sklearn聚类方法详解
1 KMeans
1.1 算法描述
- 随机选择k个中心
- 遍历所有样本,把样本划分到距离最近的一个中心
- 划分之后就有K个簇,计算每个簇的平均值作为新的质心
- 重复步骤2,直到达到停止条件
停止条件:
聚类中心不再发生变化;所有的距离最小;迭代次数达到设定值,
代价函数:误差平方和(SSE)
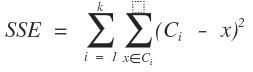
1.2 算法优缺点
优点:
- 算法容易理解,聚类效果不错
- 具有出色的速度
- 当簇近似高斯分布时,效果比较好
缺点:
- 需要自己确定K值,k值的选定是比较难确定
- 对初始中心点敏感
- 不适合发现非凸形状的簇或者大小差别较大的簇
- 特殊值/离群值对模型的影响比较大
- 从数据先验的角度来说,在 Kmeans 中,我们假设各个 cluster 的先验概率是一样的,但是各个 cluster 的数据量可能是不均匀的。举个例子,cluster A 中包含了10000个样本,cluster B 中只包含了100个。那么对于一个新的样本,在不考虑其与A cluster、 B cluster 相似度的情况,其属于 cluster A 的概率肯定是要大于 cluster B的。
1.3 效果评价
从簇内的稠密程度和簇间的离散程度来评估聚类的效果。
常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index
1.3.1 轮廓系数
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。具体计算方法如下:
- 对于第i个元素x_i,计算x_i与其同一个簇内的所有其他元素距离的平均值,记作a_i,用于量化簇内的凝聚度。
- 选取x_i外的一个簇b,计算x_i与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作b_i,用于量化簇之间分离度。
- 对于元素x_i,轮廓系数s_i = (b_i – a_i)/max(a_i,b_i)
- 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
先是计算每一个样本的轮廓系数,然后计算所有样本的轮廓系数,求平均值作为整体轮廓系数
从上面的公式,不难发现若s_i小于0,a_i > b_i, 说明x_i与其簇内元素的平均距离大于最近的其他簇,表示聚类效果不好。如果a_i趋于0,或者b_i足够大,那么s_i趋近与1,说明聚类效果比较好。
相关代码:
import numpy as np
from sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
labels = kmeans_model.labels_
metrics.silhouette_score(X, labels, metric='euclidean')1.3.2 Calinski-Harabasz Index
这个不知道怎么翻译,估计是两个人名。

类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。
在scikit-learn中, Calinski-Harabasz Index对应的方法是metrics.calinski_harabaz_score。
import numpy as np
from sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
labels = kmeans_model.labels_
metrics.calinski_harabaz_score(X, labels) 参考博客:KMeans
1.4 K值确定
- 结合业务分析,确定需要分类的个数,这种情况往往有业务上聚类的个数范围
- 手肘原则,选定不同的K值,计算每个k值时的代价函数。Kmeans聚类的效果评估方法是SSE,是计算所有点到相应簇中心的距离均值,当然,k值越大 SSE越小,我们就是要求出随着k值的变化SSE的变化规律,找到SSE减幅最小的k值,这时k应该是相对比较合理的值。
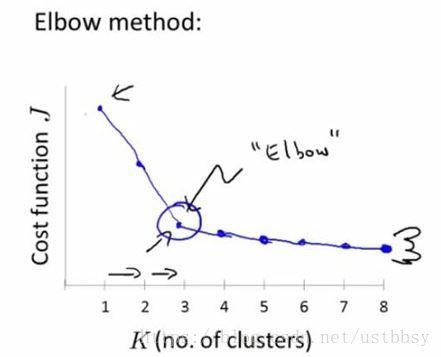
如图,在k=3之后,代价函数变化缓慢,选择聚类的个数为3
2 DBSCAN
DBSCAN(Density-Based Spatial Clustering of Application with Noise)基于密度的空间聚类算法。
两个参数:
- Eps邻域半径(epsilon,小量,小的值)
- MinPts(minimum number of points required to form a cluster)定义核心点时的阈值。
3个点
- 核心点:对应稠密区域内部的点
- 边界点:对应稠密区域边缘的点
- 噪音点:对应稀疏区域中的点
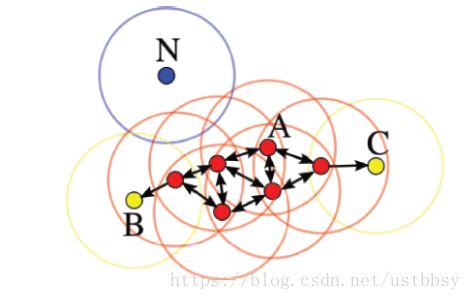
上图红色为核心点,黄色为边界点,蓝色为噪音点
几个概念:
- 核心对象:对于任一样本点,如果其Eps邻域内至少包含MinPts个样本点,那么这个样本点就是核心对象。(一个点)
- 直接密度可达:如果一个样本点p处于一个核心对象q的Eps邻域内,则称该样本点p从对象q出发时是直接密度可达的。
- 密度相连:对于样本点p和q,如果存在核心对象m,使得p、p均由m直接密度可达,则称p和q密度相连。
DBSCAN的聚类是一个不断生长的过程。先找到一个核心对象,从整个核心对象出发,找出它的直接密度可达的对象,再从这些对象出发,寻找它们直接密度可达的对象,一直重复这个过程,直至最后没有可寻找的对象了,那么一个簇的更新就完成了。也可以认为,簇是所有密度可达的点的集合。
DBSCAN核心思想:从某个选定的核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意两点密度相连。
优点:
- 不需要指定cluster的数目
- 聚类的形状可以是任意的
- 能找出数据中的噪音,对噪音不敏感
- 算法应用参数少,只需要两个
- 聚类结果几乎不依赖于节点的遍历顺序
缺点:
- 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
- DBSCAN算法的聚类效果依赖于距离公式的选取,实际中常用的距离是欧几里得距离,由于‘维数灾难’,距离的度量标准已变得不再重要。(分类器的性能随着特征数量的增加而不断提升,但过了某一值后,性能不升反而下降,这种现象称为维数灾难。对于维度灾难的理解:维度灾难的理解)
- 不适合数据集中密度差异很大的情形,因为这种情形,参数Eps,MinPts不好选择。(个人理解,如果是密度大的,你选一个小的邻域半径就可以把这些数据点聚类,但对于那些密度小的数据点,你设置的小的邻域半径,并不能把密度小的这些点给全部聚类。)
聚类形状可以是任意的,来个图直观感觉一下:

在sklearn中的应用
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5, # 邻域半径
min_samples=5, # 最小样本点数,MinPts
metric='euclidean',
metric_params=None,
algorithm='auto', # 'auto','ball_tree','kd_tree','brute',4个可选的参数 寻找最近邻点的算法,例如直接密度可达的点
leaf_size=30, # balltree,cdtree的参数
p=None, #
n_jobs=1)
3 OPTICS
是基于密度的聚类算法,OPTICS(Ordering Point To Idenfy the Cluster Structure),不显式地生成数据聚类,只是对数据对象集合中的对象进行排序,得到一个有序的对象列表。
- 核心距离(core-distance)
给定参数eps,MinPts,使得某个样本点成为核心对象(核心点)的最小邻域半径,这个最小邻域半径为该样本点的核心距离。
在DBSCAN中,给定领域半径eps和MinPts可以确定一个核心对象,如果eps比较大,在核心对象的邻域半径eps内的点的总数就会大于你所设定的MinPts,所以核心距离就是一个核心点在满足MinPts时的一个最小邻域半径。
- 可达距离(reachability-distance)
rd(y,x)表示使得‘x为核心点’且‘y从x直接密度可达’同时成立的最小邻域半径。
参考资料
https://blog.csdn.net/itplus/article/details/10089323
4 Spectral Clustering 谱聚类
1)概述
Spectral Clustering(SC,即谱聚类),是一种基于图论的聚类方法,它能够识别任意形状的样本空间且收敛于全局最有解,其基本思想是利用样本数据的相似矩阵进行特征分解后得到的特征向量进行聚类.它与样本特征无关而只与样本个数有关。
基本思路:将样本看作顶点,样本间的相似度看作带权的边,从而将聚类问题转为图分割问题:找到一种图分割的方法使得连接不同组的边的权重尽可能低(这意味着组间相似度要尽可能低),组内的边的权重尽可能高(这意味着组内相似度要尽可能高).
2)图解过程
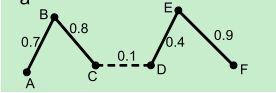
图5
如上图所示,断开虚线,六个数据被聚成两类。
3)Spectral Clustering算法函数
a)核心函数:sklearn.cluster.SpectralClustering
因为是基于图论的算法,所以输入必须是对称矩阵。
b)主要参数(参数较多,详细参数)
n_clusters:聚类的个数。(官方的解释:投影子空间的维度)
affinity:核函数,默认是'rbf',可选:"nearest_neighbors","precomputed","rbf"或sklearn.metrics.pairwise_kernels支持的其中一个内核之一。
gamma :affinity指定的核函数的内核系数,默认1.0
c)主要属性
labels_ :每个数据的分类标签
5 Hierarchical Clustering 层次聚类
1)概述
Hierarchical Clustering(层次聚类):就是按照某种方法进行层次分类,直到满足某种条件为止。
主要分成两类:
a)凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足。
b)分裂:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。(较少用)
2)算法步骤
a)将每个对象归为一类, 共得到N类, 每类仅包含一个对象. 类与类之间的距离就是它们所包含的对象之间的距离.
b)找到最接近的两个类并合并成一类, 于是总的类数少了一个.
c)重新计算新的类与所有旧类之间的距离.
d)重复第2步和第3步, 直到最后合并成一个类为止(此类包含了N个对象).
3)图解过程
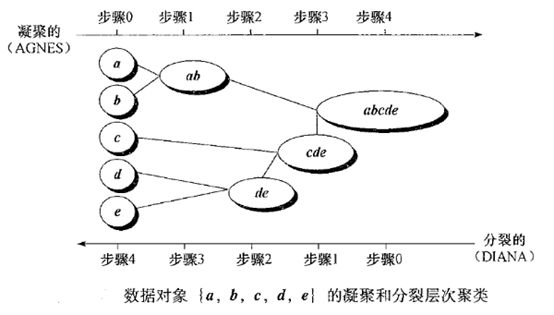
图6
4)Hierarchical Clustering算法函数
a)sklearn.cluster.AgglomerativeClustering
b)主要参数(详细参数)
n_clusters:聚类的个数
linkage:指定层次聚类判断相似度的方法,有以下三种:
ward:组间距离等于两类对象之间的最小距离。(即single-linkage聚类)
average:组间距离等于两组对象之间的平均距离。(average-linkage聚类)
complete:组间距离等于两组对象之间的最大距离。(complete-linkage聚类)
c)主要属性
labels_: 每个数据的分类标签
参考资料 聚类算法
6 Mean-shift 均值迁移
1)概述
Mean-shift(即:均值迁移)的基本思想:在数据集中选定一个点,然后以这个点为圆心,r为半径,画一个圆(二维下是圆),求出这个点到所有点的向量的平均值,而圆心与向量均值的和为新的圆心,然后迭代此过程,直到满足一点的条件结束。(Fukunage在1975年提出)
后来Yizong Cheng 在此基础上加入了 核函数 和 权重系数 ,使得Mean-shift 算法开始流行起来。目前它在聚类、图像平滑、分割、跟踪等方面有着广泛的应用。
2)图解过程
为了方便大家理解,借用下几张图来说明Mean-shift的基本过程。
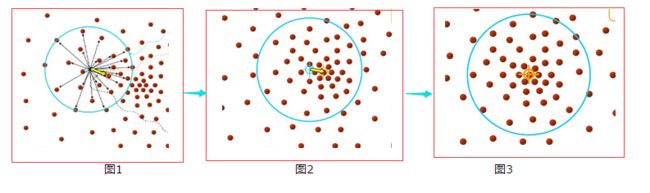
由上图可以很容易看到,Mean-shift 算法的核心思想就是不断的寻找新的圆心坐标,直到密度最大的区域。
3)Mean-shift 算法函数
a)核心函数:sklearn.cluster.MeanShift(核函数:RBF核函数)
由上图可知,圆心(或种子)的确定和半径(或带宽)的选择,是影响算法效率的两个主要因素。所以在sklearn.cluster.MeanShift中重点说明了这两个参数的设定问题。
b)主要参数
bandwidth :半径(或带宽),float型。如果没有给出,则使用sklearn.cluster.estimate_bandwidth计算出半径(带宽).(可选)
seeds :圆心(或种子),数组类型,即初始化的圆心。(可选)
bin_seeding :布尔值。如果为真,初始内核位置不是所有点的位置,而是点的离散版本的位置,其中点被分类到其粗糙度对应于带宽的网格上。将此选项设置为True将加速算法,因为较少的种子将被初始化。默认值:False.如果种子参数(seeds)不为None则忽略。
c)主要属性
cluster_centers_ : 数组类型。计算出的聚类中心的坐标。
labels_ :数组类型。每个数据点的分类标签。、
7 BIRCH
这篇文章写的很详细,可以参考一下BIRCH
8 GaussianMixtureModel(混合高斯模型,GMM)
正太分布也叫高斯分布,正太分布的概率密度曲线也叫高斯分布概率曲线。
GaussianMixtureModel(混合高斯模型,GMM)。
聚类算法大多数通过相似度来判断,而相似度又大多采用欧式距离长短作为衡量依据。而GMM采用了新的判断依据:概率,即通过属于某一类的概率大小来判断最终的归属类别。
GMM的基本思想就是:任意形状的概率分布都可以用多个高斯分布函数去近似,也就是说GMM就是有多个单高斯密度分布(Gaussian)组成的,每个Gaussian叫一个"Component",这些"Component"线性加成在一起就组成了 GMM 的概率密度函数,也就是下面的函数。
2)数学公式
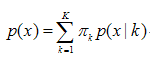
这里不讲公式的具体推导过程,也不实现具体算法。列出来公式只是方便理解下面的函数中为什么需要那些参数。
K:模型的个数,即Component的个数(聚类的个数)
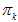 为第k个高斯的权重
为第k个高斯的权重
p(x |k) 则为第k个高斯概率密度,其均值为μk,方差为σk
上述参数,除了K是直接给定之外,其他参数都是通过EM算法估算出来的。(有个参数是指定EM算法参数的)
3)GaussianMixtureModel 算法函数
a)from sklearn.mixture.GaussianMixture
b)主要参数(详细参数)
n_components :高斯模型的个数,即聚类的目标个数
covariance_type : 通过EM算法估算参数时使用的协方差类型,默认是"full"
full:每个模型使用自己的一般协方差矩阵
tied:所用模型共享一个一般协方差矩阵
diag:每个模型使用自己的对角线协方差矩阵
spherical:每个模型使用自己的单一方差