学习笔记(27):零基础搞定Python数据分析与挖掘-爬虫案例2-- 链家二手房
立即学习:https://edu.csdn.net/course/play/6861/341445?utm_source=blogtoedu
网络爬虫
链家二手房信息抓取
import re
import bs4
import requests
url = r'https:sh.lianjia.com/ershoufang/pudong/pg1'
response = requests.get(url)
response
没有借助浏览器返回结果是
解决方法如下:
找浏览器 F12 F5刷新 在network下 all
找到任何一个文件点击
找到User-Agent
例如:
user-agent:
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36
把上述字符放到一个字典中
key 值是User-Agent
vlaue 就是剩下的值
head = {‘User-Agent’:'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
在requests.get(url,headers=head)
例如获取小区名称,得到的html 代码如下
name = 'a'
字典key = ‘data-el’
字典value = ‘region’
soup.findAll(name = ‘a’,attrs={‘’data-el:''region})
结果如下:
['金杨七街坊 ', '金樟花苑 ', '天环苑 ', '海光大楼 ', '上南五村 ', '惠康苑 ', '海尚康庭 ', '浦江东旭公寓1443弄 ', '朱家门小区 ', '中冶尚城 ', '红光花苑 ', '明天华城 ', '云台一小区 ', '唐丰苑 ', '仁恒河滨城(三期) ', '大华锦绣华城(十八街区)(公寓) ', '潍坊十村 ', '高行绿洲(四期) ', '临沂六村 ', '恒大小区 ', '世茂滨江花园 ', '金桥新城(一期) ', '曙光南桥小区 ', '银龙小区 ', '妙境一村 ', '南新西园 ', '梅园三街坊 ', '中海御景熙岸(公寓) ', '世华锦城 ', '锦博苑 ']
抓取户型:
html 代码是:
name = ‘div’
attrs = {‘class’:'houseInfo'}
[i.text for i in soup.findAll(name='div',attrs={'class':'houseInfo'})]
得到如下:

可以使用split 以| 分词 并且使用index获取每个元素信息
例如获取户型:
[i.text.split('|')[0] for i in soup.findAll(name='div',attrs={'class':'houseInfo'})]
获取面积:
[i.text.split('|')[1] for i in soup.findAll(name='div',attrs={'class':'houseInfo'})]
获取价格信息
首先获取价格信息的html代码
如下:
name = 'div'
attrs = {'class':'totalPrice'}
soup.findAll(name='div',attrs={'class':'totalPrice'})
price = [float(i.text[:-1]) for i in soup.findAll(name='div',attrs={'class':'totalPrice'})]
print(price)
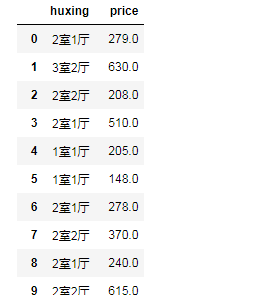
构造字典 输出表格
pd.DataFrame({'huxing':huxing,'price':price})