阿里和微博的异地多活方案zt
问题:SNS型不适合单元化?
总结:
多活基本思路:
每个中心都是活的,可以实时承担流量,任何一点出问题,都可以直接切掉,由另外一点直接接管,非传统的两地三中心冷备方式。
挑战及解决方法:
服务延时。
让操作全部在同一中心内完成,单元化
比如用户进入以后,比如说在淘宝上看商品,浏览商品,搜索、下单、放进购物车等等操作,还包括写数据库,就都是在所进入的那个数据中心中完成的,而不需要跨数据中心
部署:
异地部署的是流量会爆发式增长的,流量很大的那部分。流量小的,用的不多的,不用异地部署。
其他一些功能就会缺失,所以我们在异地部署的并非全站,而是一组业务,这组业务就成为单元
比如:在异地只部署跟买家交易相关的核心业务,确保一个买家在淘宝上浏览商品,一直到买完东西的全过程都可以完成
路由一致性:
买家相关的数据在写的时候,一定是要写在那个单元里。要保障这个用户从进来一直到访问服务,到访问数据库,全链路的路由规则都是完全一致的。如果说某个用户本来应该进A城市的数据中心,但是却因为路由错误,进入了B城市,那看到的数据就是错的了。造成的结果,可能是用户看到的购买列表是空的,这是不能接受的。
延时:
异地部署,我们需要同步卖家的数据、商品的数据。能接受的延时必须要做到一秒内,即在全国的范围内,都必须做到一秒内把数据同步完
中心之间骨干网。
数据一致性:
把用户操作封闭在一个单元内完成,最关键的是数据。在某个点,必须确保单行的数据在一个地方写,绝对不能在多个地方写。
为了做到这一点,必须确定数据的维度。淘宝除了用户本身的信息以外,还会看到所有商品的数据、所有卖家的数据,面对的是买家、卖家和商品三个维度。因为异地的是买家的核心链路,所以选择买家这个维度。按买家维度来切分数据。但因为有三个维度的数据,当操作卖家、商品数据时,就无法封闭。
在所有的异地多活项目中,最重要的是保障某个点写进去的数据一定是正确的。这是最大的挑战,也是我们在设计整个方案中的第一原则。业务这一层出故障我们都可以接受,但是不能接受数据故障。
多个单元之间一定会有数据同步。一方面,每个单元都需要卖家的数据、商品的数据;
另一方面,我们的单元不是全量业务,那一定会有业务需要这个单元,比如说买家在这个单元下了一笔定单,而其他业务有可能也是需要这笔数据,否则可能操作不了,所以需要同步该数据。
所以怎样确保每个单元之间的商品、卖家的数据是一致的,然后买家数据中心和单元是一致的,这是非常关键的。
-------------------
http://mp.weixin.qq.com/s?__biz=MzAwMjQ5NjM0Ng==&mid=205245348&idx=2&sn=e335139f3f69b899afc1b2ca5e63d24c&3rd=MzA3MDU4NTYzMw==&scene=6#rd
昨日(5月27日)下午17时许,支付宝被多网友反映故障,18时许,支付宝通过微博给出回应,坦承系统故障,并做出解释原因为光缆被挖。19时许,支付宝服务恢复正常。
而事实上,支付宝服务恢复正常之后,事故的罪魁祸首——被挖断的光缆,还并没有被还原。对此次事故的做出快速响应并帮助解除的正是——异地多活系统。
那么,阿里的异地多活到底有那些优势?项目又是如何部署?成功部署一个异地多活项目需要攻克的堡垒又有哪些?如果阿里的异地多活其他公司对异地多活又是如何部署的?本文将从回顾InfoQ对阿里异地多活项目主导者毕玄的专访,及新浪微博刘道儒对微博的“异地多活”经验谈中一起寻找答案。
异地多活是什么
所谓异地多活,故名思义,就是在不同地点的数据中心起多个我们的交易,并且每个地点的那个交易都是用来支撑流量的。
异地多活是如何部署的
首先来看看阿里对于为什么做这件事儿,毕玄做出的回答:
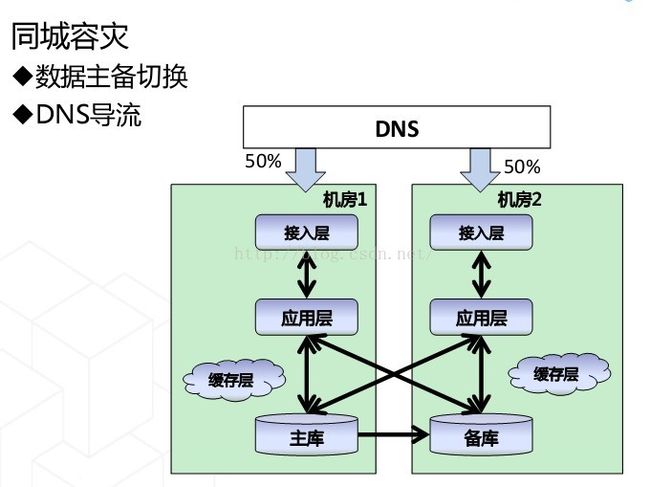
其实我们大概在2009还是2010年左右的时候,就开始尝试在异地去做一个数据中心,把我们的业务放过去。更早之前,我们做过同城,就是在同一个城市建多个数据中心,应用部署在多个数据中心里面。同城的好处就是,如果同城的任何一个机房挂掉了,另外一个机房都可以接管。
做到这个以后,我们就在想,异地是不是也能做到这样?
整个业界传统的做法,异地是用来做一个冷备份的,等这边另外一个城市全部挂掉了,才会切过去。我们当时也是按照这个方式去尝试的,尝试了一年左右,我们觉得冷备的方向对我们来讲有两个问题:第一个问题是成本太高。我们需要备份全站,而整个阿里巴巴网站,包括淘宝、天猫、聚划算等等,所有加起来,是一个非常大的量,备份成本非常高。第二个问题是,冷备并不是一直在跑流量的,所以有个问题,一旦真的出问题了,未必敢切过去。因为不知道切过去到底能不能起来,而且整个冷备恢复起来要花多长时间,也不敢保证。因此在尝试之后,我们发现这个方向对我们而言并不好。
那为什么我们最后下定决心去做异地多活呢?
最关键的原因是,我们在2013年左右碰到了几个问题。首先,阿里巴巴的机房不仅仅给电商用,我们有电商,有物流,有云,有大数据,所有业务共用机房。随着各种业务规模的不断增长,单个城市可能很难容纳下我们,所以我们面临的问题是,一定需要去不同的城市建设我们的数据中心。其次是我们的伸缩规模的问题。整个淘宝的量,交易量不断攀升,每年的双十一大家都看到了,增长非常快。而我们的架构更多还是在2009年以前确定的一套架构,要不断的加机器,这套架构会面临风险。
如果能够做到异地部署,就可以把伸缩规模缩小。虽然原来就是一套巨大的分布式应用,但是其实可以认为是一个集群,然后不断的加机器。但是在这种情况下,随着不断加机器,最终在整个分布式体系中,一定会有一个点是会出现风险的,会再次到达瓶颈,那时就无法解决了。
这两个问题让我们下定决心去做异地多活这个项目。
为什么我们之前那么纠结呢?因为整个业界还没有可供参考的异地多活实现,这就意味着我们必须完全靠自己摸索。而且相对来讲,它的风险以及周期可能也是比较大的。
关于项目的具体部署,毕玄说:
以去年双十一为例,当时我们在杭州有一个数据中心,在另外一个城市还有个数据中心,一共是两个,分别承担50%用户的流量。就是有50%的用户会进入杭州,另外50%会进入到另外一个城市。当用户进入以后,比如说在淘宝上看商品,浏览商品,搜索、下单、放进购物车等等操作,还包括写数据库,就都是在所进入的那个数据中心中完成的,而不需要跨数据中心。
优势
异地部署,从整个业界的做法上来讲,主要有几家公司,比如Google、Facebook,这两家是比较典型的,Google做到了全球多个数据中心,都是多活的。但是Google具体怎么做的,也没有多少人了解。另外一家就是Facebook,我们相对更了解一些,Facebook在做多个数据中心时,比如说美国和欧洲两个数据中心,确实都在支撑流量。但是欧洲的用户有可能需要访问美国的数据中心,当出现这种状况时,整个用户体验不是很好。
国内的情况,我们知道的像银行,还有其他一些行业,倾向于做异地灾备。银行一般都会有两地,一个地方是热点,另一个地方是冷备。当遇到故障时,就没有办法做出决定,到底要不要切到灾备数据中心,他们会碰到我们以前摸索时所面对的问题,就是不确定切换过程到底要多久,灾备中心到底多久才能把流量接管起来。而且接管以后,整个功能是不是都正常,也可能无法确定。
刚才也提到过,冷备的话,我们要备份全站,成本是非常高的。
如果每个地点都是活的,这些数据中心就可以实时承担流量,任何一点出问题,都可以直接切掉,由另外一点直接接管。相对冷备而言,这是一套可以运行的模式,而且风险非常低。
挑战
对于我们来讲,异地项目最大的挑战是延时。跨城市一定会有延时的问题。在中国范围内,延时可能在一百毫秒以内。
看起来单次好像没什么,但是像淘宝是个很大的分布式系统,一次页面的展现,背后的交互次数可能在一两百次。如果这一两百次全部是跨城市做的,整个响应时间会增加很多,所以延时带来的挑战非常大。
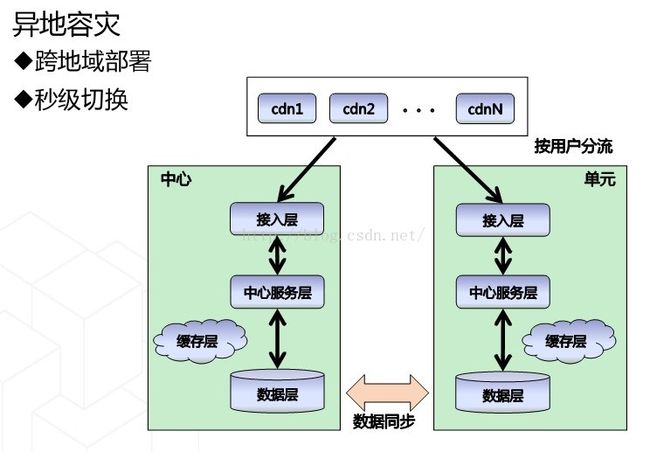
在解决挑战的过程中,我们会面临更细节的一些问题。怎样降低延时的影响,我们能想到的最简单、最好的办法,就是让操作全部在同一机房内完成,那就不存在延时的挑战了。所以最关键的问题,就是怎样让所有操作在一个机房内完成。这就是单元化。
为什么叫单元化,而没有叫其他名字呢?原因在于,要在异地部署我们的网站,首先要做一个决定。比如说,冷备是把整个站全部备过去,这样可以确保可以全部接管。但是多活的情况下,要考虑成本,所以不能部署全站。
整个淘宝的业务非常丰富,其实有很多非交易类型的应用,这些功能可能大家平时用的不算很多。但对我们来讲,又是不能缺失的。这部分流量可能相对很小。如果这些应用也全国到处部署,冗余量就太大了。所以我们需要在异地部署的是流量会爆发式增长的,流量很大的那部分。虽然有冗余,但是因为流量会爆发式增长,成本比较好平衡。异地部署,我们要在成本之间找到一个平衡点。所以我们决定在异地只部署跟买家交易相关的核心业务,确保一个买家在淘宝上浏览商品,一直到买完东西的全过程都可以完成。
其他一些功能就会缺失,所以我们在异地部署的并非全站,而是一组业务,这组业务就成为单元。比如说我们现在做的就是交易单元。
这时淘宝会面临一个比Google、Facebook等公司更大的一个挑战。像Facebook目前做的全球化数据中心,因为Facebook更多的是用户和用户之间发消息,属于社交领域。但淘宝是电商领域,对数据的一致性要求非常高,延时要求也非常高。
还有个更大的挑战,那就是淘宝的数据。如果要把用户操作封闭在一个单元内完成,最关键的是数据。跟冷备相比,异地多活最大的风险在于,它的数据会同时在多个地方写,冷备则不存在数据会写错的问题。如果多个地方在写同一行数据,那就没有办法判断哪条数据是正确的。在某个点,必须确保单行的数据在一个地方写,绝对不能在多个地方写。
为了做到这一点,必须确定数据的维度。如果数据只有一个维度,就像Facebook的数据,可以认为只有一个纬度,就是用户。但是像淘宝,如果要在淘宝上买一个东西,除了用户本身的信息以外,还会看到所有商品的数据、所有卖家的数据,面对的是买家、卖家和商品三个维度。这时就必须做出一个选择,到底用哪个维度作为我们唯一的一个封闭的维度。
单元化时,走向异地的就是买家的核心链路,所以我们选择了买家这个维度。但是这样自然会带来一个问题,因为我们有三个维度的数据,当操作卖家商品数据时,就无法封闭了,因为这时一定会出现需要集中到一个点去写的现象。
从我们的角度看,目前实现整个单元化项目最大的几个难点是:
第一个是路由的一致性。因为我们是按买家维度来切分数据的,就是数据会封闭在不同的单元里。这时就要确保,这个买家相关的数据在写的时候,一定是要写在那个单元里,而不能在另外一个单元,否则就会出现同一行数据在两个地方写的现象。所以这时一定要保证,一个用户进到淘宝,要通过一个路由规则来决定这个用户去哪里。这个用户进来以后,到了前端的一组Web页面,而Web页面背后还要访问很多后端服务,服务又要访问数据库,所以最关键的是要保障这个用户从进来一直到访问服务,到访问数据库,全链路的路由规则都是完全一致的。如果说某个用户本来应该进A城市的数据中心,但是却因为路由错误,进入了B城市,那看到的数据就是错的了。造成的结果,可能是用户看到的购买列表是空的,这是不能接受的。所以如何保障路由的一致性,非常关键。
第二个是挑战是数据的延时问题。因为是异地部署,我们需要同步卖家的数据、商品的数据。如果同步的延时太长,就会影响用户体验。我们能接受的范围是有限的,如果是10秒、30秒,用户就会感知到。比如说卖家改了一个价格,改了一个库存,而用户隔了很久才看到,这对买家和卖家都是伤害。所以我们能接受的延时必须要做到一秒内,即在全国的范围内,都必须做到一秒内把数据同步完。当时所有的开源方案,或者公开的方案,包括MySQL自己的主备等,其实都不可能做到一秒内,所以数据延时是我们当时面临的第二个挑战。
第三个挑战,在所有的异地项目中,虽然冷备成本很高,多活可以降低成本,但是为什么大家更喜欢冷备,而不喜欢多活呢?因为数据的正确性很难保证。数据在多点同时写的时候,一定不能写错。因为数据故障跟业务故障还不一样,跟应用层故障不一样。如果应用出故障了,可能就是用户不能访问。但是如果数据写错了,对用户来说,就彻底乱了。而且这个故障是无法恢复的,因为无法确定到底那里写的才是对的。所以在所有的异地多活项目中,最重要的是保障某个点写进去的数据一定是正确的。这是最大的挑战,也是我们在设计整个方案中的第一原则。业务这一层出故障我们都可以接受,但是不能接受数据故障。
还有一个挑战是数据的一致性。多个单元之间一定会有数据同步。一方面,每个单元都需要卖家的数据、商品的数据;另一方面,我们的单元不是全量业务,那一定会有业务需要这个单元,比如说买家在这个单元下了一笔定单,而其他业务有可能也是需要这笔数据,否则可能操作不了,所以需要同步该数据。所以怎样确保每个单元之间的商品、卖家的数据是一致的,然后买家数据中心和单元是一致的,这是非常关键的。
这几个挑战可能是整个异地多活项目中最复杂的。另外还有一点,淘宝目前还是一个高速发展的业务,在这样的过程中,去做一次比较纯技术的改造,怎样确保对业务的影响最小,也是一个挑战。
解决方案
同样对于异地多活有时间的微博,在与阿里的解决方案进行对比后,也给出了关于解决方案的思考方向,一下是新浪微博刘道儒对于方案选型是需要进行的维度思考给出的方向:
能否整业务迁移:如果机器资源不足,建议优先将一些体系独立的服务整体迁移,这样可以为核心服务节省出大量的机架资源。如果这样之后,机架资源仍然不足,再做异地多活部署。
服务关联是否复杂:如果服务关联比较简单,则单元化、基于跨机房消息同步的解决方案都可以采用。不管哪种方式,关联的服务也都要做异地多活部署,以确保各个机房对关联业务的请求都落在本机房内。
是否方便对用户分区:比如很多游戏类、邮箱类服务,由于用户可以很方便地分区,就非常适合单元化,而SNS类的产品因为关系公用等问题不太适合单元化。
谨慎挑选第二机房:尽量挑选离主机房较近(网络延时在10ms以内)且专线质量好的机房做第二中心。这样大多数的小服务依赖问题都可以简化掉,可以集中精力处理核心业务的异地多活问题。同时,专线的成本占比也比较小。以北京为例,做异地多活建议选择天津、内蒙古、山西等地的机房。
控制部署规模:在数据层自身支持跨机房服务之前,不建议部署超过两个的机房。因为异地两个机房,异地容灾的目的已经达成,且服务器规模足够大,各种配套的设施也会比较健全,运维成本也相对可控。当扩展到三个点之后,新机房基础设施磨合、运维决策的成本等都会大幅增加。
消息同步服务化:建议扩展各自的消息服务,从中间件或者服务层面直接支持跨机房消息同步,将消息体大小控制在10k以下,跨机房消息同步的性能和成本都比较可控。机房间的数据一致性只通过消息同步服务解决,机房内部解决缓存等与消息的一致性问题。跨机房消息同步的核心点在于消息不能丢,微博由于使用的是MCQ,通过本地写远程读的方式,可以很方便的实现高效稳定的跨机房消息同步。