Pandas数据探索与实践
Pandas数据探索与实践
介绍
只要我们要用Python来做数据分析,就避免不了用到Pandas。Python有很多用于数据清洗和数据准备的库,但是很少有数据分析和数据建模的库。Pandas的出现,使得我们能在Python中解决大多数数据分析的问题,而不用切换到一些特殊语言如R中,这样就减少了我们许多的工作量。
内容
- Pandas下载与基本教程
- Pandas数据探索的基本流程
- 用Pandas对Titanic数据进行初步探索
Pandas下载与基本教程
我们可以从官网上下载Pandas,也可以在终端中直接下载:
easy_install pandas
Pandas的简单教程是Pandas作者Wes McKinney写的10-minute tour of pandas。
不过要认真学习Pandas的话还应该买一本作者的书:

Pandas数据探索基本流程
在数据处理中,我们经常会有一些常用的步骤,比如读取数据,处理缺失值等。这里我们就把这些常用步骤的Pandas实现方法一一给出。
读写数据
df = pd.read_csv('data.csv')
df.to_csv('rename.csv')
df = pd.read_excel('data.xlsx','sheet1')
df.to_excel('rename.xlsx',sheet_name = 'sheet2')
预览数据
df.head() #查看数据头几个
df.tail() #查看数据最后几个
df.columns #查看数据的变量
选择行或列
df[['col1','col2']] #选择col1列和col2列
df[df['col1'] > 10] #选择col1大于10的所有列
df[[df['col1'] > 10]&df['col2'] ==30]
重命名列
df2 = df.rename(columns={'old_colname':'new_colname'})
df.rename(columns={'old_colname':'new_colname'},inplace=True)
处理缺失值
df1.dropna() #把带有缺失值的样本去处
df2.fillna(value=5)
mean = df2['col1'].mean()
df2['col1'].fillna(mean)
创建新变量
df['newcol1'] = df['col2']
df['newcol2'] = df['col2'] + 10
df['newcol3'] = df['col1'] + df['col2']
总和
df.groupby('col1').sum()
df.groupby(['col1','col2']).count()
pd.crosstab(df.col1,df.col2)
合并
pd.concat([df1,df2])
pd.merge(df1,df2,left=True,right=True)#这个是主要用的。
函数
df['col1'].map(lambda x: 10+x)
df['col2'].map(lambda x:'data' + x)
df[['col1','col2']].apply(sum)
func = lambda x: x+2
df.applymap(func)
确定唯一值
df['col1'].unique()
简单统计
df.describe() #生成基本统计数据
df.cov() #生成协方差
df.corr() #得到相关系数
Pandas实战
通过对上述知识的学习,我们知道了数据分析探索的一点点过程。下面我们就进行一些实战,把这些东西巩固一番。
获取数据
首先,我们的数据来自于kaggle的泰坦尼克号,我们从中获取数据,一个是训练数据,用来训练模型,一个测试数据,用来评估模型。数据分析探索主要是利用训练数据。

读取数据
得到数据之后,我们就要读取数据,其数据格式为csv,我们就可以使用上面所述的方法,进行读取.

这里我用的是ipython的notebook,有兴趣的可以自己去看看。前面都是引入模块,最后才是读取数据。
了解数据
读取完数据之后,我们就要看看数据的结构,有多少个变量,多少个样本。
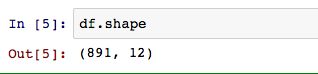
这样我们就知道,这个数据有12个变量,891个样本。知道大概结构后,我们又想知道,变量有哪些?变量的类型是什么?

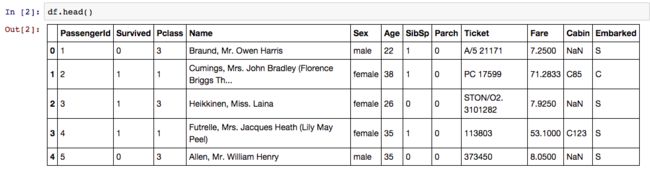
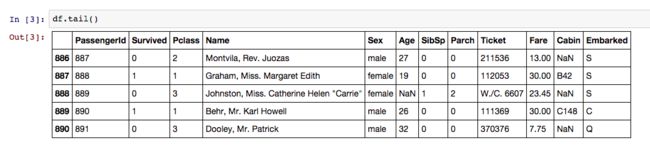
这样我们就知道了数据变量有PassengerID,Survived,Pclass,Age,Name,Sex,SibSp,Parch,Ticket,Fare,Cabin,Embarked12个,结合kaggle上对这些变量的描述,我们就对这些变量的类型有所了解。
探索数据
于是我们就开始了数据探索与数据清洗之旅。遇到数据处理,我们首先处理信息量比较多的变量,一般先是连续型变量,接着是分类变量,然后才是文本,而对于一些对我们预测数据无关紧要的变量,可以选择直接删除。
在这我们就只有年龄和船费为连续型变量,我们先要处理年龄这个常见变量。我们先要看看其是否有缺失值。
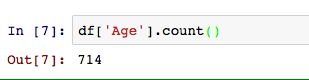
这里我们就看出来缺失值有177个,占总样本20%,不算太多,也不算太少。对于异常值的处理,我会另外写一篇文章,专门介绍异常值的处理,这里我们就用常用的方法——平均值代替。

我们分析一下Age的数值度量:
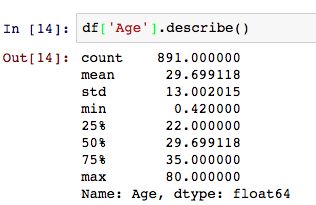
其中位数与均值相同,我们初步判定其为正态分布,要确定是否为正态分布,还需要将其可视化,其可视化方法,在我的另一篇文章有说过。
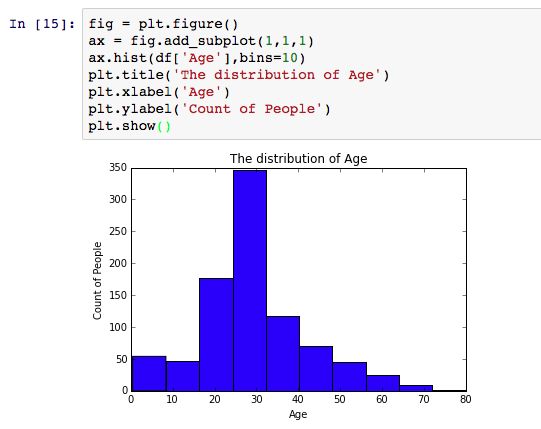
从这里我们就可以看出,连续型变量Age趋近于正态分布。接下来以同样的方法分析船费。
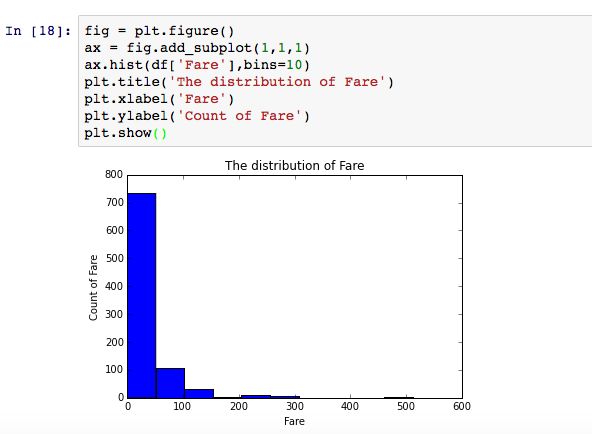
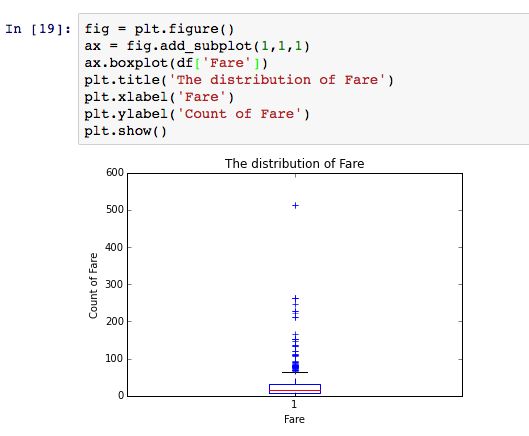
可以看出,船费不是正态分布,其有少许异常值,需要进行一些处理后才能建模。
探索分类数据
对于分类数据的探索,我们应根据分类数据对目标数据的影响来分析,比如我们可以看Pclass对Survived的影响。
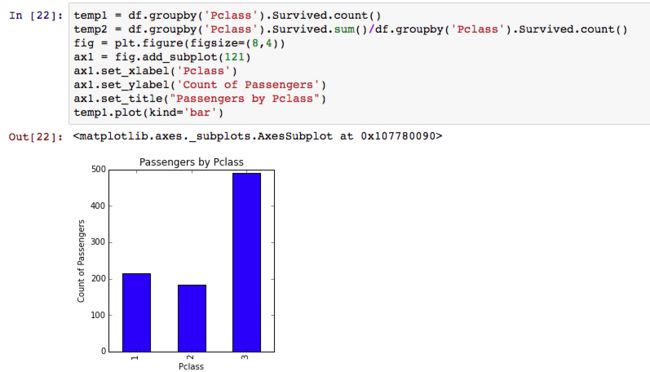
Pclass第三层存活的人数比较多,也可能会是因为人数比较多,所以存活人数多,主要要看存活比率。
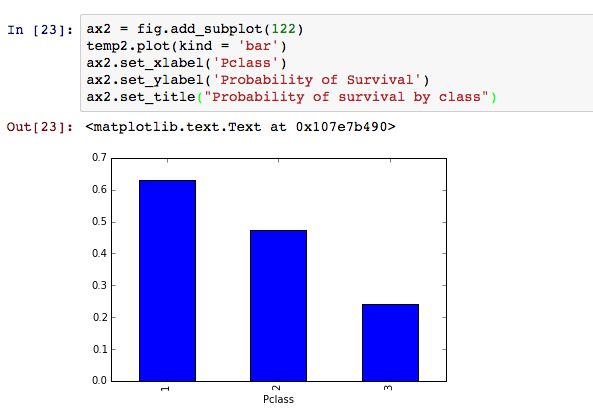
这样就可以看出,1层的存活率比较高。其实我们还可以看看,Sex和Pclass对Suvived影响

结束语
这样,我们就简单的探索了一下基本的变量,得到了一些变量的基本概貌。还有很多的问题等待我们去解决,如何处理异常值值?名称是否与生存率有关?我们用什么算法去建立模型?这些问题让数据分析变的无比的吸引人。
参考
http://www.analyticsvidhya.com/blog/2014/09/data-munging-python-using-pandas-baby-steps-python/