如何将知识分离出来?
作者在论文中argue到,CNN在设计的过程中有一个固有的无效性,因为他们会将color,shape和纹理信息一起处理(感觉可以找个时间介绍一些,图像中的color,shape或者texture信息对于图像的特征提取有哪些帮助作用)。但是实际上这些不同的信息,比如color或者shape,texture对于识别来说的话,应该是包含不同的数量的信息的。作者举了一个例子,一个人刚开始看一个物体的时候,需要看到完整地,细节地物体的边界,从而能够得到具有辨别性的shape编码。但是color和texture就相对包含一些low-level的信息,意思是,对于物体的识别就没有轮廓那么重要。这种思路实际上可以解释为什么resnet需要residual skip来提升网络的性能,或者是dense connection。以你为,通过添加这种additional connectivity能够帮助不同类型的信息通过不同scale的深度进行融合流通(个人感觉这个说服力对于解释为什么resnet work比较有说服力)。
这篇文章做了啥?
作者说到,在这篇文章中,他们提出了一个新的,two-stream CNN,能够显式的讲shape information独立成一个processing branch。两个stream,分别是传统cnn的stream,另外一个是shape stream,能够并行的处理信息。除了非常顶层的layer,作者说不允许两个stream信息的融合。
作者说到这篇文章的主要核心就是用一个门来控制两路信息的交互。具体来讲就是,作者利用传统cnn stream的high-level的information来denoise前几层shape stream的activations。这么一操作,shape stream能够有效的处理相关的信息。而且只使用比较浅的网络。为了能够使得shape information,作者在shape stream上添加了语义边界loss。我们更进一步的利用了一个新的loss function,来使得segmentation result和gt进行对齐。
并且作者还说道,他们的GSCNN是plug-and-play的,可以用在任何cnn上。作者做了大量的实验,比deep lab-v3的结果在miou指标上高了1.5个百分点,在f-boundary指标上高了4%个百分点。而且作者说他们的实验结果在一些很小的物体上的表现性能会更好,比如电线杆,交通标识或者交通灯等。
相关工作的介绍
语义分割进展
作者貌似说文献6已经有人用边界信息来refine实验结果,但是和他们不一样的是,作者是inject the learned boundary information到cnn的中间层,而不是最终的结果。作者还指出,之前文献42也用了two stream network,但是他们是恢复由pooling降低的高分辨率的feature。文献15,35,48提出了用于学习结构信息pixel级别的仿射信息,他们主要用来学习一个特定信息传播模块,作者提出的是学习高质量的shape information。
multitask learning
有一些工作是用来提出互补任务的学习。作者的目标并不是训练一个多任务的网络,而是能够通过利用分割和边界对偶性质来加强结构化信息的表示。文献12,4能够同时学习分割和边界检测的结果。31和40能够学习intermediate的表示来辅助分割结果。但是这些工作对于边界的约束只在loss function上,作者直接将边界信息注入到网络的中间层去,并且提出了一个对偶任务loss来同时refine 分割的mask和边界预测的结果。
gated convolution
最近的在语言模型上的研究表明卷积上的gating mechanism是有效果的,比如文献14提出了取代循环网络中的循环connection的gated temporal convolution。文献53提出了一个soft-gating的图像不全的机制。文献46提出了gated pixelcnn来做图像生成。这里作者用gated covolution opreator来做语义分割以及控制两个stream信息之间的流动。
Gated Shape CNN
相当于是作者把shape这一个分支独立出来,因为考虑到shape对于分割而言是非常具有意义的,其实对于很多任务而言都是具有意义的,比如双目深度估计或者是单目深度估计,都是比较有意义的。作者整体的pipline如下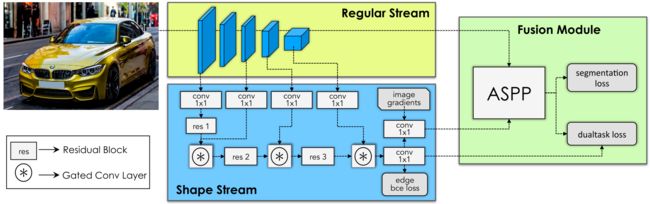
作者整体的pipline如上图,就是用backbone接出来几路,用于做gate相关的东西,作者代码里面写的很详细
我将作者代码的detail绘制了一个图,如下

最终网络的输出是一个edge map,一个是分割的结果。
关于边缘图,相当于作者是用一个branch,单独输出最终的边缘图,这种边缘图可以指导网络分割的结果。
随便可视化了一张图片,原图如下图所示,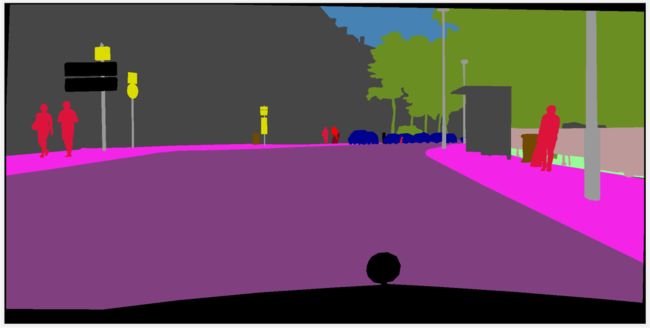
根据分割图获取的边缘图的ground truth如下图所示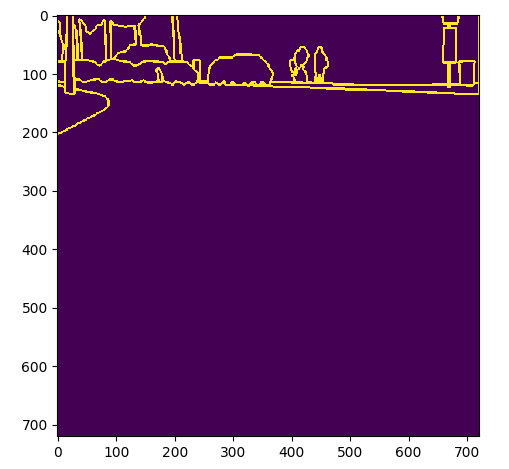
当然,下图是作者对于上图的gt增强的的结果。
作者将输出的edge_out和candy算子得到的结果一起concate到aspp中,关于aspp,只deeplab-v3提及的一个模块。下面是ASPP代码的解析
ASPP代码模块解析
看了一下ASPP作者的代码,当然在这里作者融合了edge的信息,代码块如下
class _AtrousSpatialPyramidPoolingModule(nn.Module):
'''
operations performed:
1x1 x depth
3x3 x depth dilation 6
3x3 x depth dilation 12
3x3 x depth dilation 18
image pooling
concatenate all together
Final 1x1 conv
'''
def __init__(self, in_dim, reduction_dim=256, output_stride=16, rates=[6, 12, 18]):
super(_AtrousSpatialPyramidPoolingModule, self).__init__()
# Check if we are using distributed BN and use the nn from encoding.nn
# library rather than using standard pytorch.nn
if output_stride == 8:
rates = [2 * r for r in rates]
elif output_stride == 16:
pass
else:
raise 'output stride of {} not supported'.format(output_stride)
self.features = []
# 1x1
self.features.append(
nn.Sequential(nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True)))
# other rates
for r in rates:
self.features.append(nn.Sequential(
nn.Conv2d(in_dim, reduction_dim, kernel_size=3,
dilation=r, padding=r, bias=False),
Norm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features = torch.nn.ModuleList(self.features) # 经过计算,发现四者的size是一样的
# img level features
self.img_pooling = nn.AdaptiveAvgPool2d(1)
self.img_conv = nn.Sequential(
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True))
self.edge_conv = nn.Sequential(
nn.Conv2d(1, reduction_dim, kernel_size=1, bias=False),
Norm2d(reduction_dim), nn.ReLU(inplace=True))
def forward(self, x, edge):
x_size = x.size()
img_features = self.img_pooling(x)
img_features = self.img_conv(img_features)
img_features = F.interpolate(img_features, x_size[2:],
mode='bilinear',align_corners=True)
out = img_features
edge_features = F.interpolate(edge, x_size[2:],
mode='bilinear',align_corners=True)
edge_features = self.edge_conv(edge_features)
out = torch.cat((out, edge_features), 1)
for f in self.features:
y = f(x)
out = torch.cat((out, y), 1) # 二者concate在一起经过aspp
return out
ASPP是另外一篇文章提出来的,这里作者只是,将backnone和最后输出的edge信息在一起输入了aspp。aspp实际上是利用四路不同的空洞卷积并行处理输入的feature map,不同的空洞卷积的dilation不同,感受野也不一样,这对于提取不同尺度的信息。从上面的这个module可以看出,作者最后将上采样得到的edge_features和out concate到一起,然后依次经过ASPP模块,一个很自然的问题是,ASPP四路并行,虽然用不同的dilation和padding,尽管strid一样,如何能够保证输出的feature map的尺寸一样,使之能够concate到一起?
根据输出的feature map的尺寸计算公式
从上面这个公式可以看出,如果要保证\(W_{output}\)是一样的话,\(s\)固定,则需要保证\(\frac{W_{in}+2*pading-dilation*(k-1)-1\)对于不同的dilation是一样的,这就是ASPP实现的关键。因为\(W_{in}\)是固定的,所以就需要保证\(2*pading-dilation*(k-1)\)对于不同的dilation是一样的,显然,仔细观察上面的self.features的卷积参数,作者第一个的卷积的padding默认是0,kernel size默认是1,所以20-1(1-1)=0。对于剩下的卷积里面的参数,padding都是为dilation,k为3,所以2*dilation-dilation(3-1)=0,可以看出,这样就能够保证不同dilation输出的feature map的尺寸是一样的,这样后续的concate就会方便很多。
loss
作者定义了四个loss,对于分割或者是edge检测的结果,分别定义了cross entropy loss。然后还定义了对偶loss,关于对偶loss,作者的两个对偶loss分别定义如下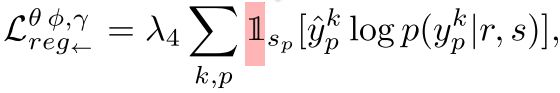
另外一个对偶loss,作者说探究了边界以及分割的结果,也并没有看太懂,但是一个值得学习的点就是作者用一个可微的函数替代了argmax操作,感觉这个还是挺值得学习的。
实验结果
作者在cityspace数据集合上达到了比较好的实验结果。并且作者做了ablation study,说不加gate或者不加candy得到的结果,结果时好时坏。
作者展示了一下,shape stream最终输出的结果
以及作者展示了一下误差图
可以看出,deep-lab v3的误差是比较小的。
btw,作者也可视化了一下三个gate的实验结果,
越往后越具有高层次的信息。
根据分割的结果,作者能够从分割的结果得到原图的边缘图,可以看出,分割得到的图的边缘还是挺准的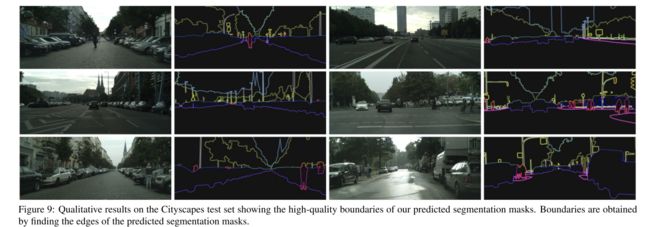
总结一下
感觉这种inject这种low-level相关的信息还是挺值得学习的,就是单独出来一个stream,这种stream与backbone有某种关联,这样可以强化分割得到的结果。这种low指导high level的方向感觉在很多任务中都会用到,也可能是未来的一个研究的方向。