kaggle上的Titanic之前已经提过,不再赘述。这次主要是对函数的熟悉和可视化的基础练习。
Setp0 引入所需包:
library('ggplot2') # visualization
library('ggthemes') # visualization
library('scales') # visualization
library('dplyr') # data manipulation
library('mice') # imputation
library('randomForest') # classification algorithm
Step1 获取数据
提取数据封装在db/data.r中
train <- read.csv('./input/train.csv', stringsAsFactors = F)
test <- read.csv('./input/test.csv', stringsAsFactors = F)
full <- bind_rows(train, test) # bind training & test data
特征工程1
分析数据包含的变量,发现Name包含信息较丰富Braund, Mr. Owen Harris,姓、名、称谓。我将从Name中提取出称谓,作为Title变量。
full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)
> table(full$Sex, full$Title)
——————————————————
Master Miss Mr Mrs Rare Title
female 0 264 0 198 4
male 61 0 757 0 25
有的Title人数少,对预测没有帮助,将其归入稀有类别。
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don',
'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')
full$Title[full$Title == 'Mlle'] <- 'Miss'
full$Title[full$Title == 'Ms'] <- 'Miss'
full$Title[full$Title == 'Mme'] <- 'Mrs'
full$Title[full$Title %in% rare_title] <- 'Rare Title'
提取姓氏
full$Surname <- sapply(full$Name,
function(x){strsplit(x,split='[,.]')[[1]][1]})
提取家庭人数,创建家庭变量Family
full$Fsize <- full$SibSp + full$Parch + 1
full$Family <- paste(full$Surname, full$Fsize, sep='_')
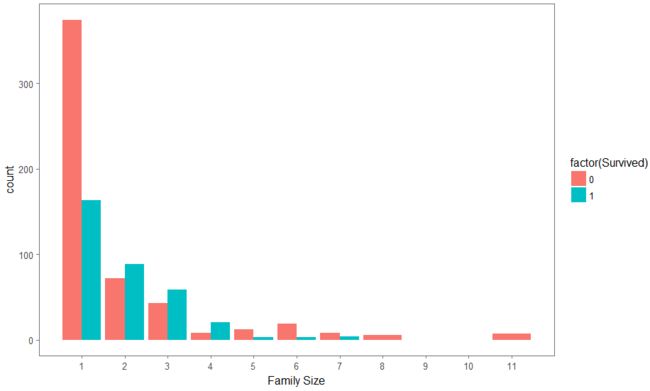
鉴于家庭人数是连续变量,R中不好处理,将其转换为离散变量,按人数分为多,少,1人。
full$FsizeD[full$Fsize == 1] <- 'singleton'
full$FsizeD[full$Fsize < 5 & full$Fsize > 1] <- 'small'
full$FsizeD[full$Fsize > 4] <- 'large'
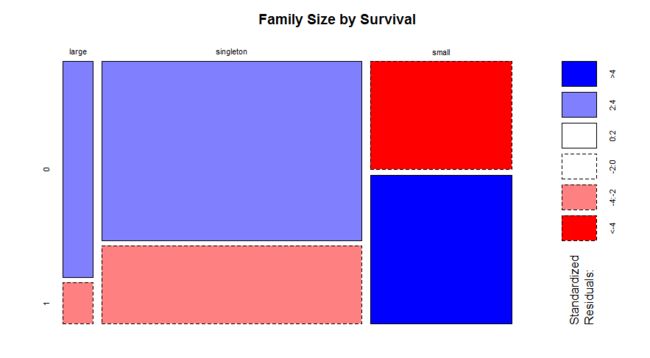
Cabin是乘客的船舱号,我们可以提取出船舱分类
full$Deck<-factor(sapply(full$Cabin, function(x) strsplit(x, NULL)[[1]][1]))
处理缺失值
62和830号乘客没有登船地点Embarked。我们用箱线图查看其它乘客的登船地点和等级以及船费的关系。其中红色虚线表示费用中位数,从左至右的框按等级依次排序。
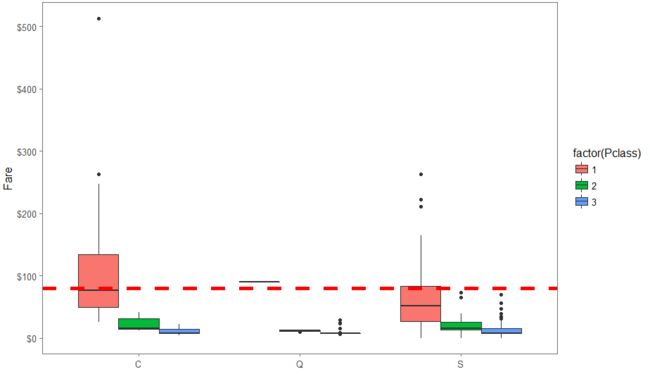
其中C瑟堡, Q昆士城, S南安普敦
由于他们62和830陈个坑的船费都是$80,我将其归为1等乘客。
full$Embarked[c(62, 830)] <- 'C'
仔细观察船费变量,发现有一位S登船的3等老年(60岁左右)男性缺失船费。查看跟他等级相同、登船地相同的其它乘客的船费信息,取其中位数。

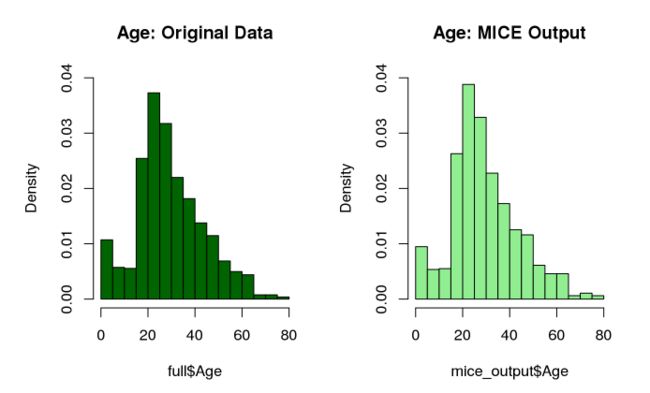
年龄中有较多的缺失值,我们用mice包来处理。
mice_mod <- mice(full[, !names(full) %in% c('PassengerId','Name','Ticket','Cabin','Family','Surname','Survived')], method='rf')
#将mice生成的结果集单独放置
mice_output <- complete(mice_mod)
与原始结果进行比较
# Plot age distributions
par(mfrow=c(1,2))
#mfrow表示生成图表1行2列显示
hist(full$Age, freq=F, main='Age: Original Data',
col='darkgreen', ylim=c(0,0.04))
hist(mice_output$Age, freq=F, main='Age: MICE Output',
col='lightgreen', ylim=c(0,0.04))
特征工程 第二回合
Megan Risdal的这一操作简直是点睛之笔(虽然对之后的预测没多大作用)。
从年龄变量,可以计算出小于18所以的满足条件,但是对于另一个特殊的身份——母亲——需要满足四个条件:
- 女性(Sex="female")
- 年龄大于18(age>18)
- 体验超过1个小孩(Parch>0)
- 称谓不是Miss(Title!="Miss")
因此有:
full$Child[full$Age < 18] <- "Child"
full$Child[full$Age >= 18] <- "Adult"
full$Mother <- "Not Mother"
full$Mother[full$Sex == "female" & full$Parch > 0 & full$Age > 18 & full$Title != "Miss"] <- "Mother"
预测
之后将数据分隔,引入相应包,train数据训练随机森林,测试test数据
set.seed(199)
rf_model <- randomForest(factor(Survived)~Pclass + Sex + Age + SibSp + Parch +
Fare + Embarked + Title +
FsizeD + Child + Mother,
data=train,#以train数据集为基础 构建随机森林模型
)
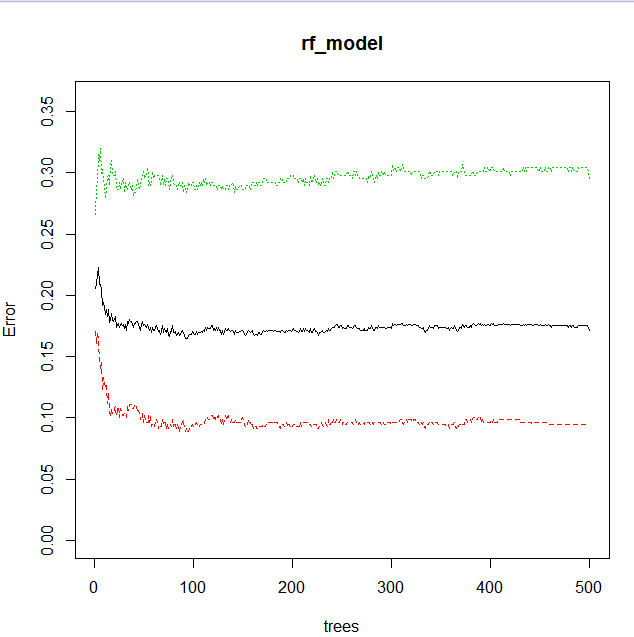
我得到了500颗树,黑色展示的是每棵树的整体错误率,红色表示对于死亡,绿色生存。
- 什么是变量重要性?
随机森林中每颗决策树的生成使用了三分之二的数据(来自一部分变量),另外未被用到的数据称为袋外数据(out of bag,OOB),这些数据可以很好的测试决策树的性能,其测试结果记作errOOB1;在袋外数据中插入干扰变量,再次测试得到errOOB2,用下面的公式可以得到(这颗决策树中使用的)变量重要性
对于变量重要性的更多解释参看这里。
#variable importance
importance <- importance(rf_model)
#importance函数描述随机森林的变量重要性
varImportance <- data.frame(Variables=row.names(importance),
Importance = round(importance[,"MeanDecreaseGini"],2))#保留2为小数
rankImportance <- varImportance %>%
mutate(Rank=paste0("#",dense_rank(desc(Importance))))
#对结果进行保留2位小数的倒序排序
#use ggplot2 to visualize the relative importance of variables
ggplot(rankImportance,
aes(x=reorder(Variables,Importance),
y=Importance,
fill=Importance))+
geom_bar(stat="identity")+
geom_text(aes(x=Variables,
y=.5,
label=Rank),
hjust=0,
vjust=.55,
size=4,
colour='red')+
labs(x="Variables")+
coord_flip()+
theme_few()
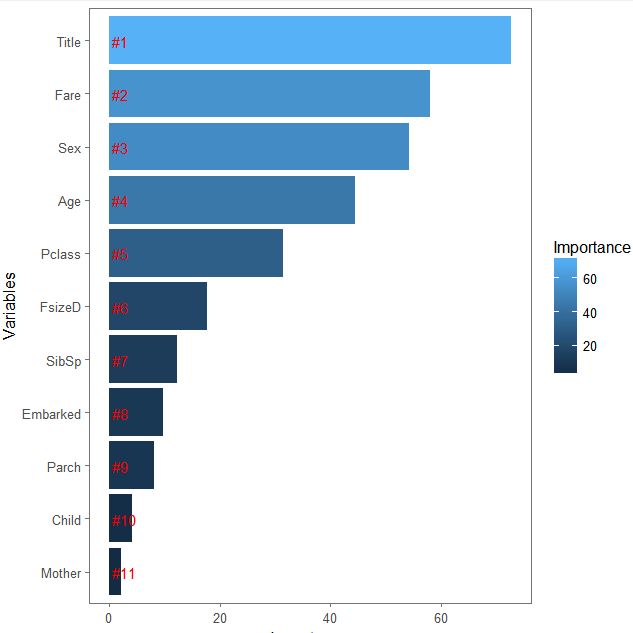
从上至下,我们可以看出:Title,Fare,和Sex这三个变量重要性最高,意味着对预测结果至关重要。

对test数据进行拟合,上传至kaggle。得分比上次的稍低,反思下原因,可能是做的不够细致,特征不够深入。