《数学之美》阅读笔记part2——第16章到第31章
第16章 信息指纹及其应用
1 信息指纹
将5000亿个网址随机地映射到128位二进制即16个字节的整数空间中,这16个字节的随机数就称作该网址的信息指纹。
伪随机数产生器算法PRNG:最早的冯诺依曼将一个数的平方掐头去尾取中间的几位数,现在常用梅森旋转算法。
信息指纹具有不可逆性,也就是说无法根据信息指纹推出原有信息。
如cookie
在互联网上加密要使用基于加密的伪随机数产生器(CSPRNG),常用的算法有MD5或者SHA-1等标准,它们可以将不定长的信息变成定长的128位或者160位二进制随机数。
2 信息指纹的用途
集合相同的判定:
最笨——元素一一比较,时间复杂度为O(N平方),其中N是集合的大小。
稍好——将两个集合的元素分别排序然后顺序比较,时间复杂度为O(NlogN)。
更好——将第一个集合放在一个散列表中,然后把第二个集合的元素一一和散列表中的元素作对比。时间复杂度为O(N),达到最佳,但额外使用了O(N)的空间,且代码负责。
完美——计算两个集合的指纹,然后直接进行比较。复杂度为O(N)
判定集合基本相同:
相似哈希 判断抄袭
YouTube的反盗版:
关键帧的提取和特征的提取
3 延伸阅读:信息指纹的重复性和相似哈希
MD5指纹有128位,每一千八百亿亿次才能重复一次
计算相似哈希分为扩展和收缩。
4 小结

第17章 由电视剧《暗算》所想到的——谈谈密码学的数学原理
1 密码学的自发时代
凯撒用密码传送情报,对二十几个罗马字母建立一张对应表。
对于一种好的编码方法,破译者应该无法从密码中统计出明码的规律;根据已知的明文和密文的对应推断不出新的密文内容。
把常用的词对应成多个密码。
2 信息论时代的密码学
密码的最高境界——密码之间分布均匀且统计独立时,提供的信息量最少。
公开密钥
RSA算法、Rabin算法、El Gamal算法、椭圆曲线算法
共同点:1.都有两个完全不同的样式,一个用于加密,一个用于解密;2.这两个看上去无关的钥匙,在数学上是关联的。
费尔马小定理
RSA算法简单可靠灵活,公开密钥方法保证产生的密文是统计独立而分布均匀的。且只有掌握密钥的人才可解密,即使加密者自己也无法解密。
破解公开密钥的加密方式——最彻底的为对大数N进行因式分解
破解拼计算机的速度,因此密码有有效期
公开密钥在原理上可靠,但许多加密系统在工程实现上留下不少漏洞。
Twenty years of attacks on the RSACryptosysytem
http://www.ams.org/notices/199902/boneh.pdf
第18章 闪光的不一定是金子——谈谈搜索引擎反作弊问题和搜索结果的权威性问题
1 搜索引擎的反作弊
作弊方式:重复关键词、买卖链接
反作弊:增强排序算法的抗噪声能力;去噪——道 而非术
计算每一个网站到其他网站的出链数目,计算余弦距离
2 搜索结果的权威性
用“提及”来度量权威性
计算权威度的步骤:
1) 对每一个网页正文(包括标题)中的每一句话进行句法分析,找出涉及到主题的短语以及对信息源的描述。
2) 利用互信息,找到主题短语和信息源的相关性。
3) 对主题短语进行聚合
4) 对网站中的网页进行聚合。
第19章 谈谈数学模型的重要性
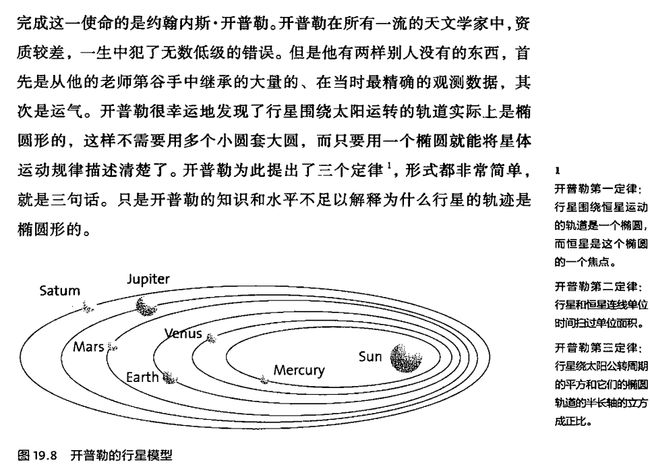
托勒密发明球坐标,定义了包括赤道和零度经线在内的经纬线,提出了黄道,还发明了弧度制。
托勒密用40-60个在大圆上面套小圆的方法,精确地计算出了所有行星运动的轨迹。


第20章 不要把鸡蛋放到一个篮子里——谈谈最大熵模型
1 最大熵原理和最大熵模型
对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。这种情况下,概率分布最均匀,预测的风险最小。

2 延伸阅读:最大熵模型的训练

GIS是一个典型的期望值最大化算法。计算量太大。改进迭代算法IIS。最大熵模型快速算法的实现很复杂。
3 小结

第21章 拼音输入法的数学原理
输入法输入汉字的快慢取决于汉字编码的平均长度,就是用击键次数乘以需要寻找这个键的时间。
1 输入法与编码
对汉字的编码分为对拼音的编码和消除歧义性的编码
2 输入一个汉字需要敲多少个键——谈谈香农第一定理
提升的关键是准确而有效地建立语言模型
3 拼音转汉字的算法
动态规划
两个节点(词)之间的距离是转移概率和生成概率的乘积
4 延伸阅读:个性化的语言模型
用户词典:一个小规模的一元模型加上非常小量的元组(比如一个用户定义的词ABC,实际上是一个三元组)
找到大量符合用户经常输入的内容和用语习惯的语料,训练一个用户特定的语言模型。
综合特定用户的语言模型和通用模型。
把各种特征综合在一起最好的方法是采用最大熵模型,但该模型复杂、训练时间长,因此可采用简化的模型:线性插值的模型。
第22章 自然语言处理的教父马库斯和他的优秀弟子们
1 教父马库斯
宾夕法尼亚LDC语料库
2 从宾夕法尼亚大学走出的精英们
格林斯:写了一个以他名字命名的自然语言文法分析器
布莱尔:基于变换规则的机器学习方法——可用于词性标注

第23章 布隆过滤器
1 布隆过滤器的原理
哈希表存储:快速准确,但耗费存储空间
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。



布隆过滤器背后的数学原理在于两个完全随机的数字相冲突的概率很小。
第24章 马尔科夫链的扩展——贝叶斯网络
1 贝叶斯网络
在网络中,每个节点的概率都可以用贝叶斯公式来计算,贝叶斯网络因此而得名。由于网络的每个弧都有一个可信度,贝叶斯网络也被称为信念网络。
得到网络拓扑结构和各个状态之间相关的概率这些参数的过程叫做结构训练和参数训练。
从理论上说,贝叶斯网络的训练是一个NP完备问题,即对现在的计算机是不可实现的。
2 贝叶斯网络在词分类中的应用
主题模型——可以用基于统计的模型分析文本,从中抽取概念,分析主题。
对每个词以文本作为维度,建立一个向量,再进行向量的聚类,那么得到的是对词的一个分类而不是对文本的分类,分出来的每一个类我们称为一个概念。
Rephil
3 延伸阅读:贝叶斯网络的训练



贝叶斯网络是一个加权的有向图。
第25章 条件随机场文法分析及其他
条件随机场是计算联合概率分布的有效模型
1 文法分析——计算机算法的演变
在选择文法规则时,坚持让被分析的句子的语法树概率达到最大。
拉纳帕提把文法分析看成是一个括括号的过程。扫描的次数是句子长度的对数函数。
2 条件随机场
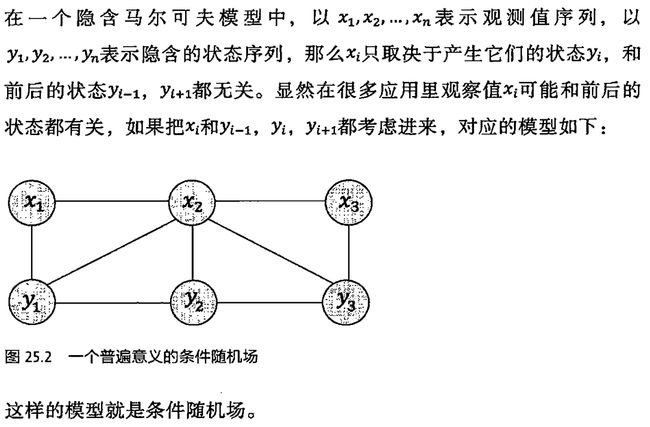
条件随机场是一种特殊的概率图模型。贝叶斯网络也是概率图模型。区别在于条件随机场是无向图,贝叶斯网络是有向图。
通过边缘分布来找到符合条件的概率分布函数。
3 条件随机场在其他领域的应用
预防犯罪
4 小结
条件随机场是一个非常灵活的用于预测的统计模型。
第26章 维特比和他的维特比算法
1 维特比算法



2 CDMA技术——3G移动通信的基础
码分多址CDMA 海蒂·拉玛尔和维特比
扩频传输

频分多址FDMA和时分多址TDMA
第27章 上帝的算法——期望最大化算法
1 文本的自收敛分类
不需要任何人工干预和先验经验。
2 延伸阅读:期望最大化和收敛的必然性

第28章 逻辑回归和搜索广告
1 搜索广告的发展
三个阶段:按广告主出价高低来排名的竞价排名广告;综合出价和点击率等因素决定广告的投放;进一步的全局优化。
预估点击率——逻辑回归模型
2 逻辑回归模型
训练最大熵模型的IIS方法可以直接用于训练逻辑回归函数的参数。
第29章 各个击破算法和Google云计算的基础

1 分治算法的原理
基本原理:将一个复杂的问题,分成若干个简单的子问题进行解决。然后对子问题的结果进行合并,得到原有问题的解。
2 从分治算法到MapReduce

第30章 Google大脑和人工神经网络
1 人工神经网络
在人工神经网络中,规定神经元函数只能对输入变量(指向它的节点的值)线性组合后的结果进行一次非线性变换。
模式分类
需要设计:结构、非线性函数(常用的函数是指数函数)。
2 训练人工神经网络
解决最优化问题:梯度下降法
有监督的训练和无监督的训练
3 人工神经网络和贝叶斯网络的关系
共同点:都是有向图,遵从马尔可夫假设;训练方法类似;对很多模式分类问题效果相似;训练计算量大。
不同点:人工神经网络在结构上是完全标准化的,而贝叶斯网络更灵活;人工神经网络的神经元函数用计算机实现起来比较容易,而贝叶斯网络中变量可以组合成任意的函数,比较复杂;贝叶斯网络更容易考虑(上下文)前后的相关性,可解码序列,而人工神经网络的输出相对独立,可估计模型的参数而不是作为解码器。
4 延伸阅读:“google大脑”
随机梯度下降
L-BFGS方法
第31章 大数据的魅力——谈谈数据的重要性
1 数据的重要性
在没有数据之前,不要给出任何结论。
散户投资人需要用数据说话,买指数基金。
2 数据的统计和信息技术
切比雪夫不等式
设计具有代表性的样本
大数据的好处:成本、准确性、多维度(全方位)