate的异同点:
|
|
MyBatis |
Hibernate |
|
| 相同点 |
都属于ORM框架,都为数据层提供持久化操作的支持 |
||
| 不同点 |
学习成本 |
低 |
较高 |
| SQL |
手动编写SQL语句 |
无需关注SQL结果和映射 |
|
| 移植性 |
差 |
好 |
|
| 灵活度 |
较高 |
较低 |
|
| 执行效率 |
高 |
较低 |
|
| 适用场合 |
小型项目; 多表复杂查询; 灵活的DAO层解决方案; 数据库设计或项目结构简单的项目 |
映射关系全透明; 要支持多种数据库; 完全动态的SQL |
|
2. 结果映射
有两种方式实现结果映射:
resultType – 设置结果为某一实体
resultMap – 设置结果为配置文件中的某一resultMap元素中映射的集合
3. 目录结构:
mybatis-config.xml放在src根目录下;
SQL映射文件放在与持久化类(在Mybatis中,持久化类需要手动编写)的同级目录下。
4. Mybatis中使用模糊查询的方式
[列名] like ‘%${变量的值}%’
5. 在MyBatis的SQL映射文件中需要对SQL语句(在MyBatis中视为非法字符)进行转义,转义的前后缀如下:
6. 在MyBatis的SQL映射文件中,在配置文件中设置标签ID要和接口中的方法名一致。