SSD:Single Shot MultiBox Detector(三)
这都是个人学习SSD所做记录,仅作为个人备忘录
SSD:Single Shot MultiBox Detector(一): http://blog.csdn.net/u011956147/article/details/73028773
SSD:Single Shot MultiBox Detector(二): http://blog.csdn.net/u011956147/article/details/73030116
SSD:Single Shot MultiBox Detector(三): http://blog.csdn.net/u011956147/article/details/73032867
SSD:Single Shot MultiBox Detector(四): http://blog.csdn.net/u011956147/article/details/73033170
SSD:Single Shot MultiBox Detector(五): http://blog.csdn.net/u011956147/article/details/73033282
这篇博客主要写prior_box_layer
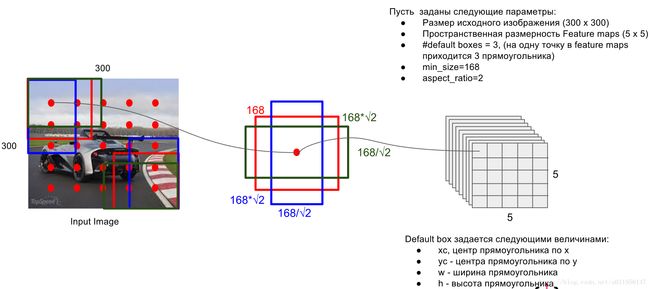
这一层完成的是给定一系列feature map后如何在上面生成prior box。SSD的做法很有意思,对于输入大小是W×H的feature map,生成的prior box中心就是W×H个,均匀分布在整张图上,像下图中演示的一样。在每个中心上,可以生成多个不同长宽比的prior box,如[1/3, 1/2, 1, 2, 3]。所以在一个feature map上可以生成的prior box总数是W×H×length_of_aspect_ratio,对于比较大的feature map,如VGG的conv4_3,生成的prior box可以达到数千个。当然对于边界上的box,还要做一些处理保证其不超出图片范围,这都是细节了。
这里需要注意的是,虽然prior box的位置是在W×H的格子上,但prior box的大小并不是跟格子一样大,而是人工指定的,原论文中随着feature map从底层到高层,prior box的大小在0.2到0.9之间均匀变化。
一开始看SSD的时候很困扰我的一点就是形状的匹配问题:SSD用卷积层做bbox的拟合,输出的不应该是feature map吗,怎么能正好输出4个坐标呢?这里的做法有点暴力,比如需要输出W×H×length_of_aspect_ratio×4个坐标,就直接用length_of_aspect_ratio×4个channel的卷积层做拟合,这样就得到length_of_aspect_ratio×4个大小为W×H的feature map,然后把feature map拉成一个长度为W×H×length_of_aspect_ratio×4的向量,用SmoothL1之类的loss去拟合,效果还意外地不错……
(上述参考链接:参考链接)
其实这里的做法和Faster RCNN的做法类似,有兴趣的参考我之前的博文 Faster RCNN代码理解(Python)
图示如下:


代码如下:
#include ::LayerSetUp(const vector::Reshape(const vector::Forward_cpu(const vector(std::max(top_data[d], 0.), 1.);
}
}
// set the variance.
// 解答: https://github.com/weiliu89/caffe/issues/75
// 除以variance是对预测box和真实box的误差进行放大,从而增加loss,增大梯度,加快收敛。
// 另外,top_data += top[0]->offset(0, 1);已经使指针指向新的地址,所以variance不会覆盖前面的结果。
// offse一般都是4个参数的offset(n,c,w,h),设置相应的参数就可以指到下一张图(以四位张量为例)
top_data += top[0]->offset(0, 1); // 这里我猜是指向了下一个chanel
if (variance_.size() == 1) {
caffe_set(dim, Dtype(variance_[0]), top_data);// 用常数variance_[0]对top_data进行初始化
} else {
int count = 0;
for (int h = 0; h < layer_height; ++h) {
for (int w = 0; w < layer_width; ++w) {
for (int i = 0; i < num_priors_; ++i) {
for (int j = 0; j < 4; ++j) {
top_data[count] = variance_[j];
++count;
}
}
}
}
}
}
INSTANTIATE_CLASS(PriorBoxLayer);
REGISTER_LAYER_CLASS(PriorBox);
} // namespace caffe
本文链接:http://blog.csdn.net/u011956147/article/details/73032867