akka基础
-
- 基本概念
- 消息传递API
- 通用API
- 消息传递方式
- Future机制
- Actor生命周期
- 处理状态和错误
- 监督
- kill actor
- 生命周期监控和DeathWatch
- 安全重启
- 状态
- 纵向扩展
- Router
- 调度方式
- 使用策略
- 横向扩展
- 订阅集群事件
- 启动、退出、状态
- 种子节点
- 客户端、服务器、worker
- actor寻址
- 邮箱
- 熔断
- 配置
ps:本文主要参考《akka入门与实践》
学习akka之前最好先了解一下reactive架构,actor模型和erlang语言的设计思想
《大数据时代的软件架构范式:Reactive架构及Akka实践》
《面向软件错误构建可靠的分布式系统》
补充erlang论文读后笔记
基本概念
- akka:基于actor并发模型的分布式工具集,用于协调远程计算资源来进行一些工作。
- actor:类似于进程或者线程的工作节点,通过消息传递与外界通信;
- 消息:跨进程(多个actor)之间通信的数据,通过传递消息触发各种行为
- 邮箱:在actor处理消息前具体存储消息的地方,可以看做是一个消息队列,一般情况下,每个actor都有自己的邮箱。
消息传递API
通用API
- Receive:在构造函数中调用receive,描述actor在接收到不同消息时改如何做出响应。receive方法接收ReceiveBuilder作为参数。
- match:ReceiveBuilder的match方法使用模式匹配来定义不同的响应,类似于case语句。
- sender:返回一个ActorRef
- Actor创建:actorOf\props\actorSelection
- 在akka中,不会直接访问actor的实例,也不调用actor的方法,不直接改变actor的状态,只向actor发送消息,使用消息传递的方式来代替直接方法调用,指向actor实例的引用actorRef。
- actorsystem.actorOf(Props.create(xxx.class,arg1,arg2)); actorOf()生成一个新的actor,并且返回指向其的引用
- Props():为了保证将actor的实例封装起来,将actor的构造函数传递给一个Props的实例,传入一个Actor的类型和一个边长的参数列表。
-actorSelection():根据路径查找actor
消息传递方式
- ask:向actor发送一条消息,返回一个Future,当actor返回响应时,会完成Future,不会向消息发送者的邮箱返回任何消息。
- tell:单向消息传递模式,第一个参数时消息,第二个是希望对方actor看到的发送者.sender().tell()会返回给发送消息的actor。
- forward:将接收到的消息灾发送给另一个actor。sender().tell()会返回给原始消息的发送者。
- pipe:用于将Future的结果返回给sender()或者别的actor,对于使用ask或者处理Future的场景,使用pipe可以正确放回Future的结果;因为Future的回调会在另外一个线程中执行,所以未必能够通过sender()访问到正确的值,会有出乎意料的结果
使用ask的问题
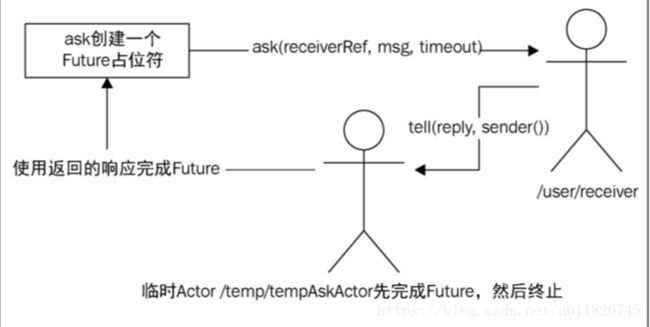
1.临时actor完成Futrue,在另一个执行上下文中执行回调函数;
2.必须设置超时函数
3.超时错误的栈追踪信息并没有用,任何一部超时都会引起错误
4.额外的性能开销,创建临时actor
优先使用tell: - fire-and-forget消息模式,不会阻塞等待消息
- 超时调度:Scheduler调度,希望在一段特定的时间后发生某一件事,如果没有发生,就以某种方式表示失败
context().system().scheduler().scheduleOnce(Duration.create(3,TimeUnit.SECONDS),actor,”timeout”);//3s之后向actor发送一条timeout消息 - 显示创建一个匿名extraActor,定义对消息的响应,这个临时actor的声明周期很短,不会超过3秒
Future机制
Akka中返回的Future是scala.concurrent.Future;在java8中可以将其转换为CompletableFuture。
CompletableFuture
- .thenAccept():对返回结果执行代码
- .thenApply():对返回结果进行转换
- .thenCompose():对返回结果进行异步转换,结果扁平化,得到结果后再进行另外一个异步调用,使得结果只在一个Future中;
- .handle():失败情况下执行代码
- .exceptionally():在失败中恢复,失败之后转换,返回一个成功的结果
Actor生命周期
- prestart:构造函数之后调用;
- postStop:重启之前调用;
- preRestart:重启之前调用,默认情况下会调用postStop
- postRestart:重启之后调用,默认会先调用preStart
处理状态和错误
监督
层次结构:
- 顶层/根actor,然后是路径为/user的守护actor,使用actorSystem.actorOf创建的都是守护actor的子actor;
- 如果在一个actor内部创建另外一个actor,可以通过调用context().actorOf()使得新建的actor成为原actor的子actor.
- /system路径:所有的监督事件都发生在这个路径下面的actor中
实现:
在actor中,重写supervisorStrategy,返回一个新的策略OneForOneStrategy;
java8中用DeciderBuilder.match来实现模式匹配,匹配抛出的异常,并指定后续操作;
kill actor
- 调用ActorSystem.stop(actorRef)方法;
- 调用ActorContext.stop(actorRef)
- 给actor发送一个PoisonPill消息,会在actor完成消息处理后将其停止
- 给actor发送一条kill消息,会导致actor抛出ActorKilledException异常;—思路:可以写一些后门
生命周期监控和DeathWatch
- 父actor对子actor的生命周期可以进行监督;
- actor通过context.watch(actorRef)、context.unwatch(actorRef)注册或者取消对其他actor的监控;
- 如果被监控的actor停止了,负责监控的actor就会接收到一条Terminated(actorRef)消息。——那个死循环的问题是不是可以监控生命周期来减少计数器
安全重启
重启过程:
调用preRestart()->原来的actor停止(这个时候原来的状态就消失了)->重新建一个actor实例,运行新建的actor的构造函数->调用postRestart(),重启完成;
为了防止重启过程中丢失信息,最好的方式是通过Props把初始化信息传递给actor的构造函数;
很多时候,我们不希望actor在初始化的过程中发生错误,而是会给actor发送一条初始化信息,然后再actor运行的过程中处理状态的变化,可以在preStart()中向actor自己发送一条connect消息来达到这个效果:
public void preStart(){self.tell(new Connect(),null)}
状态
- stash:将消息暂存到一个独立的队列中,该队列存储目前无法处理的消息:
- unstash:把消息从暂存队列中取出,放回到邮箱队列中,actor就能继续处理这些消息
- stash消息的状态一定要和某个时间限制绑定,否则会填满邮箱;—stash泄露
在actor的构造函数或preStart方法中调度执行这个消息:
System.scheduler().scheduleOnce(
Duration.create(1000,TimeUnit.MILLISECONDS),self(),CheckConnected,system.dispacher(),null);Actor根据不同的状态来改变行为的机制:
1.条件语句
2.热交换
context.become(PartialFunction behavior)改变成beahavior这个函数要做的事、unbecome()将actor的行为改回默认行为
3.FSM
- 比热交换要重
- 定义状态、定义状态容器(队列),定义行为
- akka.actor.AbstractFSM(S,D)
- When\matchEvent\event指定方法
纵向扩展
Router
Router:akka中用于负载均衡和路由的抽象;
创建:传入一个actor group或者由router来创建一个actor pool
- group:传入一个包含actor的路径的列表,ActorRef router = system.actorOf(new - RoundRobinGroup(actors.map(actor->actor.path()).props());
- Pool:实例化一个actor,然后调用withRouter,并传入一个路由策略,以及希望pool中包含的actor数量 ActorRef workerRouter = system.actorOf(Props.create(xxx.class).withRouter(new RoundRobinPool(8)))
路由策略:P121
广播消息:向一个router group/pool中所有actor发送消息:Router.tell(new akka.routing.Broadcast(msg));
监督router group/pool中的对象:
1.pool方式:router自己创建的actor,这些路由对象时router的子节点,可以在创建router的时候,调用withSupervisorStrategy方法来指定监督策略 so,推荐pool的方式
调度方式
- Dispatcher :将如何执行任务和合适运行任务解耦,一般来说,Dispatcher会包含一些线程,这些线程会负责调度并运行任务,比如处理Actor的消息以及线程中的Future事件。Dispatcher是akka能够支持响应式变成的关键,是负责完成任务的机制。
- Executor:dispatcher基于Executor,常见的两种Executor,ThreadPool Executor 线程池执行器,工作队列,允许线程重用,减少创建销毁的次数;ForkJoinPool Executor,分治算法,递归地将任务分割成更小的子任务,然后把子任务分配给不同的的线程运行,接着再把结果组合起来,“工作窃取算法”,允许空闲的线程窃取分配给另外一个线程的工作。
- 关系:Dispacher实现了scala.concurrent.ExcutionContextExecutor接口,这个接口扩展了java.util.concurrent.Executor,可以把Executor传递给java的Future,
获取Dispatcher:
- System.dispatcher
- System.dispatchers.lookup(“…”)//获取配置文件中的dispatcher
四种Dispatcher:
- Dispatcher:默认的
- PinnedDispatcher:给每个actor都分配自己独有的线程,确保每个actor都能够立即响应;
- CallingThreadDispatcher:没有Executor,而是在发起调用的线程上执行工作,主要用于测试;
- BalancingDispatcher:pool中的所有actor都共享一个邮箱,并且会为pool中的每个actor都创建一个线程;
为actor配置dispatcher
- system.actorOf(Props.create(xxx.class).withDispatcher(“…”);
使用策略
可以把需要大量计算、运行时间较长的任务分离到单独的Dispatcher,确保在糟糕的情况下仍然能够有资源去运行其他任务;
横向扩展
订阅集群事件
创建ClusterController Actor,在actor的preStart和postStart方法订阅集群事件。
例子
- 要记得在postStop方法中调用unsubscribe,防止泄露;
- MemberEvent:该事件会在集群状态发生变化时发出通知;
- UnreachableMerble:该事件会在某个节点被标记为不可用时发出通知;
—订阅集群事件,对不可用节点下线
启动、退出、状态
启动节点
public class Main{
public static void mian(String[] args){
ActorSystem system = ActorSystem.create(".conf中system名字");
ActorRef clusterController = system.actorOf(
Props.create(ClusterController.class),"clusterController");
}
}退出集群
试图使用kill进程来关闭及诶点的话,akka会把这个节点标记为不可达,然后输出一段错误信息。
优雅地退出集群:cluster.leave(self().path().address());–可以写一个api,对特殊情况下线机器节点
集群成员的状态
底层有一个逻辑上leader节点,负责协调状态的变化。所有节点的状态改变通过MermberEvent在集群间发送。

失败检查
- 节点不可达时会被标记为MemberUnreachable,如果在合理的时间内该节点又重新可达,那么节点会重新运行,如果在配置时间内始终不可达,那么leader节点就会将该节点标记为down,将无法重新加入集群;
- 如果一个节点无法访问并且被标记为Down,那么该节点在这之后将服务重新加入集群,会产生两个分离的集群,目前akka没有解决这个问题。
- 所以一旦某个节点被标记为Down,就必须关闭该节点,重新启动,获得一个新的id,才能重新加入集群。
种子节点
在配置文件中,指定akka.cluster.seed-nodes指定种子节点,当一个节点加入集群时,该节点会尝试连接第一个种子节点,如果连接成功,新节点就会发布其地址。种子节点会负责通过gossip协议将新节点的地址最终通知整个集群,如果连接第一个种子节点失败,新节点就会尝试连接第二个种子节点。只要成功连接任何一个种子节点,那么任何节点加入或离开集群时,我们都不需要对配置进行修改。
当部署到生产环境时,应该至少定影两个拥有固定ip地址的种子节点,并且保证任何时候都至少有一个种子节点可用。如果节点尝试加入集群时,所有已种子节点都不可用,那么就无法加入集群。
客户端、服务器、worker
- 客户端用于与无状态集群服务进行通信,将消息路由至集群中的任意成员,客户端本身不是集群成员,但是必须知道集群的拓扑结构。
- 使用contrib库中的akka cluster client
- 客户端必须知道要将消息发送到那些actor或者router,以及由哪些actor或router来响应集群事件。
- 配置文件中为客户端添加akka扩展
akka.extensions = ["akka.contrib.pattern.ClusterReceptionistExtension"]- 这样就会在服务器上启动ClusterReceptionist,负责处理客户端和集群之间的通信细节;
- 在服务器上创新ClusterReceptionistActor的路径是/user/receptionist
- 在main方法的ClusterReceptionist中注册worker actor
- 在配置文件中设置cluster client的邮箱
actor寻址
actor的路径包含两部分:源:akka://ActorSystem;路径:/user/actor;
如果我们向ActorSelection发送消息而其对应的Actor不存在,消息就会丢失.
判断actor存在
使用akka.actor.Identify
Identify msg = new Indentify(messageId);
Future identify = (Future)Patterns.ask(actor,msg,timeout); 如果actor存在,会接收到ActorIdentify(messagedId,Some(actorRef))作为相应,如不存在的话,会收到ActorIdentify((path,client),None);
邮箱
邮箱基于队列,Props中有一个withMailbox的方法,可以在创建actor的时候调用该方法,为actor分配邮箱:
ActorRef clusterController = system.actorOf(Props.create(MyActor.class).withMailbox("default-mailbox"));阻塞邮箱:邮箱已满时,再向邮箱发送消息会导致线程等待直至邮箱腾出空间;
非阻塞邮箱:邮箱满时,之后的消息会被丢弃;mailbox-type = “akka.dispatch.NonBlockingBoundedMailbox”
提高邮箱中消息的优先级
- 优先级邮箱:接收到消息之后,对消息进行排序,给每个消息赋予一个优先级;内次接收到消息都要重新排序,会有额外的性能开销;
- 控制感知邮箱:ControlMessageAware,允许任意扩展了akka.dispatch.Controlmessage的消息插入到队列头部
熔断
- 熔断机制会监控应用程序某些部分的相应延迟或错误;消息会照常发送给熔断器,熔断器负责监控消息的响应时间,此时状态为关闭;
- 一旦达到了某个特定的延迟上限,熔断器就会把状态改成打开,此时会理解拒绝所有收到的请求;
- 接着,在一段时间后,熔断器会把状态改成半开,并尝试发送一条消息,如果很快得到响应,可认为服务已经恢复,改为关闭circuitBreaker:onOpen onClose onHalfOpen
例子:
CircuitBreaker
其他话题:
反向压力 Reactive strams
配置
补充akka配置说明
akka {
prio-dispatcher {
mailbox-type = "PriorityMailbox"
}
actor {
provider = "cluster"
deployment {
/xxx/yyy{
router = balancing-pool
nr-of-instances = 5
pool-dispatcher {
executor = "fork-join-executor"
# allocate exactly N threads for this pool
fork-join-executor {
# Min number of threads to cap factor-based parallelism number to
parallelism-min = 8
# The parallelism factor is used to determine thread pool size using the
# following formula: ceil(available processors * factor). Resulting size
# is then bounded by the parallelism-min and parallelism-max values.
parallelism-factor = 3.0
# Max number of threads to cap factor-based parallelism number to
parallelism-max = 64
# Setting to "FIFO" to use queue like peeking mode which "poll" or "LIFO" to use stack
# like peeking mode which "pop".
task-peeking-mode = "FIFO"
# Throughput defines the maximum number of messages to be
# processed per actor before the thread jumps to the next actor.
# Set to 1 for as fair as possible.
throughput = 1
}
}
cluster {
enabled = on
allow-local-routees = on
use-roles = ["server"]
}
}
}
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 2551
}
}
cluster {
seed-nodes = [
"akka.tcp://xxx@ip:port",
"akka.tcp://xxx@ip:port"
]
roles = ["client", "server"]
auto-down-unreachable-after = 60s
seed-node-timeout = 60s
}
# sigar native library extract location during tests
# akka.cluster.metrics.native-library-extract-folder=${user.dir}/target/native
}
//akka.cluster.shutdown-after-unsuccessful-join-seed-nodes = 20s
//akka.coordinated-shutdown.terminate-actor-system = on
akka.cluster.jmx.multi-mbeans-in-same-jvm = on高级:
日志:slf4j
信道eventBus:发布、订阅、分类器
Agent:java的AtomicInteger,绑定diapacher:get set方法
akka persistance:actor事件回放、状态保存