Pseudo-3D Residual Networks 算法笔记
论文:Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
论文链接:http://openaccess.thecvf.com/content_ICCV_2017/papers/Qiu_Learning_Spatio-Temporal_Representation_ICCV_2017_paper.pdf
官方代码:https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
第三方代码:https://github.com/qijiezhao/pseudo-3d-pytorch
ICCV2017的文章。在视频分类或理解领域,容易从图像领域的2D卷积联想到用3D卷积来做,虽然用3D卷积进行特征提取可以同时考虑到spatial和temporal维度的特征,但是计算成本和模型存储都太大,因此这篇文章针对视频领域中采用的3D卷积进行改造,提出Pseudo-3D Residual Net (P3D ResNet),思想有点像当年的Inception v3中用1*3和3*1的卷积叠加代替原来的3*3卷积,这篇文章是用1*3*3卷积和3*1*1卷积代替3*3*3卷积(前者用来获取spatial维度的特征,实际上和2D的卷积没什么差别;后者用来获取temporal维度的特征,因为倒数第三维是帧的数量),毕竟这样做可以大大减少计算量,而如果采用3D卷积来做的话,速度和存储正是瓶颈,这也使得像C3D算法的网络深度只有11层,参看Figure1。该文章的网络结构可以直接在3D的ResNet网络上修改得到。顺便提一下,除了采用3D卷积来提取temporal特征外,还可以采用LSTM来提取,这也是当前视频研究的一个方向。
Figure1是几个模型在层数、模型大小和在Sports-1M数据集上的视频分类效果对比,其中的P3D ResNet是在ResNet 152基础上修改得到的,深度之所以不是152,是因为改造后的每个residual结构不是原来ResNet系列的3个卷积层,而是3或4个卷积层,详细可以看Figure3,所以最后网络深度是199层。官方github代码中的网络就是199层的。ResNet 152是直接在Sports-1M数据集上fine tune得到的。可以看出199层的P3D ResNet虽然在模型大小上比ResNet-152(此处ResNet-152是在sports-1M数据集上fine tune得到的)大一些,但是准确率提升比较明显,与C3D(此处C3D是直接在sports-1M数据集上从头开始训练得到的)的对比在效果和模型大小上都有较大改进,除此之外,速度的提升也是亮点,后面有详细的速度对比。

既然想用1*3*3卷积和3*1*1卷积代替3*3*3卷积,那么怎样组合这两种卷积也是一个问题,Figure2是P3D ResNet网络中residual的三种结构形式。S表示spatial 2D filters,也就是1*3*3卷积;T表示temporal 1D filters,也就是3*1*1卷积。

Figure3是对于P3D ResNet网络中residual的三种结构形式的详细介绍以及和ResNet的residual的对比。P3D ResNet的深度增加主要是P3D-A和P3D-C带来的。

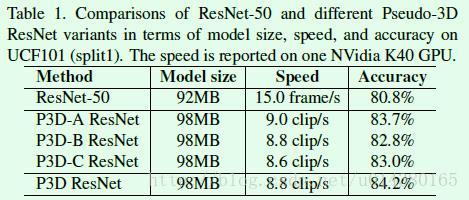
Table1是P3D ResNet的速度和在UCF101数据集上的准确率对比。ResNet-50是在UCF101数据集上fine tune得到的,具体是这样做的:We set the input as 224 × 224 image which is randomly cropped from the resized 240 × 320 video frame. After fine-tuning ResNet-50, the networks will predict one score for each frame and the video-level prediction score is calculated by averaging all frame-level scores.
P3D-A ResNet、P3D-B ResNet、P3D-C ResNet是这样做的:The architectures of three P3D ResNet variants are all initialized with ResNet-50 except for the additional temporal convolutions and are further fine-tuned on UCF101. 换句话说,1*3*3卷积是可以用原来ResNet-50的3*3卷积进行初始化的,但是3*1*1卷积是不行的,因为ResNet-50中没有这样尺寸的卷积核,因此3*1*1卷积是随机初始化然后直接在视频数据集上fine tune。For each P3D ResNet variant, the dimension of input video clip is set as 16 × 160 × 160 which is randomly cropped from the resized non-overlapped 16-frame clip with the size of 16 × 182 × 242. 训练P3D的时候每个batch包含128个clip,每个clip包含16帧(frame)图像,每帧图像的大小是160*160,因此输入就是128*3*16*160*160这样的维度。另外为什么是16帧呢?主要是和网络结构相关,从代码可以看出涉及4个pooling正好能将16降到1。测试的时候是从一个video中抽取20个clip,每个clip由16 frame图像组成,后面会详细介绍。原文关于模型的输入尺寸是这么说的:Given a video clip with the size of c×l×h×w where c, l, h and w denotes the number of channels, clip length, height and width of each frame, respectively. clip length就是这里说的16 frame。
从Table1可以看出在模型大小增加一点的情况下,速度大大提升(9 clip/s就是144 frame/s左右),准确率提升也比较明显。另外 By additionally pursuing structural diversity, P3D ResNet makes the absolute improvement over P3D-A ResNet, P3D-B ResNet and P3D-C ResNet by 0.5%, 1.4% and 1.2% in accuracy respectively, indicating that enhancing structural diversity with going deep could improve the power of neural networks.
最后的P3D ResNet是通过三种变形的交替连接得到,如Figure4所示。

Table2是在Sports-1M数据集上的结果对比,Sports-1M一共包含487个class,视频数量在1.13 million左右。Clip hit@1表示clip的top1分类准确率(clip-level accuracy),Video hit@1表示video的top1分类准确率(video-level accuracy),Video hit@5表示video的top5分类准确率。在Table2中 Deep Video是采用类似AlexNet的网络进行分类的,而Single Frame和Slow Fusion的差别是输入frame的数量,后者相当于是基于10个frame来计算clip和video-level的准确率,所以会高一些。Convolutional Pooling exploits max-pooling over the final convolutional layer of GoogleNet across each clip’s frames,也就是说是对120个frame做max-pooling得到的,所以准确率较高,但显然速度要慢很多。C3D既可以train from scratch,也可以在I380K数据集上预训练,然后在Sports-1M数据集上fine tune得到。ResNet-152 is fine-tuned and employed on one frame from each clip to produce a clip-level score,也就是说clip-level score是由一个frame决定的。另外ResNet-152和Deep Video(Single Frame)的区别只是网络结构不一致而已;P3D ResNet(199层)的速度应该在2clip/s以上,因为文中提到处理每个clip的时间少于0.5s。
总结下Table2(模型测试的时候)是这么得到的:We randomly sample 20 clips from each video and adopt a single center crop per clip, which is propagated through the network to obtain a clip-level prediction score. The video-level score is computed by averaging all the clip-level scores of a video. clip-level accuracy比较容易理解,就是一个clip(包含16 frame)作为训练好的模型的输入,然后在pool5层会得到2048维的输出,最后接一个全连接层得到487维输出(对应Sports-1M的487个类别)。video-level accuracy则是对同一个video的每个clip生成的2048维输出做平均,最后基于平均后得到的2048维特征用channel数为487的全连接层进行连接得到输出。

实验结果:
首先是关于实验用到的5个数据集:
UCF101 and ActivityNet are two of the most popular video action recognition benchmarks.
UCF101 consists of 13,320 videos from 101 action categories. Three training/test splits are provided by the dataset organisers and each split in UCF101 includes about 9.5K training and 3.7K test videos.
The ActivityNet dataset is a large-scale video benchmark for human activity understanding.
The latest released version of the dataset (v1.3) is exploited, which contains 19,994 videos from 200 activity categories. The 19,994 videos are divided into 10,024, 4,926 and 5,044 videos for training, validation and test set, respectively.
ASLAN is a dataset on action similarity labeling task, which is to predict the similarity between videos. The dataset includes 3,697 videos from 432 action categories.
YUPENN and Dynamic Scene are two sets for the scenario of scene recognition. In between, YUPENN is comprised of 14 scene categories each containing 30 videos. Dynamic Scene consists of 13 scene classes with 10 videos per class.
Table3是本文算法和其他算法在UCF101数据集上的对比。这里主要将算法分成三种:End-to-end CNN architecture with fine-tuning、CNN-based representation extractor+linear SVM、Method fusion with IDT。Accuracy列中括号部分的准确率表示输入除了视频帧(video frame)以外,还包含光流信息(optical flow)。这里的P3D ResNet应该是199层的模型。IDT是人工提取的特征。TSN是ECCV2016的算法,算是目前效果比较好的了。只以视频帧为输入的P3D ResNet的效果甚至要好于一些以视频帧和光流为输入的网络的效果,比如引用25、29、37。P3D ResNet和C3D的效果对比可以看出前者的优势还是比较明显。In addition, by performing the recent state-of-the-art encoding method [22] on the activations of res5c layer in P3D ResNet, the accuracy can achieve 90.5%, making the improvement over the global representation from pool5 layer in P3D ResNet by 1.9%. 文中的这句话并没有作为实验结果列在表格中,不知是何原因。

Table3是本文算法和其他算法在ActivityNet数据集上的对比
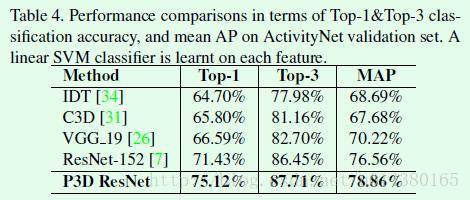
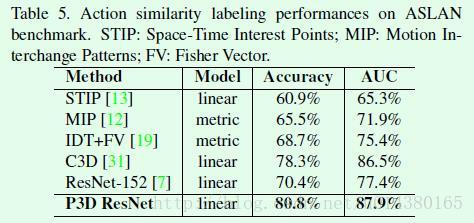
Table5是在ASLAN数据集上的关于action similarity的结果对比,这个数据集是用来判断:does a pair of videos present the same action。
其他更多实验结果可以参看原文。
关于后期优化的三个方向,作者也放出来了,非常值得一试,尤其是第三点,也就是以视频帧和光流信息同时作为模型的输入,毕竟这种做法在其他算法上效果非常明显(Table3的括号)。原文如下:Our future works are as follows. First, attention mechanism will be incorporated into our P3D ResNet for further enhancing representation learning. Second, an elaborated study will be conducted on how the performance of P3D ResNet is affected when increasing the frames in each video clip in the training. Third, we will extend P3D ResNet learning to other types of inputs, e.g., optical flow or audio.