语义分割--(DFN)Learning a Discriminative Feature Network for Semantic Segmentation
Learning a Discriminative Feature Network for Semantic Segmentation
Learning a Discriminative Feature Network for Semantic Segmentation
收录:CVPR2018(IEEE Conference on Computer Vision and Pattern Recognition)
原文地址:DFN
代码:
- 非官方:TensorFlow
Introduction
许多现存的语义分割方法虽然获得了先进的表现。但是这些方法存在没有使用discriminative features的情况。故依旧存在两个方向的挑战:
- intra-class inconsistency:类内不一致。这表示一个区域内,有着相同的语义标签,但是预测结果有所不同。(如Fig.1第一行)
- inter-class indistinction:类别之间模型不清晰。这表示两个相邻的区域,有着类似的外表,但是语义标签不同。(如Fig.1第二行)

论文从更宏观的角度来看语义分割。论文认为语义分割是将相同的语义标签分配给一类事物,而不是分配对单个像素分配单个标签。认为一类事物的像素是一个整体,这自然就会有论文开始提及的两个挑战。
针对这两个挑战,论文最终提出了Discriminative Feature Network(DFN)来解决。
DFN
DPN涉及到了两个组件:Smooth Network(SN)和Border Network(BN).
Smooth Network(SN).
SN用于学习更鲁棒性的特征表示,从而用于解决intra-class inconsistency。
这主要涉及两个因素:
1) 需要多尺度和全局特征用于学习局部和全局的信息。
2) 因为多尺度特征的引入,对于同一事物,因为尺度的原因可能会产生错误的预测。故需要学习更具区分力的有效的特征。
受到这两个方向的启发。Smooth Network基于U-shape结构,该结构用于捕获多尺度信息,并带有全局平均池化用于捕获全局信息。并且提出了Channel Attention Block(CAB),使用high-level的特征逐步指导选择low-level的特征。
Border Network(BN)
该sub-network用于解决inter-class indistinction。即用于去区分具有相似外表但不同语义标签的相邻区域。大多数模型语义分割作为密集的识别任务,这通常会忽略物体类别间的明显关系。因此,明确的语义边界去指导特征学习是很有必要的,这可以方法特征两边的变化趋势。
Border Network通过在训练期间集成 semantic boundary loss去学习区分力的特征。说白了,就是用传统的图像方法从ground truth上提取边缘信息,用这些边缘信息做一个旁监督,从而达到细化边界结果的效果。
DFN的整体架构和贡献
整体架构如下:
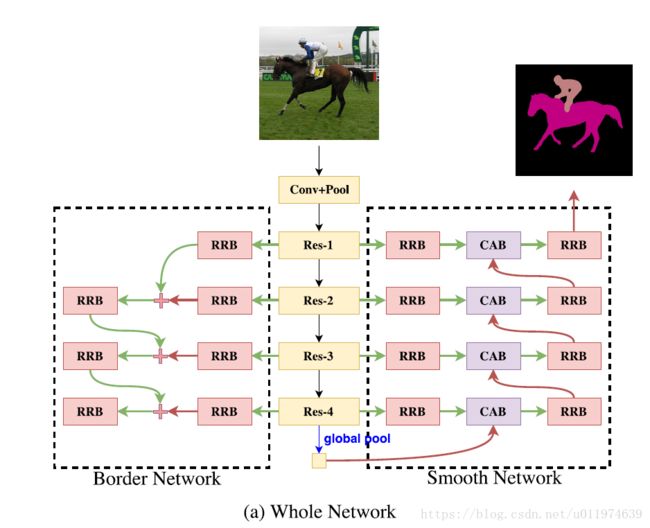
该结构和GCN,PAN都很相似。
论文的主要贡献在于:
- 论文从宏观的角度再思考语义分割任务,认为语义分割是将同样的语义标签分配到同一物体区域。
- 论文提出了DFN用于同时解决 intra-class inconsistency和inter-class indistinction问题。实验结果证明了新模型的有效性。
- 论文提出了具有全局信息和通道注意力模型的Smooth Network用于提升类内一致性。
- 论文设计的具有深度监督的bottom-up结构的Border Network用于扩张语义边界两边的特征变化。这可以细化预测的边界。
Architecture
由前面叙述可知,论文针对intra-class inconsistency和inter-class indistinction这两个挑战,提出了Discriminative Feature Network(DFN)来应对,其中DFN包含两个子网络Smooth network和Smooth network和Border network。。
先介绍Smooth network和Border network,然后全盘托出整个DFN的architecture.
Smooth Network
intra-class inconsistency主要是因为缺乏上下文,因此,论文使用全局平均池化来引入全局上下文信息。然而,全局上下文信息只是具备高级的语义信息,这对于恢复空间信息没有多大帮助。因此,我们需要多尺度的感受野帮助恢复空间信息,而许多方法在这里存在另一个问题,不同尺度的感受野产生的特征会有一些不同尺度的区分力,这会造成错误的结果。
为了解决这个问题,我们需要选择更具区分力的特征来产生一致的语义标签。论文引入了注意力机制来解决。
论文的backbone是Resnet,Resnet依据输出特征的大小分成了5个阶段。论文观察到:不同阶段有着不同的特征观察能力,这导致了不同的表征(manifestation):
- 在低阶段:网络编码更多的空间信息。由于网络的感受野较小并且没有空间上的上下文指导,导致语义特征不佳。
- 在高阶段:因为有着大的感受野,故语义特征不错。但是空间预测就比较模糊了。
总的来讲,就是底阶段偏向空间信息,高阶段偏向语义信息。那么Smooth Network意在使用高阶段的信息来指导底阶段,从而产生更优的预测。
而现存的语义分割架构主要有两个风格:
backbone-style:代表的有PSPNet和DeepLabv3,这样的结构通过PSP module和ASPP 来集成多尺度信息。Encoder-Decoder style: 代表有RefineNet和GCN,这种结构利用不同阶段固定的多尺度上下文,但是这缺乏上下文信息。
此外,许多网络结构结合不同阶段的特征是仅仅是通过通道加完成的,这样的操作忽略了不同阶段之间的差异性。为了解决这个问题,Smooth Network 先是在U-shape结构上嵌入全局池化操作,以产生了V-shape结构(多了个全局池化)。同时,提出了通道注意力模块(Channel Attention Block),这用于结合相邻阶段的特征。高级特征提供语义来指导选择低级特征,从而达到选择更具区分力的特征。
Channel attention block
通道注意力模块结构如图所示:
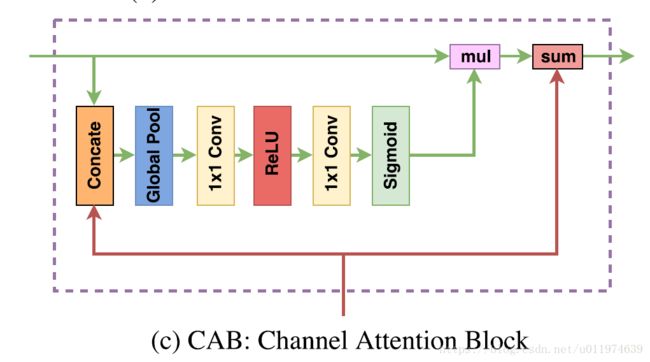
其工作原理如下:

在FCN架构上,卷积操作输出的是score map,这给出每个像素的每个类别的概率值,最终的分数是在最后的特征图上相加得到的,公式如下:
其中 x x 就是网络输出的特征图, w w 表示卷积操作。 k∈{1,2,..K} k ∈ { 1 , 2 , . . K } , K K 表示通道数。D表示所有像素位置的集合。
其中 σ σ 表示预测的概率值, y y 表示网络的输出。
由上述两个公式可以看出,最终的预测标签是有着最高概率值的。我们假设对某一区域的预测标签为 y0 y 0 ,而真正的标签为 y1 y 1 。论文引入了参数 α α 用于改变最高的概率值从 y0 y 0 到 y1 y 1 ,如下面公式所示:
其中 y¯ y ¯ 表示新的预测值,而 α=Sigmod(x;w) α = S i g m o d ( x ; w ) 。
基于上述的公式描述,第一个公式隐式的表示每个通道的权重是一样的。而前面有讲到过,不同阶段的特征具有不同特性,这导致了预测的不一致性,为了获得更加的预测,我们需要选择具有区分力的特征。而通过第三个公式可以通过通道注意力模块对通道加权,用于选择特征。
Refinement residual block
网络的每个阶段的特征都会经过Refinement residual block,如下图所示:
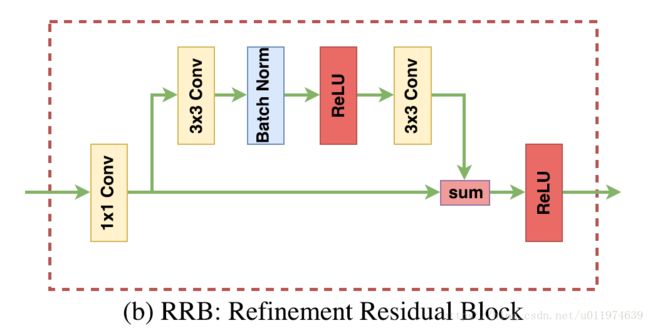
开始是一个恒定的512通道 1×1 1 × 1 卷积,这可以结合所有通道的信息,达到细化特征图的效果。
Experiment
论文以ResNet101为backbone,使用FCN4为主框架。SGD优化器,batch=32,采用”poly”学习率策略。
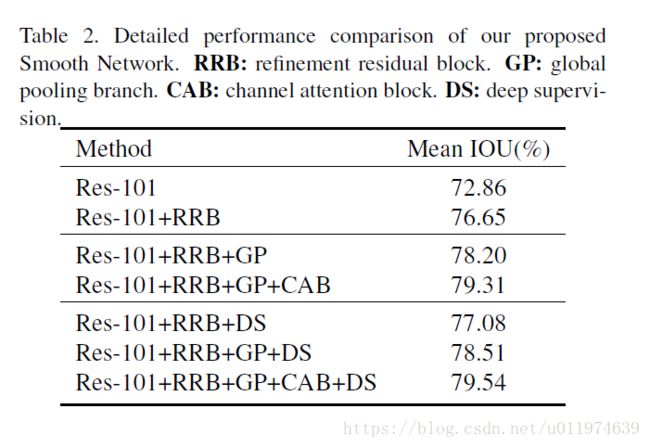
可以看到RRB和CAB,GP的性能提升都是很明显的。
部分可视化结果:

Border Network
在语义分割任务上,尤其是在相邻的区域上有相似外表的物体,预测常会产生混淆。因此,我们需要增强特征之间的区别。受到这样的启发,为了更为精准的提取语义边界,论文采用语义边界监督,让网络学习具有类间区分能力的特征。
论文设计了Bottom-up结构的Boader Network,该网络能够同时从low stage上获得精准的边缘信息,也可以从high stage上获得语义信息,这弥补了一些原始边界缺乏的语义信息。这样,是的high stage的语义信息可以refine low stage的边缘信息。这样的监督信息是来源于在语义分割ground truth上使用传统的图像处理方法,例如Canny边缘等.
为了处理正负样本不均衡,论文使用了focal loss来监督Border network,调整 α α 和 γ γ 参数获得更佳的性能:
其中 pk p k 是对每个类别 k k 的概率估测值。
Experiment
在PASCAL上的实验:

增加BN的性能提升较小~
部分边界可视化结果:


(PS:看Experiment部分,这个Boader Network的提升性能很小,感觉不是那么好使)
Network Architecture
基于Smooth Network和Border Network,论文提出了DFN:
使用了预训练的ResNet作为网络主干。
- 在Smooth NetWork:顶端使用了一个全局池化层捕获全局信息。使用channel attention block来改变权重。 除了最终的全局池化,其他所有stage都使用softmax loss来做深度监督学习。
- 在Border Network上,使用语义边界监督,网络获得更为精准的边界,得到的mask也更具区分度。使用focal loss来监督学习。
使用参数 λ λ 来平衡分割loss的 ls l s 和边界loss的 lb l b .
Experiment
经过试验,论文最终使用的 λ=0.1 λ = 0.1 ,为了提升性能,使用多尺度输入,共5个尺度 0.5,0.75,1,1.5,1.75 0.5 , 0.75 , 1 , 1.5 , 1.75 .
随机的放缩:

有着较大的性能提升。
不一样的 λ λ 带来的性能影响:
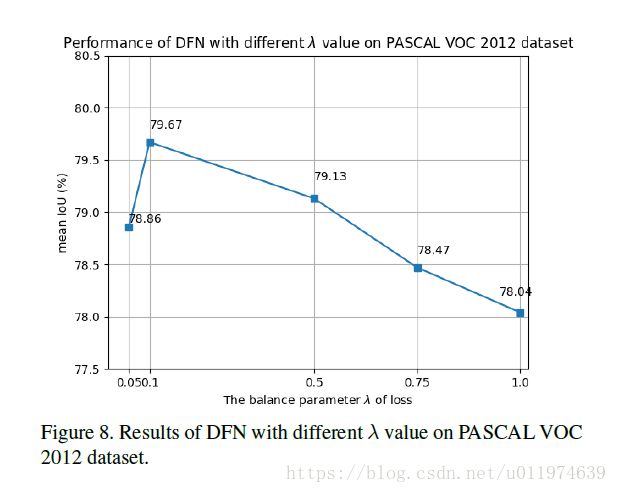
无论是Smooth Network还是Border Network都是采取了逐stage的策略。下面是该策略的可视化结果:

PASCAL and Cityscape

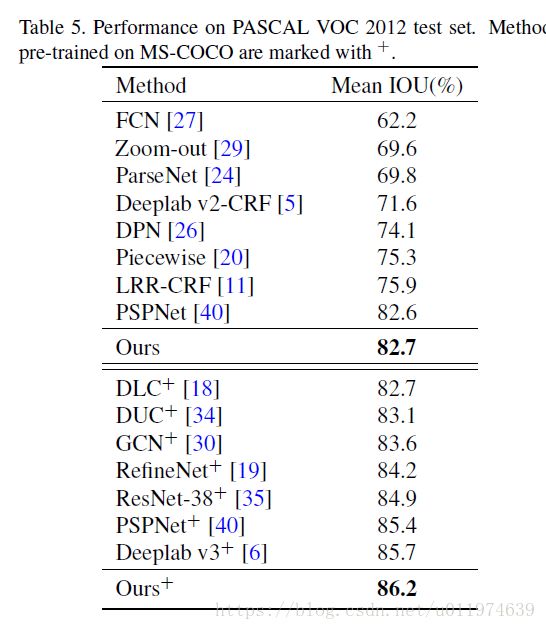
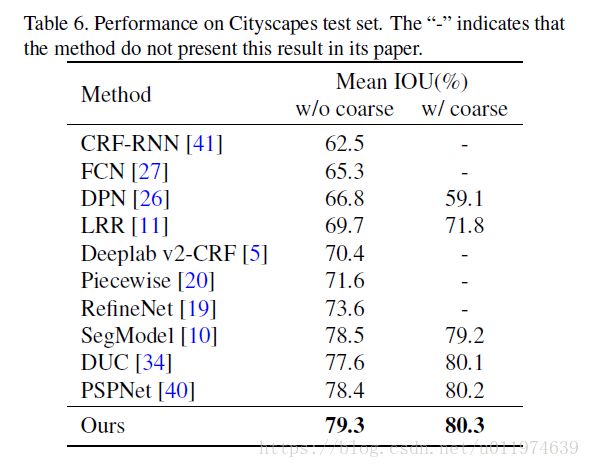
Conclusion
论文从更为宏观的角度审视语义分割任务,认为现存的语义分割任务存在两个挑战:intra-class inconsistency和inter-class indistinction。针对这两个挑战,论文分别提出了Smooth Network还是Border Network。在次基础上,提出了完整的结构DFN,实验结果证明了新模型的有效性。