【今日CV 计算机视觉论文速览 第148期】Mon, 29 Jul 2019
今日CS.CV 计算机视觉论文速览
Mon, 29 Jul 2019
Totally 42 papers
?上期速览✈更多精彩请移步主页

Interesting:
?****TOM-Net学习透明物体的抠取, 提出了一种基于折射率流的方法处理图像中透明物体的抠取,将透明物体的抠取问题转换为了折射率流估计问题。模型分为两部分,一部分是多尺度的编码-解码网络用于预测粗糙结果,随后利用残差模型来优化结果,模型的输出为目标的掩膜、透射率图和折射率流。为了训练这一模型,研究人员基于COCO数据集合成了178k的透明物体数据集,同时利用14个透明物体在60个背景下采集了876张真实图像。实验结果表明这种方法可以高效快速的处理透明物体的抠取,同时也可以方便地集成到已有的抠图方法中去。(from 香港大学)
通过预测处理的mask,透射率和折射率图来,可以将目标合成到新的背景中去。
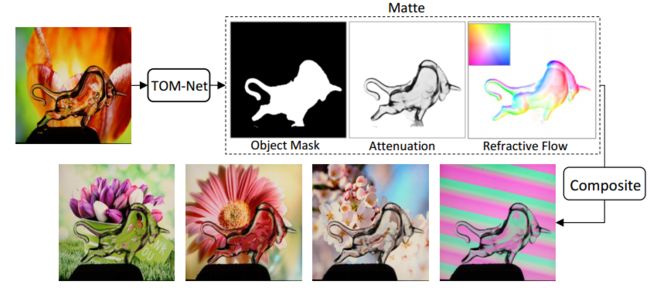
研究人员提出的模型如下,分为两个部分,是典型的自编码器架构:

下面公式描述了透明物体的光线传播公式如下,其中F为前景颜色、B为背景颜色、alpha为不透明度,phi为环境光:

本文将上述公式简化为,m为背景或前景(0/1),ρ为衰减系数,双线性插值操作M(T背景图像,P位置):
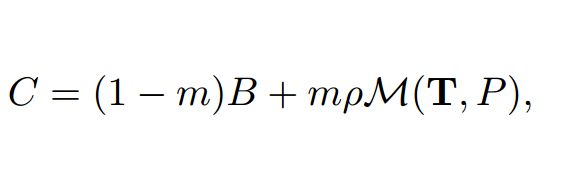
与其他方法的对比:
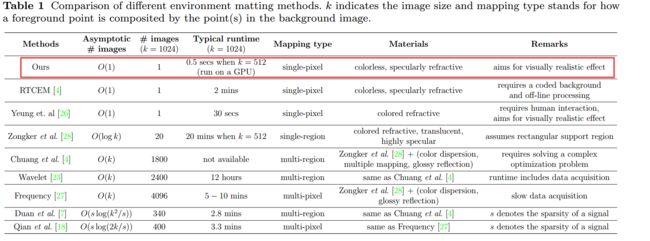
一些真实数据集的结果,包括玻璃、含水的杯子、透镜、复杂玻璃构建等。

一些检测结果和合成结果:

website:http://gychen.org/TOM-Net/
dataset:http://www.visionlab.cs.hku.hk/data/TOM-Net/
?+++UGAN人脸特征迁移模型, 多域之间的图像迁移一般会残留一些原来域中的图像特征,为了除去源域中的特征保留,研究人员提出了UGAN利用新型的辨别分类器来寻找图像的来源域,检测迁移后的图像是否包含源域的特征。随后利用对抗方法来合成目标域的图像,去除残留的源域特征,使得合成图像的源域变得不可追溯。(from 中科院)

在模型的判别器中加入了一项用于判别迁移图像来源的分类器,这一项可以使得生成器生成与源图像特征无光的重建结果,使得图像迁移的结果更为优异。生成器包含三个损失,一个是通常的fake/real损失,一个是基于源标签重建输入源图像的重建损失,一个是用于迷惑源/目标分类器的迁移域残留损失。
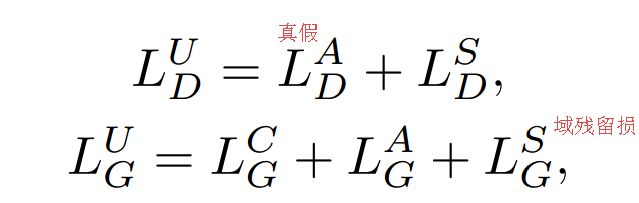
一些结果,分别是不同化妆迁移、年龄迁移和表情迁移:



dataset:Face aging,MAKEUP-A5,CFEE
一个gan的推:https://twitter.com/roadrunning01
?Universal Pooling一种新型的池化方法, 研究人员提出了一种可以生成任意池化方法的函数,可以根据所要处理的任务和数据来进行选择。这种通用的池化方法受到了注意力方法的启发、可以被视为逐通道的局域空间注意力机制。(from 延世大学)
研究人员提出了一种池化权重的概念:
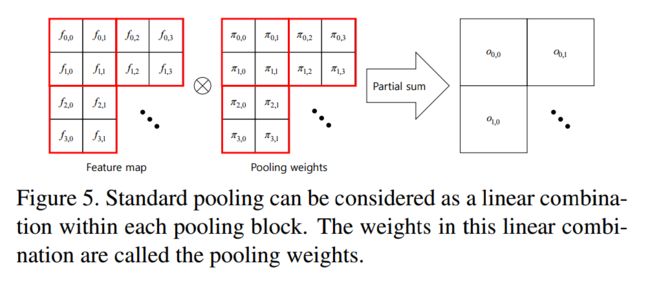
提出的通用池化模块包含了两个部分,分别是池化权重计算模块B2和池化部分B2:
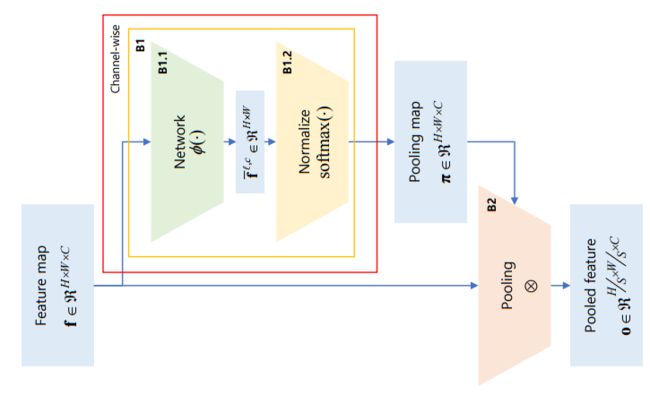
全局和局域池化通过全连接和卷积的实现:
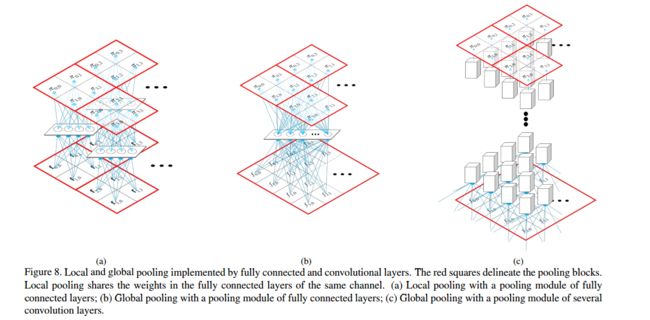
提出的方法取得了比较好的效果:
三个池化权重的例子:



?用于时尚衣着搭配评分的模型, 研究人员提出了一个同时预测和检查时尚搭配的模型,一方面通过不同服饰配件对儿间的大牌来学习各种衣着间的搭配得分、另一方面利用多层CNN来比较不同层级(颜色、纹理、风格)间对于搭配兼容性的考虑。为了训练这一模型,研究人员还提出了一个Polyvore-T的数据集。(from 东华大学)
这一模型不仅可以预测穿搭是否合适,同时通过不同层级进行诊断、给出新的搭配建议:

模型的工作流程如下,首先预测兼容性随后利用反向梯度来进行诊断,给出更好的建议。在特征抽取阶段,利用不同层级的特征图来进行全局池化,构建不同方面的特征表达,随后利用逐对儿物品在不同层级上记性相似度计算获取全局的兼容性得分,其中视觉语义嵌入用于处理多模态的时尚物体信息,通过他们之间相同的表达来进行学习。
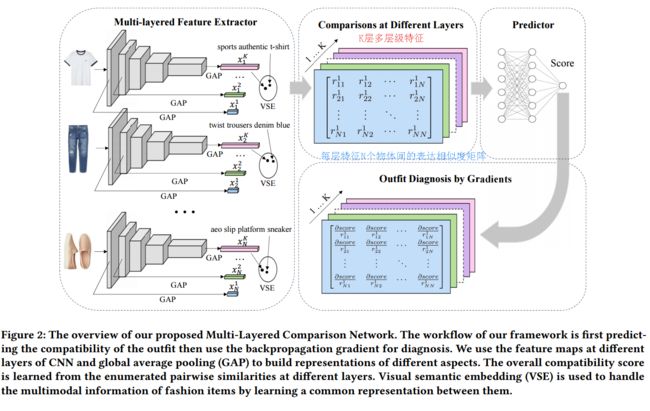
模型可以解决的两种任务,传达检测和传达建议:

相关层的检索结果和一些样本间的兼容性得分、以及给出的穿搭建议:
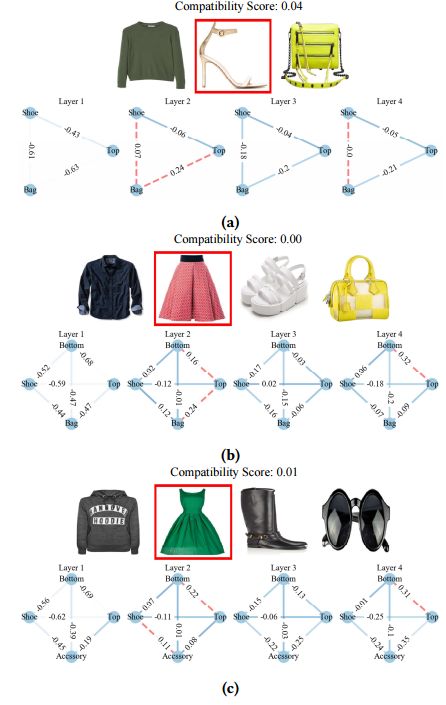


code:https://github.com/WangXin93/fashion_compatibility_mcn
Daily Computer Vision Papers
| On the Design of Black-box Adversarial Examples by Leveraging Gradient-free Optimization and Operator Splitting Method Authors Pu Zhao, Sijia Liu, Pin Yu Chen, Nghia Hoang, Kaidi Xu, Bhavya Kailkhura, Xue Lin 强大的机器学习是目前最突出的主题之一,它可能有助于塑造高级AI平台的未来,这些平台不仅在平均情况下表现良好,而且在最坏情况或不利情况下表现良好。然而,尽管存在长期愿景,但是关于黑盒对抗性攻击的现有研究仍局限于威胁模型的非常特定的设置,例如,单个失真度量和对目标模型对查询的反馈的限制性假设,或者遭受过高的查询复杂性。为了推动该领域的进一步发展,我们引入了一个基于运算符分裂方法的通用框架,乘法器ADMM的交替方向方法设计有效,强大的黑盒攻击,可以处理各种失真度量和反馈设置,而不会产生高查询复杂度。由于威胁模型的黑盒特性,所提出的ADMM解决方案框架与零阶ZO优化和贝叶斯优化BO集成,因此适用于无梯度机制。这导致两种新的黑盒对抗攻击生成方法,ZO ADMM和BO ADMM。我们对图像分类数据集的经验评估表明,与现有技术的攻击方法相比,我们提出的方法具有更低的函数查询复杂度,但实现了极具竞争力的攻击成功率。 |
| ++Differential Scene Flow from Light Field Gradients Authors Sizhuo Ma, Brandon M. Smith, Mohit Gupta 本文基于4D光场的差分分析,提出了恢复三维密集场景流的新技术。关键使能结果是每射线线性方程,称为射线流动方程,其将3D场景流与4D光场梯度相关联。射线流动方程对于三维场景结构是不变的,并且适用于一般类型的场景,但是在每个方程的约束下3个未知数。因此,必须施加额外的约束来恢复运动。我们通过利用相应光流方法启发的射线流和光流方程本地Lucas Kanade射线流和全球Horn Schunck射线流之间的结构相似性来开发两类场景流算法。我们还利用光场中的对应结构开发了一种组合的局部全局方法。我们展示了针对各种场景的高精度3D场景流恢复,包括旋转和非刚性运动。我们通过光场结构张量(一种编码光场局部结构的3×3矩阵)分析了所提出技术的理论和实际性能极限。我们设想所提出的分析和算法将导致设计未来的光场相机,其优化用于运动感测,以及深度感测。 |
| Unsupervised Learning for Optical Flow Estimation Using Pyramid Convolution LSTM Authors Shuosen Guan, Haoxin Li, Wei Shi Zheng 目前大多数基于卷积神经网络CNN的光流估计方法都侧重于利用groundtruth学习合成数据集上的光流,这是不切实际的。在本文中,我们提出了一种名为PCLNet的无监督光流估计框架。它使用金字塔卷积LSTM ConvLSTM,具有相邻帧重建的约束,允许灵活地估计来自任何视频剪辑的多帧光流。此外,通过解耦运动特征学习和光流表示,我们的方法避免了现有框架中使用的复杂短切连接,同时提高了光流估计的准确性。此外,与使用专用CNN架构捕获运动的那些方法不同,我们的框架直接从通用CNN的特征中学习光流,因此可以容易地嵌入任何基于CNN的框架中以用于其他任务。大量实验证明,我们的方法不仅可以有效,准确地估算光流,而且可以获得与动作识别相当的性能。 |
| Cooperative image captioning Authors Gilad Vered, Gal Oren, Yuval Atzmon, Gal Chechik 使用自然语言描述图像时,如果使用下游任务进行调整,则可以使描述更具信息性。这通常通过训练两个网络,即生成给定图像的句子的扬声器网络,以及使用它们执行任务的监听网络来实现。遗憾的是,联合培训多个网络进行沟通以实现联合任务,面临两大挑战。首先,由扬声器网络生成的描述是离散的和随机的,使得优化非常困难和低效。其次,联合训练通常会使通讯过程中使用的词汇偏离自然语言。 |
| +Deep Learning for Classification and Severity Estimation of Coffee Leaf Biotic Stress Authors J. G. M. Esgario, R. A. Krohling, J. A. Ventura 生物胁迫包括通过其他生物体对植物的破坏。有效控制生物制剂如害虫和病原体病毒,真菌,细菌等与农业可持续性的概念密切相关。农业可持续性促进了新技术的开发,这些技术可以减少对环境的影响,提高农民的可及性,从而提高生产率。通过深度学习方法使用计算机视觉可以及早正确地识别引起压力的药剂。因此,可以尽快采取纠正措施来缓解问题。这项工作的目的是设计一个有效和实用的系统,能够识别和估计咖啡叶上的生物制剂引起的压力严重程度。所提出的方法包括基于卷积神经网络的多任务系统。此外,我们还探索了使用数据增强技术来使系统更加健壮和准确。获得的用于分类和严重性评估的实验结果表明,所提出的系统可能是帮助专家和农民识别和量化咖啡种植园中的生物胁迫的合适工具。 |
| ++++Learning Transparent Object Matting Authors Guanying Chen, Kai Han, Kwan Yee K. Wong 本文讨论了透明物体的图像消光问题。现有方法通常需要繁琐的捕获程序和长的处理时间,这限制了它们的实际使用。在本文中,我们将透明物体消光作为折射流估计问题,并提出一个深度学习框架,称为TOM Net,用于学习折射流。我们的框架包括两部分,即用于产生粗略预测的多尺度编码器解码器网络和用于细化的剩余网络。在测试时,TOM Net将单个图像作为输入,并在快速前馈传递中输出由对象掩模,衰减掩模和折射流场组成的遮罩。由于没有现成的数据集可用于透明对象遮罩,我们创建了一个大规模的合成数据集,其中包含从Microsoft COCO数据集中采样的图像前呈现的178K透明对象图像。我们还使用14个透明对象和60个背景图像捕获由876个样本组成的真实数据集。此外,我们展示了我们的方法可以很容易地扩展到处理trimap或背景图像可用的情况。已经在合成和实际数据上实现了实验结果,这清楚地证明了我们的方法的有效性。 |
| ++去畸变方法Minimal Solvers for Rectifying from Radially-Distorted Scales and Change of Scales Authors James Pritts, Zuzana Kukelova, Viktor Larsson, Yaroslava Lochman, Ond ej Chum 本文介绍了从刚性变换的共面特征图像中联合估计透镜畸变和仿射校正的第一个最小解算器。求解器在没有直线的场景上工作,并且通常放松对现有技术所做出的场景内容的强烈假设。拟议的求解器使用仿射不变量,共面重复在整流空间中具有相同的比例。求解器被分成两组,这两组不同之处在于如何使用整流空间的等比例不变来对透镜失真和整流参数施加约束。我们展示了一种通过Gr bner基方法生成稳定最小求解器的原理方法,该方法通过对可行的单项式基数进行采样以最大化数值稳定性来实现。合成和实际图像实验证实,与现有技术相比,所提出的解算器表现出优异的噪声鲁棒性。使用窄到鱼眼视场镜头拍摄的图像的精确校正表明了所提出方法的广泛适用性。该方法是完全自动的。 |
| +视觉提升竞赛Report on UG^2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms Authors Sreya Banerjee, Rosaura G. VidalMata, Zhangyang Wang, Walter J. Scheirer 我们如何有效地设计能够解释来自无人机等无约束移动平台的视频的计算机视觉系统一个有前景的选择是利用计算摄影领域的图像恢复和增强算法来提高底层帧的质量。这种方式也可以改善自动视觉识别。沿着这些方向,需要探索性的工作来找出哪些图像预处理算法结合最强大的特征和监督机器学习方法,是运动模糊,天气和错误聚焦等困难场景的良好候选者。图片。本文总结了与IEEE CVF CVPR 2019一起举行的UG 2挑战赛第一场的协议和结果。该挑战着眼于两个独立的问题:1视频中的物体检测改进,以及视频中的2个物体分类改进。挑战使用了UG 2无人机,滑翔机,地面数据集,这是评估图像恢复和增强与视觉识别之间相互作用的既定基准。学术和企业团队提交了16种算法,并在此报告了他们如何对每个挑战问题进行详细分析。 |
| Context-Aware Multipath Networks Authors Dumindu Tissera, Kumara Kahatapitiya, Rukshan Wijesinghe, Subha Fernando, Ranga Rodrigo 使单个网络有效地处理不同的上下文,了解数据集或多个数据集中的变化是实现广义智能的有趣步骤。加深,扩展和组装网络的现有方法通常不具有成本效益。鉴于此,可以根据输入的上下文分配资源并调节网络上的信息流的网络是有效的。在本文中,我们提出了Context Aware Multipath Network CAMNet,这是一种多路径神经网络,在并行张量之间具有数据相关路由。我们展示了我们的模型作为一个通用模型执行,捕获单个数据集和多个不同数据集的变化,同时和顺序。与等效的单路径,多路径和更深的单路径网络相比,CAMNet超越了分类和像素标记任务的性能,单独,顺序和组合地考虑数据集。 CAMNet中的张量之间的数据相关路由使模型能够端到端地控制信息流,决定哪些资源是共同的或特定于域的。 |
| ++基于CNN估计离散余弦变换的系数DCT-CompCNN: A Novel Image Classification Network Using JPEG Compressed DCT Coefficients Authors Bulla Rajesh, Mohammed Javed, Ratnesh, Shubham Srivastava 卷积神经网络CNN在图像处理和计算机视觉领域的普及促使全球的研究人员和实业家专家以高精度解决不同的挑战。训练CNN分类器的最简单方法是直接将原始RGB像素图像馈送到网络中。但是,如果我们打算使用压缩数据直接对图像进行分类,则相同的方法可能无法更好地工作,例如JPEG压缩图像。本研究报告研究了修改JPEG压缩数据的输入表示,然后输入CNN的问题。该架构称为DCT CompCNN。这种新颖的方法已经表明CNN还可以用JPEG压缩DCT系数训练,并且随后与传统CNN方法相比可以产生更好的性能。使用现有的ResNet 50架构和在Dog Vs Cat和CIFAR 10数据集等公共图像分类数据集上提出的DCT CompCNN架构测试修改后的输入表示的效率,报告更好的性能 |
| +++穿衣搭配模型Outfit Compatibility Prediction and Diagnosis with Multi-Layered Comparison Network Authors Xin Wang, Bo Wu, Yun Ye, Yueqi Zhong 关于时尚服装兼容性的现有作品侧重于预测一组时尚物品与来自不同形态的信息的整体兼容性。然而,很少有工作探索如何解释预测,这限制了模型的说服力和有效性。在这项工作中,我们提出了一种方法,不仅可以预测,还可以诊断装备兼容性。我们为此目标引入了端到端框架,其特征为1,从项目之间的所有类型指定的成对相似性中学习总体兼容性,并且反向传播梯度用于诊断不兼容的因素。 2我们利用CNN的层次结构并比较不同层次的特征,以考虑从低级别(如颜色,纹理)到高级别(如样式)等不同方面的兼容性。为了支持所提出的方法,我们基于Polyvore数据集构建了一个名为Polyvore T的新类型指定装备数据集。我们将我们的方法与现有技术在两个任务装备兼容性预测中进行比较并填写空白。实验表明,我们的方法在预测性能和诊断能力方面都具有优势。 |
| Multi-level Domain Adaptive learning for Cross-Domain Detection Authors Rongchang Xie, Fei Yu, Jiachao Wang, Yizhou Wang, Li Zhang 近年来,使用有监督的深度学习,对象检测已经显示出令人印象深刻的结果,但在跨域环境中仍然具有挑战性。不同领域的光照,样式,比例和外观的变化会严重影响检测模型的性能。以前的工作使用对抗性训练来对齐域移位中的全局特征并实现图像信息传输。然而,这些方法不能有效地匹配局部特征的分布,导致跨域对象检测的有限改进。为了解决这个问题,我们提出了一种多级域自适应模型,以同时对齐局部级特征和全局级特征的分布。我们通过多个实验评估我们的方法,包括恶劣天气适应,合成数据适应和交叉相机适应。在大多数对象类别中,所提出的方法实现了针对现有技术的优越性能,这证明了我们的方法的有效性和稳健性。 |
| Single Level Feature-to-Feature Forecasting with Deformable Convolutions Authors Josip ari , Marin Or i , Ton i Antunovi , Sacha Vra i , Sini a egvi 未来的预期对于自动驾驶和其他决策系统至关重要。我们提出了一种基于特征预测的预测驾驶场景中未来帧的语义分割的方法。我们的方法基于语义分段模型,在上采样路径内没有横向连接。这种设计可确保预测仅针对非常粗略的分辨率处理最抽象的特征。我们进一步建议用可变形卷积表示特征预测的特征。由于能够在单个特征图中表示不同的运动模式,这增加了建模能力。实验表明,我们的可变形卷曲模型优于常规和扩张的模型,同时最小化参数数量。我们的方法在预测未来9个步骤时,可以在Cityscapes验证集上实现最先进的性能。 |
| +++轻量级场景解译模型Context-Integrated and Feature-Refined Network for Lightweight Urban Scene Parsing Authors Bin Jiang, Wenxuan Tu, Chao Yang, Junsong Yuan 用于轻量级城市场景解析的语义分割是非常具有挑战性的任务,因为准确性和效率(例如,执行速度,存储器占用空间和计算复杂度)都应该被考虑在内。然而,大多数以前的作品过于注重单方面的观点,无论是准确性还是速度,而忽视其他观点,这对智能设备的实际需求造成很大的限制。为了解决这个难题,我们提出了一个名为Context Integrated和Feature Refined Network CIFReNet的新轻量级架构。我们架构的核心组件是Long skip Refinement Module LRM和Multi scale Contexts Integration Module MCIM。 LRM具有较低的额外计算成本,旨在简化空间信息的传播并提高特征细化的质量。同时,MCIM由三个具有全局约束的级联密集语义金字塔DSP块组成。它充分利用了靠近目标的子区域,并以经济而强大的方式扩大了视野。综合实验表明,我们提出的方法在Cityscapes和Camvid数据集的整体属性之间达成了合理的权衡。具体来说,只有7.1 GFLOP,包含少于1.9 M参数的CIFReNet在Cityscapes测试集上获得70.9 MIoU的竞争结果,在Camvid测试集上获得64.5,实时速度为32.3 FPS,这比其他状态更具成本效益艺术方法。 |
| Multiple Human Association between Top and Horizontal Views by Matching Subjects' Spatial Distributions Authors Ruize Han, Yujun Zhang, Wei Feng, Chenxing Gong, Xiaoyu Zhang, Jiewen Zhao, Liang Wan, Song Wang 通过使用顶视图数据(例如来自空中无人机安装的摄像机的数据)和水平视图数据(例如来自地面上的可穿戴摄像机的数据),可以显着增强视频监视。不同视图数据的协同分析可以促进各种应用,例如人类跟踪,人员识别和人类活动识别。然而,对于这种协作分析,第一步是将这些被称为本文主题的人与这两种观点联系起来。由于顶视图和水平视图之间的人类外观差异很大,这是一个非常具有挑战性的问题在本文中,我们提出了一种通过探索和匹配两个视图之间的主题空间分布来解决这个问题的新方法。更具体地,在顶视图图像上,我们在两个视图中对主体相对位置建模并匹配水平视图相机,并定义匹配成本以确定水平视图相机的实际位置及其在顶视图图像中的视角。我们收集了一个由顶视图和水平视图图像对组成的新数据集,用于性能评估,实验结果表明了该方法的有效性。 |
| Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video Authors Isabel Funke, Sebastian Bodenstedt, Florian Oehme, Felix von Bechtolsheim, J rgen Weitz, Stefanie Speidel 自动识别手术手势是彻底了解手术技巧的关键一步。可能的应用领域包括自动技能评估,关键手术步骤的术中监测和手术任务的半自动化。仅依赖于腹腔镜视频并且不需要额外的传感器硬件的解决方案特别有吸引力,因为它们可以在许多情况下以低成本实现。然而,仅基于视频的手术手势识别是一个具有挑战性的问题,其需要有效的手段来从视频中提取视觉和时间信息。以前的方法主要依赖于框架式特征提取器,无论是手工制作还是学习,都无法捕捉手术视频中的动态。为了解决这个问题,我们建议使用3D卷积神经网络CNN来学习连续视频帧的时空特征。我们评估了我们在台式模型上记录机器人辅助缝合的方法,这些模型取自公开的JIGSAWS数据集。我们的方法实现了超过84的高框架智能手术手势识别精度,优于仅提取空间特征或分别模拟空间和低级时间信息的可比较模型。这些结果首次证明了时空CNN对基于视频的手术手势识别的益处。 |
| ++++新型池化方法Universal Pooling -- A New Pooling Method for Convolutional Neural Networks Authors Junhyuk Hyun, Hongje Seong, Euntai Kim 汇聚是卷积神经网络的主要元素之一。池化减少了要素图的大小,使用有限的计算量进行训练和测试。本文提出了一种名为通用池的新池方法。与现有的池方法(如平均池,最大池和具有固定池功能的跨步池)不同,通用池会根据给定的问题和数据集生成任何池功能。普遍汇集的灵感来自注意方法,可以被视为当地空间关注的渠道明智形式。通用池与主网络共同训练,并显示它包括现有的池化方法。最后,当应用于两个基准问题时,所提出的方法优于现有的池化方法,并且以预期的多样性执行,适应给定的问题。 |
| ++红外特征与RGB特征的迁移Semantic Deep Intermodal Feature Transfer: Transferring Feature Descriptors Between Imaging Modalities Authors Sebastian P. Kleinschmidt, Bernardo Wagner 在恶劣的环境条件下,RGB相机的视野可能受到雾,灰尘或困难照明情况的限制。由于热像仪可视化热辐射,因此它们不受RGB相机的限制。然而,因为RGB和热成像在外观上显着不同,所以普通的现有技术特征描述符不适合于这些成像模态之间的联合特征匹配。因此,使用RGB相机创建的可视地图目前不能用于使用热像仪进行定位。在本文中,我们介绍了语义深层多模特征转移Se DIFT,一种将图像特征描述符从视觉转移到热谱的方法,反之亦然。为此,我们使用深度卷积编码器解码器架构结合全局特征向量来预测在不同成像模态下的潜在特征外观。由于热图像的表示不仅受到可从RGB图像提取的特征的影响,因此我们引入了增强自动编码器编码的全局特征向量。全局特征向量包含有关从外部数据源自动提取的场景的热历史的附加信息。通过增加编码器的编码,与传统U Net架构的预测相比,我们将预测的L1误差减少了7倍以上。为了评估我们的方法,我们使用Se DIFT匹配在RGB和热图像中检测到的图像特征描述符。随后,我们使用我们的方法对SIFT,SURF和ORB特征的多式联运可转移性进行了竞争性比较。 RGB+红外设备:FLIR One Pro camera |
| LinearConv: Regenerating Redundancy in Convolution Filters as Linear Combinations for Parameter Reduction Authors Kumara Kahatapitiya, Ranga Rodrigo 卷积神经网络CNN显示计算机视觉任务中的最新性能。然而,已知CNN的卷积层学习冗余特征,仍然不能有效地满足存储器需求。在这项工作中,我们以卷积滤波器之间的相关性的形式探索学习特征的冗余,并提出一个新的层来有效地再现它。所提出的LinearConv层生成一部分卷积滤波器作为其余滤波器的可学习线性组合,并引入基于相关的正则化,以实现灵活性和对滤波器之间的相关性以及参数数量的控制。这被开发为插入层,以方便地替换传统的卷积层,而无需网络架构中的任何修改。我们的实验验证了基于LinearConv的模型能够达到与同类参数相同的性能,参数减少高达50,并且在运行时具有相同的计算要求。 |
| +++多域人脸迁移UGAN: Untraceable GAN for Multi-Domain Face Translation Authors Defa Zhu, Si Liu, Wentao Jiang, Chen Gao, Tianyi Wu, Guodong Guo 多域图像到图像转换在计算机视觉社区中受到越来越多的关注。但是,翻译的图像通常保留源域的特征。在本文中,我们提出了一种新型的Untraceable GAN UGAN来解决源保持现象。具体地,UGAN的鉴别器包含新颖的源分类器以告知从哪个域翻译图像,目的是确定翻译的图像是否仍然保留源域的特征。在此对抗训练收敛之后,翻译器能够合成仅目标特征并且还擦除仅源特征。以这种方式,合成图像的源域变得难以追踪。我们进行了大量的实验,结果表明,所提出的UGAN可以在三个面部编辑任务(包括面部老化,化妆和表情编辑)上比最先进的StarGAN产生更好的效果。源代码将公开发布。 |
| Improving Generalization via Attribute Selection on Out-of-the-box Data Authors Xiaofeng Xu, Ivor W. Tsang, Chuancai Liu 零射击学习ZSL旨在通过共享不同对象之间的属性信息来识别看不见的对象测试类,给出一些其他看到的对象训练类。属性是对象的人工注释,在最近的ZSL任务中被平等对待。然而,一些具有较差可预测性或较差可辨性的较差属性可能对ZSL系统性能产生负面影响。本文首先推导出ZSL任务的泛化误差限制。我们的理论分析验证了选择关键属性集可以提高使用所有属性的原始ZSL模型的泛化性能。遗憾的是,先前的属性选择方法是基于所看到的数据进行的,它们所选择的属性对于看不见的数据具有较差的泛化能力,这在ZSL任务的训练阶段是不可用的。通过学习伪相关反馈的启发,本文介绍了开箱即用的数据,即由属性引导生成模型生成的伪数据,以模仿看不见的数据。之后,我们提出了迭代属性选择IAS策略,该策略基于开箱即用的数据迭代地选择关键属性。由于生成的开箱即用数据的分布类似于测试数据,因此IAS选择的关键属性可以有效地推广到测试数据。大量实验表明,IAS可以显着改善现有的基于属性的ZSL方法,并实现最先进的性能。 |
| A Comparative Study of High-Recall Real-Time Semantic Segmentation Based on Swift Factorized Network Authors Kaite Xiang, Kaiwei Wang, Kailun Yang 语义分割SS是为观察图像的每个像素分配语义标签的任务,这对于自动车辆,视障人士的导航辅助系统和增强现实设备具有至关重要的意义。然而,SS仍然有很长的路要走,因为在实际应用中需要解决效率和评估标准这两个基本挑战。对于特定的应用场景,需要采用不同的标准。召回率是自动驾驶车辆等许多任务的重要标准。对于自动驾驶汽车,我们需要专注于检测交通对象,如汽车,公共汽车和行人,这些应该以高召回率检测到。换句话说,最好是错误地检测它而不是错过它,因为如果算法错过它们并将它们分割为安全的道路,其他交通对象将是危险的。在本文中,我们的主要目标是探索获得高召回率的可能方法。首先,我们提出了一个名为Swift Factorized Network SFN的实时SS网络。所提出的网络改编自SwiftNet,其结构是具有横向连接的典型U形结构。受ERFNet和全球卷积网络GCNet的启发,我们提出了两个不同的块来扩大有效的感受野。它们不占用太多的计算资源,但与基线网络相比显着提高了性能。其次,我们探索了三种实现更高召回率的方法,即损失函数,分类器和决策规则。我们对包括CamVid和Cityscapes在内的最先进数据集进行了一系列全面的实验。我们证明了我们的SS卷积神经网络达到了优异的性能。此外,我们对提出召回率的三种方法进行了详细的分析和比较。 |
| Product Image Recognition with Guidance Learning and Noisy Supervision Authors Qing Li, Xiaojiang Peng, Liangliang Cao, Wenbin Du, Hao Xing, Yu Qiao 本文考虑从日常照片中识别产品,这是现实世界应用中的一个重要问题,但由于背景杂乱,类别多样性,噪声标签等也具有挑战性。我们通过两个贡献来解决这个问题。首先,我们介绍一种新的大规模产品图像数据集,称为产品90.我们利用网络和下载来自几个电子商务网站的评论图像,而不是通过人工和时间密集的图像捕获来收集产品图像。随便被消费者捕获。标签由电子商务网站的类别自动分配。产品90总共包含140多个图像,包含90个类别。由于消费者可能上传不相关的图像,因此我们的产品90不可避免地会引入嘈杂的标签。作为第二个贡献,我们开发了一种简单而有效的文本指导学习GL方法,用于训练卷积神经网络CNN,具有嘈杂的监督。 GL方法首先使用完整的噪声数据集训练初始教师网络,然后以多任务方式训练具有大规模噪声集和小手动验证的清洁集的目标学生网络。具体地,在学生网络训练阶段,大规模噪声数据由其指导知识监督,该指导知识是其给定的噪声标签和来自教师网络的软化标签的组合。我们对我们的产品90和公共数据集进行了大量实验,即Food101,Food 101N和Clothing1M。我们的指导学习方法在这些数据集上实现了优于现有技术方法的性能。 |
| Unsupervised Learning Framework of Interest Point Via Properties Optimization Authors Pei Yan, Yihua Tan, Yuan Xiao, Yuan Tai, Cai Wen 本文通过联合学习探测器和描述符,提出了一个完全无监督的兴趣点训练框架,它以图像为输入,输出每个图像点的概率和描述。训练框架的目标被公式化为提取点的属性的联合概率分布。选择基本属性作为由概率表示的稀疏性,可重复性和可辨性。为了有效地最大化目标,引入潜变量来表示点满足所需属性的概率。因此,可以使用期望最大化算法EM来优化原始最大化。考虑到大规模图像集上EM的高计算成本,我们采用EM MBEM的微批量近似的有效策略实现优化过程。在实验中,检测器和描述符都用完全卷积网络实例化,称为属性网络PN。实验证明PN在许多图像匹配基准上优于现有技术方法而无需再训练。 PN还表明,拟议的培训框架具有很高的灵活性,可以适应不同类型的场景。 |
| A Fully-Convolutional Neural Network for Background Subtraction of Unseen Videos Authors M. Ozan Tezcan, Janusz Konrad, Prakash Ishwar 背景减法是计算机视觉和视频处理中的基本任务,通常用作对象跟踪,人物识别等的预处理步骤。最近,已经提出了许多成功的背景减法算法,但几乎所有表现最好的算法都是监督。至关重要的是,他们的成功依赖于在训练期间测试视频的一些注释帧的可用性。因此,他们在完全看不见的视频上的表现在文献中没有记载。在这项工作中,我们提出了一种新的,有监督的背景减法算法,用于基于完全卷积神经网络的看不见的视频BSUV Net。我们网络的输入包括当前帧和在不同时间尺度捕获的两个背景帧及其语义分割图。为了减少过度拟合的可能性,我们还引入了一种新的数据增强技术,可以减轻背景帧和当前帧之间照度差异的影响。在CDNet 2014数据集中,BSUV Net在F测量,召回和精确度指标方面优于在看不见的视频上评估的最先进算法。 |
| ++行李箱重识别数据集MVB: A Large-Scale Dataset for Baggage Re-Identification and Merged Siamese Networks Authors Zhulin Zhang, Dong Li, Jinhua Wu, Yunda Sun, Li Zhang 在本文中,我们提出了一个名为MVB多视图行李的新型数据集,用于行李ReID任务,与人ReID有一些本质区别。 MVB的功能有三个方面。首先,MVB是第一个公开发布的大型数据集,包含4519个行李标识和22660个带注释的行李图像以及表面材料标签。其次,所有行李图像均由专门设计的多视图摄像系统捕获,以处理姿势变化和遮挡,以尽可能完整地获取行李表面的3D信息。第三,MVB具有显着的类间相似性和类内差异性,考虑到行李可能具有非常相似的外观,而数据是在两个真实的机场环境中收集的,其中成像因子彼此显着不同。此外,我们提出合并的连体网络作为基线模型并评估其性能。在MVB上进行实验和案例研究。 website:http://volumenet.cn/#/ |
| DABNet: Depth-wise Asymmetric Bottleneck for Real-time Semantic Segmentation Authors Gen Li, Inyoung Yun, Jonghyun Kim, Joongkyu Kim 作为像素级预测任务,语义分割需要大的计算成本和巨大的参数以获得高性能。最近,由于对自治系统和机器人的需求不断增加,在准确度和推理速度之间进行权衡是很重要的。在本文中,我们提出了一种新的深度非对称瓶颈DAB模块来解决这一难题,它有效地采用深度不对称卷积和扩张卷积来构建瓶颈结构。基于DAB模块,我们设计了一个深度明智的非对称瓶颈网络DABNet,特别是用于实时语义分割,它创建了足够的感知域并密集地利用了上下文信息。 Cityscapes和CamVid数据集上的实验表明,所提出的DABNet实现了速度和精度之间的平衡。具体来说,在没有任何预训练模型和后处理的情况下,它在Cityscapes测试数据集上实现了70.1平均IoU,在单个GTX 1080Ti卡上只有76万个参数和104 FPS的速度。 |
| Place Clustering-based Feature Recombination for Visual Place Recognition Authors Qiang Zhai, Hong Cheng, Rui Huang, Huiqin Zhan 视觉位置识别是计算机视觉和机器人技术中的一个重要问题,自然场景中遮挡和视点变化引起的图像内容变化仍然对识别位置构成挑战。本文针对这一问题,提出了基于场聚类的新特征重组。首先,基于直方图特征提取称为金字塔主相位特征三PF的一般金字塔扩展方案。为了最大化新特征的作用,我们通过将具有特定阈值的图像聚类为一个位置来评估相似性。已经进行了广泛的实验以验证所提出的方法的有效性,并且结果表明我们的方法可以在两个标准位置识别基准上实现比现有技术更好的性能。 |
| ++多人知识估计Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image Authors Gyeongsik Moon, Ju Yong Chang, Kyoung Mu Lee 尽管在3D人体姿势估计中已经实现了显着的改进,但是大多数先前的方法仅考虑单个人的情况。在这项工作中,我们首先提出了一种基于完全学习的摄像机距离感知自顶向下方法,用于从单个RGB图像进行3D多人姿势估计。所提出的系统的流水线包括人体检测,绝对3D人体根部定位和根相对3D单人姿势估计模型。我们的系统与没有任何地面信息的最先进的3D单人姿势估计模型实现了可比较的结果,并且在公开可用的数据集上明显优于先前的3D多人姿势估计方法。该代码可在脚注网址中找到:https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE |
| NoduleNet: Decoupled False Positive Reductionfor Pulmonary Nodule Detection and Segmentation Authors Hao Tang, Chupeng Zhang, Xiaohui Xie 肺结节检测,假阳性减少和分割代表了胸部CT图像计算机分析中最常见的三项任务。已经提出了针对每个任务的方法,其中基于深度学习的方法最近非常受青睐。然而,训练深度学习模型以分别解决每个任务可能是次优资源密集型并且没有特征共享的益处。在这里,我们提出了一种新的端到端3D深度卷积神经网络DCNN,称为NoduleNet,以多任务方式联合解决结节检测,误报减少和结节分割。为了避免不同任务之间的摩擦并鼓励功能多样化,我们结合了两个主要的设计技巧1用于结节检测和误报减少的解耦特征图,以及2个用于提高结节分割精度的分割细化子网。对大规模LIDC数据集的大量实验表明,与仅解决结核检测任务的基线模型相比,多任务训练非常有益,结节检测精度提高了10.27。我们还进行了系统的消融研究,以突出每个附加组件的贡献。代码可在 |
| SceneGraphNet: Neural Message Passing for 3D Indoor Scene Augmentation Authors Yang Zhou, Zachary While, Evangelos Kalogerakis 在本文中,我们提出了一种神经消息传递方法,用新的对象匹配其周围环境来增强输入3D室内场景。给定输入,可能不完整的3D场景和查询位置,我们的方法预测适合该位置的对象类型的概率分布。我们通过在密集图中传递学习消息来预测我们的分布,其中节点表示输入场景中的对象,并且边表示空间和结构关系。通过注意机制对消息进行加权,我们的方法学会专注于最相关的周围场景上下文来预测新的场景对象。我们发现,根据我们在SUNCG数据集中的实验,我们的方法在正确预测场景中缺失的对象方面明显优于最先进的方法。我们还演示了我们方法的其他应用,包括基于上下文的3D对象识别和迭代场景生成。 |
| A Novel Approach for Robust Multi Human Action Detection and Recognition based on 3-Dimentional Convolutional Neural Networks Authors Noor Almaadeed, Omar Elharrouss, Somaya Al Maadeed, Ahmed Bouridane, Azeddine Beghdadi 近年来,已经提出了各种尝试来探索使用卷积神经网络CNN来使用空间和时间信息进行人类动作识别。但是,只有少数方法可用于识别同一监视视频中由多个人执行的许多人类行为。本文提出了一种基于3Dimdenisional深度学习的新架构应用于视频监控系统的多人类动作识别技术。模型的第一阶段通过提取场景中每个人的序列来使用数据的新表示。还提出了对每个序列的分析以检测相应的动作。 KTH,Weizmann和UCF ARG数据集用于训练,还构建了新的数据集,其包括具有多个动作的许多人用于测试所提出的算法。这项工作的结果表明,所提出的方法提供了更准确的多人动作识别实现98。其他视频用于评估,包括数据集UCF101,Hollywood2,HDMB51和YouTube,无需任何预处理,所得结果表明,与现有技术方法相比,我们提出的方法明显改善了性能。 |
| +Multi-Stage Prediction Networks for Data Harmonization Authors Stefano B. Blumberg, Marco Palombo, Can Son Khoo, Chantal M. W. Tax, Ryutaro Tanno, Daniel C. Alexander 在本文中,我们将多任务学习MTL引入数据协调DH,我们的目标是协调不同采集平台和站点的图像。这使我们能够整合来自多次采集的信息,并提高协调模型的预测性能和学习效率。具体来说,我们介绍了多阶段预测MSP网络,这是一个MTL框架,它将可能完全不同的架构的神经网络,针对不同的个人采集平台进行了培训,融入了一个更加完美的架构。 MSP利用单个网络的高级特征来完成单个任务,作为附加神经网络的输入以通知最终预测,因此利用任务之间的冗余来充分利用有限的训练数据。我们在dMRI协调挑战数据集上验证我们的方法,我们预测三种现代平台类型,从旧扫描仪获得。我们展示了MTL架构(例如MSP)如何在当前最先进的方法上产生大约20个基于补丁的均方误差的改进,并且我们的MSP优于现成的MTL网络。我们的代码可用:https://github.com/sbb-gh/ http://mig.cs.ucl.ac.uk/ 数据调谐:https://datorama.com/blog/2017/04/14/data-101-what-is-data-harmonization/ |
| ++前列腺语义分割Self-Adaptive 2D-3D Ensemble of Fully Convolutional Networks for Medical Image Segmentation Authors Maria G. Baldeon Calisto, Susana K. Lai Yuen 分割是医学图像分析中的关键步骤。完全卷积网络FCN已成为功能强大的分割模型,可在各种医学图像数据集中实现最先进的结果。网络架构通常是针对特定分段任务手动设计的,因此将其应用于其他医疗数据集需要大量的经验和时间。此外,分段需要处理大容量数据,从而产生大而复杂的架构。最近,已经提出了自动设计用于医学图像分割的神经网络的方法,然而,大多数方法要么不完全考虑体积信息,要么不优化网络的大小。在本文中,我们提出了一种用于医学图像分割的新型FCN自适应2D 3D集合,其结合了体积信息并优化了模型的性能和尺寸。该模型由提取片内信息的2D FCN的集合和利用片间信息的3D FCN组成。 2D和3D FCN的体系结构使用基于多目标进化的算法自动适应医学图像数据集,该算法最小化分割误差和网络中的参数数量。所提出的2D 3D FCN集合在来自PROMISE12 Grand Challenge的图像数据集上的前列腺分割任务上进行了测试。由此产生的网络在前10个提交中排名,超过了其他自动设计架构的性能,同时尺寸相当小。 |
| Bayesian Volumetric Autoregressive generative models for better semisupervised learning Authors Guilherme Pombo, Robert Gray, Tom Varsavsky, John Ashburner, Parashkev Nachev 深度生成模型正迅速在医学成像中获得关注。尽管如此,大多数生成体系结构都难以捕获体积数据的潜在概率分布,表现出收敛问题,并且没有提供模型不确定性的稳健指数。相比之下,自回归生成模型PixelCNN可以相对容易地扩展到体积数据,它很容易尝试学习真正的潜在概率分布,它仍然承认贝叶斯重构,为模型不确定性的推理提供了一个原则框架。我们在本文中的贡献首先是两个,我们扩展PixelCNN以使用体积脑磁共振成像数据。其次,我们证明重新拟合该模型以近似深度高斯过程产生了一种不确定性的度量,其改善了半监督学习的性能,特别是在标记数据的比例低的设置中的分类性能。我们对包括T1加权和扩散加权序列的临床磁共振脑成像数据的分类,回归和语义分割任务,训练和测试进行量化。 |
| +情绪压力文化影响识别AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition Authors Fabien Ringeval, Bj rn Schuller, Michel Valstar, NIcholas Cummins, Roddy Cowie, Leili Tavabi, Maximilian Schmitt, Sina Alisamir, Shahin Amiriparian, Eva Maria Messner, Siyang Song, Shuo Liu, Ziping Zhao, Adria Mallol Ragolta, Zhao Ren, Mohammad Soleymani, Maja Pantic 音视频情感挑战和研讨会AVEC 2019心态,人工智能检测抑郁症和跨文化情感识别是第九届竞赛活动,旨在比较多媒体处理和机器学习方法,以进行自动视听健康和情感分析,与所有参与者在相同条件下严格竞争。挑战的目标是为多模态信息处理提供一个共同的基准测试集,并将健康和情感识别社区以及视听处理社区聚集在一起,以比较各种健康和情感识别方法的相对优点。现实生活中的数据本文介绍了今年引入的主要新颖性,挑战指南,所使用的数据以及基线系统在三种拟议任务状态识别,AI抑郁评估和跨文化影响感知方面的表现。 website:https://github.com/AudioVisualEmotionChallenge/AVEC2019 |
| Annotation-Free Cardiac Vessel Segmentation via Knowledge Transfer from Retinal Images Authors Fei Yu, Jie Zhao, Yanjun Gong, Zhi Wang, Yuxi Li, Fan Yang, Bin Dong, Quanzheng Li, Li Zhang 分割冠状动脉是具有挑战性的,因为经典的无监督方法不能产生令人满意的结果,而现代监督学习深度学习需要手动注释,这通常是耗时的并且有时可能是不可行的。为了解决这个问题,我们提出了基于知识转移的形状一致的生成对抗网络SC GAN,这是一种无注释的方法,它使用来自公开注释的眼底数据集的知识来分割冠状动脉。所提出的网络以端对端方式进行训练,生成和分割合成图像,其保持冠状动脉血管造影的背景并保持视网膜血管和冠状动脉的血管结构。我们在1092个数字减影血管造影图像的数据集上训练和评估所提出的模型,并且实验证明了所提出的方法对冠状动脉分割的最高准确性。 |
| +方向场插值A bisector line field approach to interpolation of orientation fields Authors Nicolas Boizot LIS , Ludovic Sacchelli LIS 我们提出了一种解决方向领域全局重建问题的方法。该方法基于称为平分线场的几何模型,其将一对矢量场映射到取向场,有效地概括了倍增相位矢量场的概念。赋予了精心选择的能量最小化问题,我们提供了目标定向场的多项式插值,同时绕过了倍增阶段。然后用指纹分析的实例说明该过程。 |
| Automatic Calcium Scoring in Cardiac and Chest CT Using DenseRAUnet Authors Jiechao Ma, Rongguo Zhang 心血管疾病CVD是对人类的常见和强烈威胁,具有高流行率,残疾和死亡率。冠状动脉钙化CAC的量是CVD风险评估的有效因素。通常,CAC使用ECG同步心脏CT进行量化,但很少来自一般的胸部CT扫描。然而,与ECG同步心脏CT相比,胸部CT在临床实践中更为普遍且经济。为了解决这个问题,我们提出了一种基于Dense U Net的自动方法来分割两种类型CT扫描的冠状钙像素。我们的贡献是两倍。首先,我们提出了一个名为DenseRAUnet的新型网络,它利用了Dense U net,ResNet和atrous卷积。我们通过在胸部CT上进行专门训练来证明我们模型的稳健性和普遍性,同时对两种类型的CT扫描进行测试。其次,我们设计了一个将bootstrap与IoU功能相结合的损失函数,以平衡前景和后台类。 DenseRAUnet以2.5D方式进行培训,并在包含144次扫描的私有数据集上进行测试。结果显示,F1评分为0.75,预测心血管疾病风险的准确率为0.83。 |
| Image Enhancement by Recurrently-trained Super-resolution Network Authors Saem Park, Nojun Kwak 我们通过多次反复训练相同的简单超分辨率SR网络,引入了一种新的图像增强学习策略。在最初通过使用成对的损坏的低分辨率LR图像和原始图像训练SR网络之后,所提出的方法利用训练的SR网络来生成具有来自原始未损坏图像的双倍分辨率的新的高分辨率HR图像。然后,将新的HR图像缩小到原始分辨率,其在下一阶段中用作SR网络的目标图像。由反复训练的SR网络新生成的HR图像显示出更好的图像质量,并且这种训练LR以模拟新HR的策略可以导致更有效的SR网络。直到某一点,通过多次重复该过程,获得了更好和更好的图像。 SR的这种经常性倾斜策略可以是缩小卷积网络并使SR网络更有效的良好解决方案。为了测量增强的图像质量,我们首次在超分辨率和图像增强的这一领域使用VIQET MOS分数,它比传统的MSE测量更准确地反映人类视觉质量。 |
| Recurrent Aggregation Learning for Multi-View Echocardiographic Sequences Segmentation Authors Ming Li, Weiwei Zhang, Guang Yang, Chengjia Wang, Heye Zhang, Huafeng Liu, Wei Zheng, Shuo Li 多视图超声心动图序列分割对临床诊断至关重要。但是,由于标签数据有限,噪音巨大以及视图间隙较大,因此此任务具有挑战性。在这里,我们提出了一种循环聚合学习方法来解决这一具有挑战性的任务通过金字塔ConvBlocks,可以有效地提取多级和多尺度特征。分层ConvLSTM接下来融合这些特征并在多级和多尺度空间中捕获空间时间信息。我们进一步引入了一种用于分割和分类的双分支聚合机制,它们通过多级和多级特征的深度聚合相互促进。分段分支提供指导分类的信息,而分类分支提供多视图正则化以细化分段并进一步减少跨视图的间隙。我们的方法是作为分段和分类的端到端框架而构建的。在我们的多视图数据集9000标记图像和CAMUS数据集1800标记图像上的充分实验证实,我们的方法不仅实现了优异的分割和分类准确性,而且还实现了突出的时间稳定性。 |
| Boundary loss for highly unbalanced segmentation Authors Hoel Kervadec, Jihene Bouchtiba, Christian Desrosiers, ric Granger, Jose Dolz, Ismail Ben Ayed 用于卷积神经网络的广泛使用的损失函数CNN分割(例如,Dice或交叉熵)基于分割区域上的积分求和。不幸的是,在医学图像分析中具有高度不平衡的分割是很常见的,其中标准损失包含区域术语,其值在分段类别中通常具有几个数量级的相当大的差异,这可能影响训练性能和稳定性。这项研究的目的是建立一个边界损失,它采取轮廓空间而不是区域的距离度量的形式。我们认为边界损失可以在高度不平衡的分割问题的背景下减轻区域损失的困难,因为它使用区域之间边界上的积分而不是区域上的不平衡积分。此外,边界损失提供了与区域损失互补的信息。不幸的是,表示对应于CNN的区域softmax输出的边界点并不是直截了当的。我们的边界损失受到基于离散图的优化技术的启发,用于计算曲线演化的梯度流。在计算边界变化的积分方法之后,我们将形状空间上的非对称L2距离表示为区域积分,这避免了涉及轮廓点的完全局部微分计算。我们的边界损失是网络的区域softmax概率输出的线性函数的总和。因此,它可以很容易地与标准区域损失相结合,并且可以用任何现有的深度网络架构进行N D分割。我们的边界损失已在两个基准数据集上得到验证,这些数据集对应于缺血性中风病变ISLES和白质高信号WMH的困难,高度不平衡的分割问题。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com