C实用技巧
以下是我总结的程序里面常见的C用法和技巧。
1.printf输出数据格式:
下面一段代码:
#include
int main()
{
int i = 0x200, j = 0x2;
printf("%2x\n", i);
printf("%02x\n", j);
}
在Visual Studio 验证,运行结果:200 02
x 表示以十六进制的输出格式,%02x 表示输出占两个字符的位置,不足两位,前面补0输出;超出两位限定值,按原值全部输出。
2.数组赋值
static const char *table[]
{
[a] = “H”,
[b] = “E”,
[c] = “L”,
[d] = “L”,
[e] = “O”,
};
Linux源码和一些第三方库文件中有类似用法,对数组赋值操作时,可单独对第几个元素进行赋值。比如[1]={…};就是对第一个元素进行赋值。如下:
int num[5] = {1,2,0,0,3};也可以写成
int num[5] = {[0] = 1,[1] = 2,[4] = 3};
也可以给数组下一个连续的元素赋值,比如:
int num[5] = {[1] = a,b,[4] = c};等价于
int num[5] = {0,a,b,0,c,0};
3.数据高低位
a.对于一个16位的二进制数要在内存中分配,
DL = v % 256; //低八位
DH= v / 256; //高八位
"/“是除法后取整数,”%"是除后取余数。
b.分别取一个16位的二进制数的高低位:
#define val16_get_high18(val) ((val>>8)&0xFF)//取高8位
#define val16_get_low18(val) (val&0xFF)//取低8位
把一个32位的二进制数转化成16位二进制数存储:
#define val32_get_high16(val) ((val>>16)&0xFFFF)
#define val32_get_low16(val) (val&0xFFFF)
把一个32位的二进制数转化成8位二进制数存储:
#define val32_get_high8(val) ((val>>24)&0xFF)
#define val32_get_mid8(val) ((val>>16)&0xFF)
#define val32_get_midd8(val) ((val>>8)&0xFF)
#define val32_get_low8(val) (val&0xFF)
4.Gcc优化及去除优化
在很多代码中遇到#pragma GCC optimize (“O3”),这是对代码进行优化,减小代码大小及所占栈空间大小,但是优化后注意字节对齐,不然程序会出现问题。Gcc优化级别分为O0,O1,O2,O3,Os等,O0为不优化。
对部分代码去优化及优化操作:
#pragma GCC push_options
#pragma GCC optimize ("O0")
.......
#pragma GCC pop_options
还有通过volatile关键字也可以禁止Gcc优化。
5.ceil/floor函数
ceil(val)向上取整函数,返回大于或者等于指定表达式val的最小整数;
floor(val)向下取整函数,返回参数不大于val的最大整数。比如:
ceil(3.1415)=4;
floor(3.1415)=3;
6.do while(0)语句
do while(condition)表示循环语句,但是也用在了宏定义中,比如这种代码形式:
#define hal do {\
/*code*/
}while(0)
这种形式常见的用于宏定义,在这里,是保证循环体语句的一次执行,为了宏展开的时候不会出错,如直接放在花括号会出错的。比如:
#define hal {code1;code2} //{...}可以是定义多个变量或者函数
作用:
(1)替代{},实现局部作用域.在一些C的实现里也可以用;
(2)避免使用goto,用break语句跳出。类似于
while(true){
...
break;
}
(3)补充空宏定义,避免一些warning
#define hal do {}while(0)
7.字节对齐
常见#pragma pack(n) 和 attribute((aligned)) 这两种对齐方式。在默认缺省情况下,编译器一般按自然对界条件给变量和数据单元分配内存空间,要改变默认缺省字节对齐方式就通过这两种方式。先介绍#pragma pack(n)用法:
使用#pragma pack(n),指定变量按照n个字节对齐;
使用#pragma pack(),取消自定义字节对齐方式。
如默认情况下(实验基于KEIL,不同的系统硬件环境,不同的编译器结果可能不一样):
typedef struct {
int a;
char b;
short c;
}A;
由于编译器默认对结构体数据成员进行对齐,有插入的空字节,就是占8个字节的空间,如果用我们指定的字节对齐方式,如:
#pragma pack (1)
typedef struct {
int a;
char b;
short c;
}A;
这样sizeof(A)运行结果就是7个字节。下面再来介绍__attribute__((aligned))的用法:
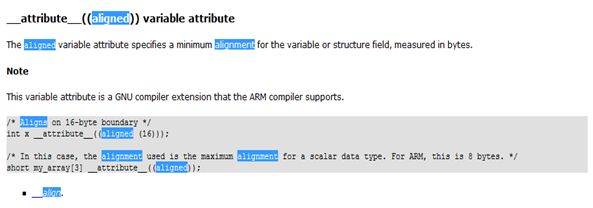
attribute((aligned)) 以字节为单位按照变量或者结构体的最小长度进行对齐。
__attribute((aligned (n))) 指定变量或者结构体数据成员对齐在n字节自然边界上。若数据成员的长度大于n,则按照最大数据成员的长度来对齐。
attribute ((packed)),取消指定变量或者结构体数据成员在编译过程中的优化对齐,按照实际占用字节数进行对齐。
如:
typedef struct {
int a;
char b;
short c;
}__attribute__((aligned)) A;
sizeof(A)所占是8个字节;如果限定字节对齐:
typedef struct {
int a;
char b;
short c;
}__attribute__((aligned(16))) A;
sizeof(A)所占是10个字节。比如在32位系统一般会按照4字节协议来进行字节对齐。这样合理使用字节对齐可以提高CPU访问速度和节省内存空间。如果32位系统中按照>4或着<4字节来对齐(2^n来对齐),CPU一般会读取多次,这样降低了访问效率。参考来自KEIL help文档:
更多技术文章请关注:
百家号:
https://author.baidu.com/home?context=%7B%22app_id%22%3A%221646108714303504%22%7D&wfr=bjh
头条号:
https://www.toutiao.com/c/user/8115738721/#mid=1646025109246987