python3+Scrapy爬虫入门
创建项目
scrapy startproject douban

红框中是指出创建一个新爬虫。
创建爬虫
cd douban
scrapy genspider girls https://www.douban.com/group/641424/

自此,我们的项目算是基本创建好了,其中“girls”是指爬虫的名称,“https://www.douban.com/group/641424/”爬虫的域名。不过为了方便我们项目启动,可以在项目中新建一个entrypoint.py文件,文件内容如下:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'girls'])
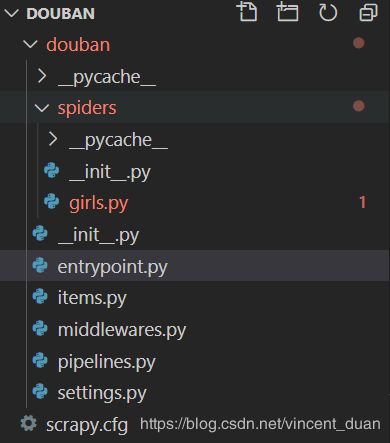
项目架构图
创建Item
创建一个新的Item方便我们保存所爬取的数据。
下面我们就来创建保存数据Item:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class GirlItem(scrapy.Item):
title = scrapy.Field() # 标题
author = scrapy.Field() # 作者
url = scrapy.Field() # url
lastTime = scrapy.Field() # 最近回应时间
detail_time = scrapy.Field() # 发帖时间
detail_report = scrapy.Field() # 发帖内容
def __str__(self):
return '{"title": "%s", "author": "%s", "url": "%s", "lastTime": "%s", "detail_time": "%s", "detail_report": "%s"}\n' %(self['title'], self['author'], self['url'], self['lastTime'], self['detail_time'], self['detail_report'])
之所以要从写__str__方法,是因为要将它展示成我们想展示的样子。
上面DoubanItem是由scrapy自动生成出来的,我们暂时先不管它,如果你想直接用系统创建的那个Item也是可以的。我这里是自己新创建一个,看起来比较好管理。
爬取网页
首先修改setting.py,添加USER_AGENT以及修改ROBOTSTXT_OBEY
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
ROBOTSTXT_OBEY = False
字段title author url lastTime在第一层URL中可以爬取到,而detail_time detail_report则是要根据url继续下钻爬取。所以在parse方法中继续下钻调用detail_parse方法,在detail_parse方法中将item保存至文件中。
完整代码:
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
from items import GirlItem
class GirlsSpider(scrapy.Spider):
name = 'girls'
allowed_domains = ['www.douban.com']
start_urls = ['https://www.douban.com/group/641424/discussion?start=25']
# 重写start_requests方法
# def start_requests(self):
# # 浏览器用户代理
# headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# return [scrapy.Request(url=self.start_urls[0], callback=self.parse, headers=headers)]
def parse(self, response):
html = response.text
soup = BeautifulSoup(html, "lxml")
# print("开始打印soup")
# print(soup)
table = soup.table
tr_arr = table.find_all("tr")
for tr in tr_arr:
item = GirlItem()
tds = tr.find_all('td')
item['title'] = tds[0].get_text().replace('\n','').replace(' ', '')
item['author'] = tds[1].get_text().replace('\n','').replace(' ', '')
item['lastTime'] = tds[3].get_text().replace('\n','')
try:
item['url'] = tds[0].find('a',href=True)['href']
# 根据内页地址爬取
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.detail_parse)
except:
item['url'] = ""
#找到下一个链接,也就是翻页
next_url = soup.find(name='div', attrs={"class":"paginator"}).find(name='span', attrs={"class":"next"}).find(name='link')['href']
if next_url:
print("开始下一页")
yield scrapy.Request(next_url, callback=self.parse)
def detail_parse(self, response):
# 接收上级已爬取的数据
item = response.meta['item']
try:
item['detail_time'] = response.xpath('//*[@id="topic-content"]/div[2]/h3/span[2]/text()').extract()[0]
except BaseException as e:
print(e)
item['detail_time'] = ""
try:
item['detail_report'] = response.xpath('//*[@id="link-report"]').extract()[0].replace('\n','')
except BaseException as e:
print(e)
item['detail_report'] = ""
write_to_file('E:/douban-detail.txt', item)
# return item
def write_to_file (file_name, txt):
# print("正在存储文件" + str(file_name))
# w 如果没有这个文件将创建这个文件
'''
'r':读
'w':写
'a':追加
'r+' == r+w(可读可写,文件若不存在就报错(IOError))
'w+' == w+r(可读可写,文件若不存在就创建)
'a+' ==a+r(可追加可写,文件若不存在就创建)
'''
f = open(file_name, 'a', encoding='utf-8')
f.write(str(txt))
f.close()
运行项目
python entrypoint.py