sqoop基本介绍
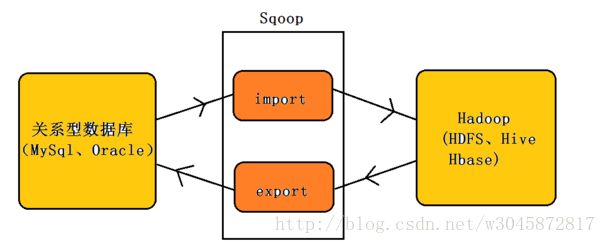
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。导入图:
sqoop的全称:sql-to-hadoop
sqoop分为连个版本,这两个版本完全不兼容
版本号的划分:
apache:1.4.x~,1.99.x~
CDH:sqoop-1.4.3-cdh4,sqoop2-1.99.2-cdh4.5.0
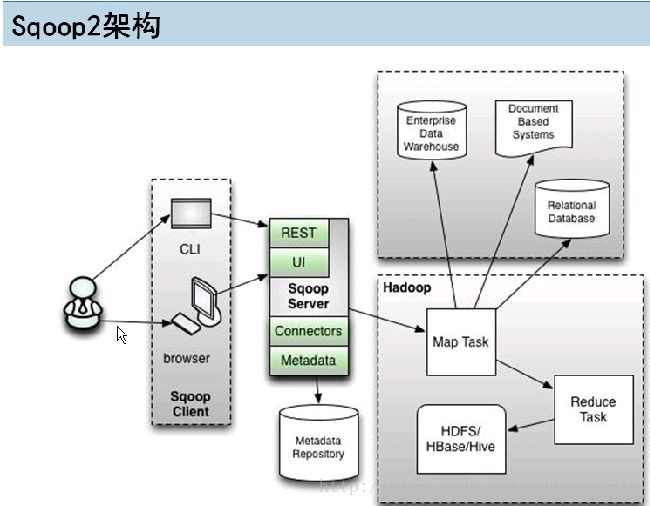
sqoop2比sqoop1改进的地方:
引入sqoop server,几种管理Connector
多种访问方式:CLI,Web UI,REST,API
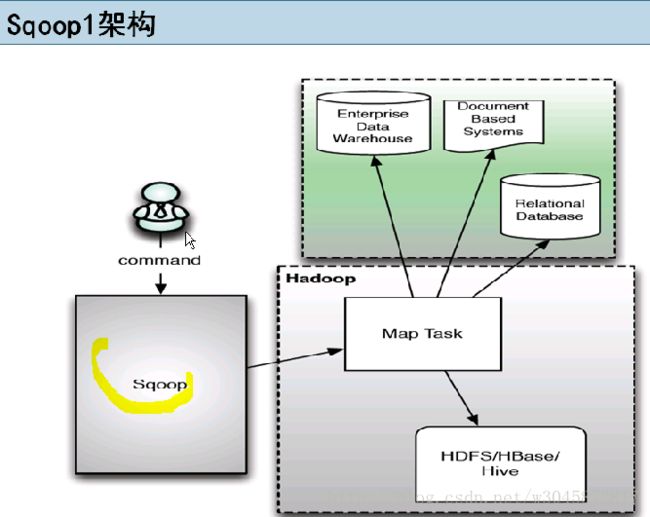
引入基于角色的安全机制sqoop1和sqoop2的架构图:
sqool安装:
http://blog.csdn.net/w3045872817/article/details/78174770
用法介绍:
Sqoop作为一个数据转移工具,必须要掌握其具体用法,下面将围绕Sqoop import to HDFS、增量导入、批脚本执行、Sqoop import to Hive、Sqoop import to Hbase、Sqoop export 几个方面进行介绍
111111111111111111111111111111111111111
1.sqoop Import to hdfs
111111111111111111111111111111111111111
sqoop import
--connect jdbc:mysql://localhost:3306/database
--username root
--password root target-dir /outdir/
--fields-terminated-by '\t'
-m 1
--null-string ''
--incremental append
--check-column id
--last-value num
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -target-dir:指的是HDFS中导入表的存放目录(注意:是目录)
- -fields-terminated-by :设定导入数据后每个字段的分隔符
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
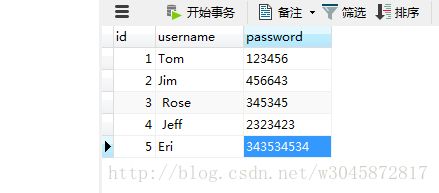
- -last-value:上一次导入的最后一个值例子:将MySQL中的数据导入hdfs:
msyql 中的数据为:
sqoop import --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --target-dir /test/ --fields-terminated-by '\t' -m 1
结果为:

111111111111111111111111111111111111111
2、增量导入
111111111111111111111111111111111111111
在实际的工作当中都是数据库的表中数据不断增加的,比如刚才的consumer表,因此每次导入的时候只想导入增量的部分,不想将表中的数据在重新导入一次(费时费力),即如果表中的数据增加了内容,就向Hadoop中导入一下,如果表中的数据没有增加就不导入—–这就是增量导入。
--incremental append :增量导入
--check-column:增量导入时需要制定增量的标准——那一列作为增量标准
--last-value:(增量导入时必须指定参考列—–上一次导入的最后一个值,否则表中的数据又会被重新导入一次) 以上次为标准:
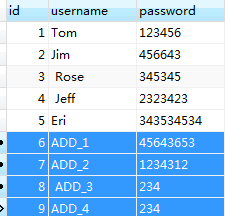
sqoop import --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --target-dir /test1/ --fields-terminated-by '\t' -m 1 --incremental append --check-column id --last-value 5
结果为:

111111111111111111111111111111111111111
3、批量导入
111111111111111111111111111111111111111
从上面导入的命令可以看出,命令行包含的命令太多了,太麻烦了,因此如果类似的作业太多的话,我们应该将其设置为一个作业,做成一个脚本文件
执行命令为:
sqoop job --create job001 -- import --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --target-dir /test2/ --fields-terminated-by '\t' -m 1
查看批脚本文件:
sqoop job --list
执行文件:
sqoop jbo -exec 即可运行批脚本文件111111111111111111111111111111111111111
4、Sqoop import to hive
111111111111111111111111111111111111111
sqoop import
--connection jdbc:mysql://localhost:3306/database
--table table_name
--username root
--password root
--hive-import
--create-hive-table
--hive-table d1.table1
--fields-terminated-by '\t'
-m 1
--null-string ''
--incremental append
--check-column
--last-value
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -hive-import 指的是将数据导入到hive数据仓库中
- -create-hive-table 创建表,注意:如果表已经存在就不用写这个命令了,否则会报错
- -hive-table 指定databasename.tablename (哪个数据库中的哪个表)
- -fields-terminated-by :设定导入数据后每个字段的分隔符
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值 使用上一个数据库的内容:
sqoop import --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --hive-import --create-hive-table --hive-table test.testdb1 --fields-terminated-by '\t' -m 1
结果为:
上面的操作类似:
hadoop jar copy.jar mysql://hadoop80:3306/hive/consumer /hive/d1.table1
111111111111111111111111111111111111111
5、Sqoop import to hbase
111111111111111111111111111111111111111
sqoop import
--connect jdbc:mysql://spark02:3306/database
--table table_name
--username root
--password root
--hbase-create-table
--hbase-table A
--column-family infor
--hbase-row-key id
--fields-terminated-by '\t'
-m 1
--null-string ''
--incremental append
--check-column id
--last-value num
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -hbase-create-table:表示在hbase中建立表
- -hbase-table A:指定在hbase中建立表A
- -column-family infor:表示在表A中建立列族infor。
- -hbase-row-key :表示表A的row-key是consumer表的id字段
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值 以上次的数据库内容为列:
sqoop import --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --hbase-create-table --hbase-table A --column-family infor --hbase-row-key id --fields-terminated-by '\t' -m 1
111111111111111111111111111111111111111
6、Sqoop export
111111111111111111111111111111111111111
22222222222222222222222222
A.HDFS to mysql
22222222222222222222222222
sqoop export
--connect jdbc:msyql://localhost:3306:/database
--table table_name
--username root
--password root
--export-dir /test1/
--fields-terminated-by '\t'
-m 1
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -export-dir 在hdfs中的位置
- -fields-terminated-by :HDFS中的文件字段的间隔符
-m:并发的map数量
sqoop export --connect jdbc:mysql://spark02:3306/test --table testSqoop --username root --password root --export-dir /test1/ --fields-terminated-by '\t' -m 1
注:从Hadoop向数据库中导入数据时,数据库中相应的表事先必须创建好。