Hadoop详解(一)——大数据和Hadoop的简介、Hadoop伪分布式的安装步骤
大数据简介
大数据体现

以上几个例子体现了大数据无处不在。
目前很多网络巨头都在使用大数据

分析趋势,随着互联网对网民的理解,网民对网络的反作用,互联网将变得越来越智能,它在满足用户需求的同时,也在创造新的需求。
谷歌的盈利在于所有的软件应用都是在线的,用户在免费使用这些软件产品的同时,把个人的行为、喜好等信息也免费的送给了谷歌。因此,谷歌的产品越丰富,它对用户的理解就越深入,它的广告就越精准,广告的价值就越高。
这是正向的循环,谷歌利用好用的、免费的软件产品,换取对用户的理解,通过精准的广告,找到生财之路,颠覆了微软卖软件拷贝赚钱的模式,成为互联网的巨头。
什么是大数据?
大数据并不仅仅指海量数据,而是指数型增长的海量数据。

注意:大数据并不是云计算,云计算指的是数据处理技术。大数据是以数据融合、综合处理为方向。
大数据的4V特性
① 体量Volume。非结构化数据的超大规模和增长,占据总数据量的80%~90%,比结构化数据增长快到10倍到50倍,是传统数据的10倍到50倍。
② 多样性Variety。大数据的异构和多样性,存在很多不同的形式(文本、图像视频、机器数据)。无模式或者模式不明显,语法或语义不连贯。
③ 价值密度Value。存在很多大量不相关的信息,用来对未来趋势与模式的可预测分析,深度复杂分析(机器学习、人工智能VS传统商务智能(咨询、报告等))
④ 速度Velocity。实时分析而非批量式分析,数据输入、处理与丢弃,立竿见影而非事后生效。
特性的具体体现如下:
-Value 价值:
挖掘大数据的价值类似于沙里淘金,从海量数据中挖掘出稀疏但珍贵的信息。价值密度低是大数据的一个典型特征。

-Variety 多样性
企业内部的经营交易信息;物联网世界中商品,物流信息;互联网世界中人与人交互信息,位置信息是大数据的主要来源。能够在不同的数据模型中,进行交叉分析的技术,是大数据的核心技术之一,包括语义分析技术,图文转换技术,模式识别技术,地理信息技术等,都会在大数据分析时获得应用。

-Velocity 速度
1s 是临界点
对于大数据应用而言,必须在1秒内形成答案,否则处理结果就是过时和无效的。
实时处理的要求,是区别大数据引用和传统数据仓库技术,BI技术的关键差别之一。
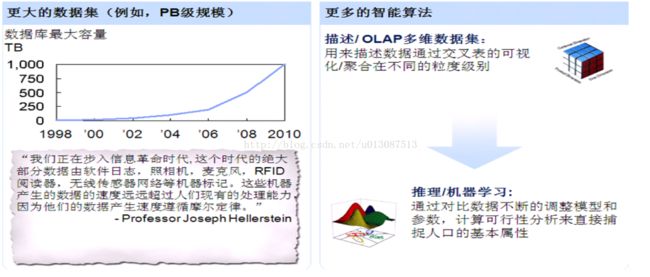
-Volume 数据量
PB是大数据的临界点 KB->MB->GB->TB->PB->EB->ZB->YB->NB->DB
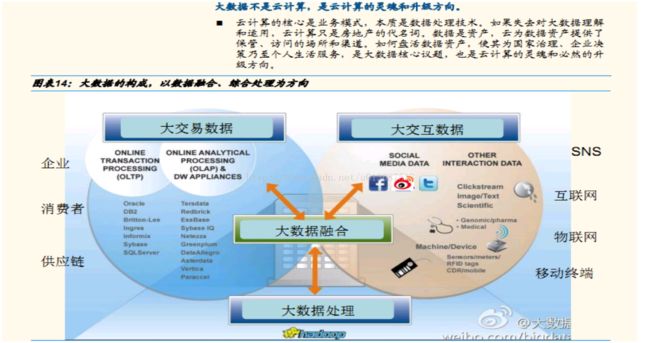
大数据的组成和展现方式
大数据的组成
大数据的展现方式:大型控制中心、移动终端

在多样性、体量、速度三大主要特征的指引下,大数据将有新型的展现方式:大型控制中心和移动终端,实现数据的实时处理和快速决策。
哪些公司使用Hadoop
雅虎北京全球软件研发中心、中国移动研究院,英特尔研究院,金山软件,百度,腾讯,新浪,搜狐,淘宝,IBM,FaceBook,Amazon,Yahoo
Hadoop简介
Hadoop是什么?
官方解释是:
What Is Apache Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
Hadoop是一个开源,可靠,可扩展的分布式计算软件。
Hadoop用于解决以下问题:
- 海量数据的存储(HDFS)
- 海量数据的分析(MapReduce)
- 资源管理调度(YARN)
作者:Doug Cutting
受Google三篇论文的启发(GFS、MapReduce、BigTable)
始于apache项目Nutch
2003年Google发表了关于GFS的论文
2004年Nutch的开发者开发了NDFS
2004年Google发表了关于MapReduce的论文
2005年MapReduce被引入了NDFS
2006年改名为Hadoop,NDFS的创始人加入Yahoo,Yahoo成立了一个专门的小组发展Hadoop
Hadoop大事记
2004年 -- 最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
2005年12月 -- Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2006年01月 -- Doug Cutting加入雅虎。
2006年02月 -- Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年02月 -- 雅虎的网格计算团队采用Hadoop。
2006年04月 -- 标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
2006年05月 -- 雅虎建立了一个300个节点的Hadoop研究集群。
2006年05月 -- 标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年11月 -- 研究集群增加到600个节点。
2006年12月 -- 标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2007年01月 -- 研究集群到达900个节点。
2007年04月 -- 研究集群达到两个1000个节点的集群。
2008年04月 -- 赢得世界最快1TB数据排序在900个节点上用时209秒。
2008年10月 -- 研究集群每天装载10 TB的数据。
2009年03月 -- 17个集群总共24 000台机器。
2009年04月 -- 赢得每分钟排序,59秒内排序500 GB(在1400个节点上)和173分钟内排序100 TB数据(在3400个节点上)。
hadoop具体能做什么工作?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
Hadoop整体流程
(1) 这一切起源于web上庞大的数据。
(2) 使用Nutch抓取WEB数据。
(3) 要保存web上庞大的数据—HDFS应运而生。
(4) 如何使用这些庞大的数据?
(5) 采用Java或任何的流/管道语言构建MapReduce框架用于编码并进行分析。
(6) 如何获取web日志,点击流,Apache日志,服务器日志等非结构化数据—fuse,webdav,chukwa,flume,scribe
(7) Hiho和sqoop将数据加载到HDFS中,关系型数据库也能加入到Hadoop队伍中。
(8) MapReduce编程需要的高级接口—Pig,Hive,Jaql。
(9) 具有先进的UI报表工具的BI工具—Intellicus。
(10) Map-Reduce处理过程使用的工作流工具及高级语言。
(11) 监控、管理Hadoop,运行jobs/hive,查看HDFS的高级视图—Hue,karmasphere,eclipse plugin,cacti。
(12) 支持框架—Avro (进行序列化),ZooKeeper(用于协同)。
(13) 更多高级接口—Mahout,Elastic map Reduce。
(14) 同样可以进行OLTP—Hbase.
Hadoop版本
Apache 官方版本(2.x.x)
Cloudera:使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
HDP(Hortonworks Data Platform) Hortonworks公司发行版本。
hadoop的核心:
HDFS: Hadoop Distributed File System 分布式文件系统
YARN: Yet Another Resource Negotiator 资源管理调度系统
如何解决海量数据的存储和海量数据的运算?
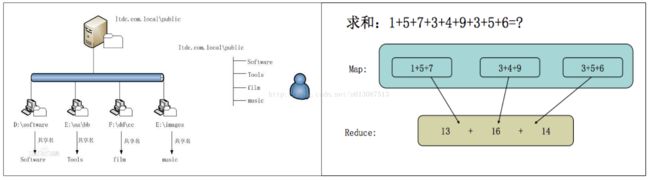
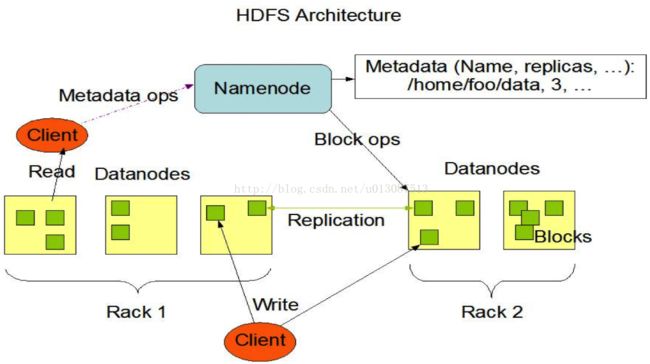
HDFS的架构
主从结构:主节点,只有一个活跃的NameNode;从节点,有很多个DataNode。
NameNode负责:
- 接收用户操作请求;
- 维护文件系统的目录结构;
- 管理文件与Block之间的关系,Block与DataNode之间的关系;
DataNode负责:
- 存储文件;
- 文件被分成Block存储在磁盘上;
- 为保证数据安全,文件会有多个副本;
如下图所示:
Hadoop的特点
扩容能力(Scalable):能可靠的(reliably)存储和处理千兆(PB)字节。
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达上千个节点。
高效率(Efficient):通过分发数据,Hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常快速。
可靠性(Reliable):Hadoop能自动维护数据的多份副本,并且在任务失败后能自动的重新部署(reploy)计算任务。
Hadoop1.0和Hadoop2.0对比

Hadoop1.0没有yarn,计算框架非常单一只有MapReduce。2.0之后所有的计算框架都要基于YARN平台。
Hadoop部署方式
本地模式:在使用开发工具进行开发调试的时候使用的 只能启动一个map和一个reduce,适用于开发环境。
伪分布式:通过一台机器模拟分布式环境,在开发和学习时使用。适用于测试环境
集群模式:真实的开发环境。
Hadoop伪分布式安装
一.准备Linux环境
HOSTNAME=hadoop0
TYPE=Ethernet
UUID=1c433f4c-52e9-4be9-b48c-72889419c875
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static ####
IPADDR=192.168.0.3 ####
PREFIX=24
GATEWAY=192.168.0.1 ####
DNS1=8.8.8.8 ####
NETMASK=255.255.255.0 ####
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
HWADDR=08:00:27:47:CD:00
LAST_CONNECT=1504084493
127.0.0.1 localhost
二.安装JDK
三.安装Hadoop2.7.4
export JAVA_HOME=/usr/java/jdk1.8.0_144
fs.defaultFS
hdfs://hadoop0:9000
hadoop.tmp.dir
/cloud/hadoop-2.7.4/tmp
dfs.replication
1
mv mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
yarn.resourcemanager.hostname
hadoop0
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
1
vim /etc/profile
export HADOOP_HOME=/cloud/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
hdfs namenode -format (hadoop namenode -format)
3827 ResourceManager
3673 SecondaryNameNode
3931 NodeManager
3372 NameNode
3502 DataNode
4142 Jps
yarn 的老大是ResourceManager 负责资源的分配和调度
yarn的小弟是NodeManager NodeManager可以有一个或多个
NameNode是HDFS的老大 负责接收用户请求,接收一些元数据,维护目录树的映射关系 真正的集群有多个NameNode 防止宕机 出现事故 分为主机和备机
DataNode是HDFS的小弟 负责存储部分数据,可以有多个DataNode
SecondaryNameNode 并不是NameNode的热备,只是NameNode的一个助理,帮助NameNode完成一些事情(帮助主数据进行同步 合并一些数据文件)
)http://192.168.0.3:8088 (MR管理界面)
四.配置ssh免登陆
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
ssh-copy-id localhost
比如A 要免登陆远程访问 B 需要将A的公钥发送给主机B