语义分割--Dilated Residual Networks
DRN:Dilated Residual Networks
收录:CVPR2017(IEEE Conference on Computer Vision and Pattern Recognition)
原文地址:Dilated Residual Networks
本文配合前面的论文-Understand convolution for Semantic Segmentation有奇效~
代码:
- 官方-Pytorch
Abstract
扩张卷积可以增加神经元的接收野,若用于替换卷积网络中的下采样层,即维持了feature map的空间分辨率,又可以保持后续神经元接收野的分辨率。论文据此提出了dilated residual networks(DRN),实验表明DRN在图像分类等任务上优于不加扩张卷积的网络。此外,使用空洞卷积会产生"gridding"问题,论文提出了一些解决方案。
Introduction
卷积神经网络使用池化和下采样获取更抽象的特征,但这伴随着是feature map空间分辨率的下降,这会丢失很多敏感细节,不利于涉及密集预测的图像场景解析任务。论文认为池化和下采样不是必须的(PS:很多大师都觉得池化这个操作很蠢,但是离不开~),在残差网络的结构上,使用扩张卷积替换模型内部的下采样层来提高输出的准确率。
在ImageNet上DRN的输出分辨率为 28 × 28 28×28 28×28(原Resnet输出 7 × 7 7×7 7×7,空间分辨率提高了4倍,替换了2个下采样),论文指出在此基础上使用平均池化效果不错。使用扩张卷积会带来"gridding"问题,论文提出了一种用于消除影响的解决方案,这进一步提高了DRN的准确率。同时验证了DRN在其他任务:例如语义分割任务上表现也很不错。
Approach
Dilated Residual NetWorks
在卷积神经网络中使用下采样会降低feature的空间分辨率,这会丢失许多细节,从而影响模型对小型目标乃至目标之间关系的识别。
论文以Resnet为基础,提出了一个改进方法,在resnet的top layers移除下采样层,这可以保持feature map的空间分辨率,但后续的卷积层接收野分辨率下降了,这不利于模型聚合上下文信息。针对这一问题,论文使用扩张卷积替换下采样,在后续层合理使用扩张卷积,在保持feature map的空间分辨率同时维持后续层接收野的分辨率。
具体来说,对于Resnet可分为5组卷积,DRN改进了后两组卷积(记为 G 4 G^4 G4和 G 5 G^5 G5),这两组卷积开始的卷积层都是下采样,DRN做了以下改进:
- 去除了开始的下采样,这保持了feature的分辨率,注意到无论是 G 4 G^4 G4和 G 5 G^5 G5的第一层卷积接收野是不受影响的,但是 G 4 G^4 G4的后续层接收野下降了2倍, G 5 G^5 G5的后续层接收野下降了4倍
- 对 G 4 G^4 G4的后续层使用2倍扩张率的扩张卷积, G 5 G^5 G5的后续层使用4倍扩张率的扩张卷积
- 后续就是接平均池化,预测输出了
DRN和Resnet的对比如下:
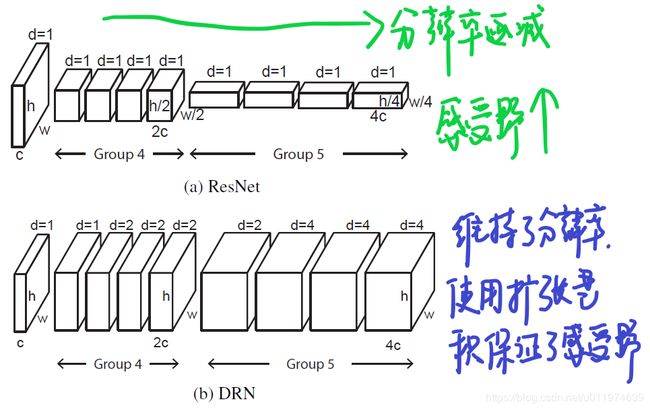
注意到原Resnet在 G 4 G^4 G4和 G 5 G^5 G5上都有下采样,由输入的 224 × 224 224×224 224×224最终输出 7 × 7 7×7 7×7,下采样因子为32。使用DRN替换了两个下采样,最终输出为 28 × 28 28×28 28×28,下采样因子为8。相比增加了16倍的值,空间信息量增大许多。
至于为什么不全替换了下采样层,是因为在全分辨率下不使用下采样,内存消耗超出当前硬件的能力。
Degridding
扩张卷积产生的"gridding"问题,在Understand Convolution for Semantic Segmentation 中详细解释过。
大致可以总结当使用的扩张率增加,采样点之间相隔较远,局部信息丢失,产生的预测图出现网格效应。例如下图©所示:

可以看到图©预测图有棋盘状。
论文针对这一问题提出了一些解决办法。示意图如下:

(a): 移除最大池化层
如图5 (a) DRN-A-18所示。 继承了原始Resnet在初始的 7 × 7 7×7 7×7卷积后接的最大池化操作,论文发现该池化层有高频高幅的激活,如图6 (b)所示,这样的高频传播到网络后面,会加剧gridding影响。

故图5 (b)使用卷积滤波器代替最大池化,图6 ©显示了转换后的效果。
(b): 添加图层
如图5 (b) DRN-B-26所示。考虑到扩张卷积产生的"gridding"影响,论文在网络的后端增加两个扩张卷积block,即level7-8,注意到这两个block的扩张率较小。作用类似于使用不同频率的去抗混叠(个人理解~)
©: 移除残差连接
在图5 (b) DRN-B-26中,在网络的后端增加了两个扩张率的卷积block,作用类似于抗混叠,但是因为增加的模块存在残差连接(残值就能直通,移除了就没办法不通过卷积了),为了完全了实现扛混叠,论文移除了残差连接,图5 © DRN-C-26所示。这样的结构虽然在深度和容量上超出了开始的DRN-A,但后续的实验证明这样结构对精度有显著的提升,与更深的DRN-A-34有类似的精度,比DRN-A-50在语义分割任务上有更好的精度。
DRN-C的特征激活图如图7所示:

Experiment
Image Classification
| 项目 | 配置 |
|---|---|
| 训练数据 | ImageNet2012 |
| 优化器是SGD | momentum 0.9 and weight decay 1 0 − 4 10^{-4} 10−4 |
| 学习率 | 初始是 1 0 − 1 10^{-1} 10−1,每30epochs下降10倍,一共跑了120epochs. |
| 测试集 | ImageNet验证集 |
论文针对数据裁剪方式设计了两种评估手段:1-crop和10-crop:
1-crop:使用图片中间的 224 × 224 224×224 224×224区域10-crop:使用图片中间、四个角和翻转后的,共10中crop,预测结果取平均
多个实验的对比结果如下:

-
ResNet vs. DRN-A:
DRN-A相比于对应的ResNet有性能上都有提升。DRN-A-50相比于更深的ResNet-101在精度上只有微弱的差距。 -
DRN-A vs. DRN-C: 可以看到每个的DRN-C与对应的DRN-A有显著的提升,虽然在模型的宽度和容量上有所增加,但精度的提升很大,以至于变换后的DRN与更深层模型都有相似的精度。
Object Localization
在ImageNet2012验证集上,评估模型的弱监督目标定位能力,如果预测结果和Ground Truth的IoU超过0.5,则认为预测准确,实验结果如下:

每组DRN比对应的ResNet效果要好,这进一步验证了DRN结构的有效性。同时DRN-C-26性能要明显优于DRN-A,这验证了对"gridding"提出的解决方案的有效性。
Semantic Segmentation
语义分割任务涉及到对像素的密集预测,这对输出feature的分辨率要求较高。而DRN相比于Resnet在分辨率上保持较好,对于上卷积或者后续的增加分辨率的操作需求较少,易于迁移到语义分割应用上。
在CityScapes dataset上,数据增强只使用了随机翻转和裁剪,实验结果如下:

所有的展示结果都超过了ResNet101的66.6%mIoU。同样DRN-C-26和DRN-C-42都比DRN-A-50要好,这验证了弥补"gridding"影响的方案在密集预测任务上特别有效。
DRN-A-50和DRN-C-26的可视化对比如下:
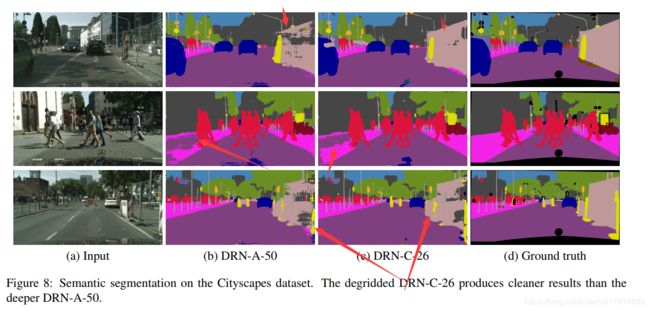
DRN-A-50受"gridding"的影响较多,相比之下DRN-C-26不仅准确率更好,也更清晰。
Conclusion
论文提出了一种设计卷积网络架构方案,使用扩张卷积替换模型中的下采样,保持feature map的空间分辨率同时不降低后续卷积层的接收野的分辨率,实验证明这样简单转换是有效的。
因为扩张卷积产生的"gridding"影响,论文提出了一些修改模型结构方案减少"gridding"效应,这进一步提高了模型的精度。DRN更适配密集预测任务,可用作复杂的自然图像分析任务起点。