论文笔记:Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge
感想
image caption,我看很多人翻译的是看图说话,这篇文章我通读了,感觉做的工作还是很多的,看来想做一篇好的paper需要付出很多努力,不过那个评估方式只是介绍性的,没有细讲公式,这个领域应该是比较火的领域,我感觉是由sequence to sequence模型演化而来,源代码也有,这应该是作者的伟大之处,感谢原作者的贡献和开源社区。
今天用Mac上面的safari和chrome浏览器来编写这个博客,csdn编辑器对mac chrome和safari浏览器支持不是很好,然后发现csdn的编辑器超级难用,编辑器改版后很多东西都不习惯,感觉用户体验做得更差了,编辑这篇博文的时候让我吃尽了苦头。
1 介绍
使用合适的英语语句来自动描述一幅图片的内容是一项非常有挑战性的任务,但它有很大的作用,例如帮助伤残人士来更好的理解网页上的图片的内容。这项任务比有着很好研究的图片分类和目标识别任务更难,这在计算机视觉社区成为了关注的焦点。实际上,一个描述不仅包含一幅图片的内容,而且也必须解释物体之间的相互联系,物体与物体属性的相互联系以及他们所涉及的活动。另外,上面的语义知识已经在自然语言中来解释了,像英语,这意味着除了视觉理解外,语言模型是需要的。
前面的大多数尝试都是上述子问题的解决方案,为了从一张图片得到它的描述。相比之下,我们愿意把这些工作用一个联合的模型来表示,把图片I当做输入,最大化概率P(S|I),其中,S为产生的目标单词序列,S={S1,S2,...},每个单词St来自一个给定的词典。用来充分的描述图片。
我们的工作主要受最近的机器翻译的启发,其任务是把原语言的一个句子S转换成目标语言的的翻译T,最大化P(T|S)。许多年来,机器翻译在一系列分开的任务上取得了进步(例如单独翻译词,对齐单词,重排序等等),但是最近的工作显示翻译可以做得很简单,即使用RNN,仍然能得到最好的效果。“encoder”RNN读取源句子,并且把它转换为一个丰富的固定长度的向量表示,反过来,这个作为“docoder”RNN的初始隐藏状态,来产生目标序列。
这里,我们遵循这个优雅的方法,把encoder RNN替换为一个深度CNN。在过去的几年里,CNN被证明可以产生输入图片的丰富表示,我们把图片嵌入成一个固定长度的向量,这样这个表示可用于许多视觉任务。因此,很自然的使用CNN作为图片的”encoder”,首先通过在图片分类任务来进行预训练,随后,使用其隐藏层作为RNN decoder的输入,以此来产生序列。我们把这个模型叫做Neural Image Caption或者叫做NIC。
2 贡献
我们的贡献如下:
1. 我们提出了对这个问题的端到端系统。它是一个神经网络,可以利用SGD来完全训练。
2. 我们的模型结合了用于视觉和语言模型的最好的子网络,网络可以在更大的语料库中进行训练,也可以利用额外的数据。
3. 和现在的方法相比,它取得了最好的效果,例如在Pascal数据集,NIC得到了59的BLEU得分,而现在最好的模型只有25分,而人类的得分为69.在Flickr30k上,我们把得分从56提高到了66,在SBU上,我们从19提高到了28.
3 模型
在这篇文章中,我们提出了一个神经和概率框架,用于产生图片的描述。最近在统计机器翻译上的研究表明,给定一个强有力的序列模型,通过直接最大化正确翻译的概率是有可能取得最佳效果的,在一个端到端的模式里,给定一个输入句子。这些模型利用了RNN,它把可变长度的输入编码为固定维度的向量,用这个表示来解码成想要的输出句子。于是,很自然的使用相同的方法,给定一张图片,利用相同的原则来把它翻译成描述。
于是,我们提出在给定图片的情况下,直接最大化正确描述的概率,使用下面的公式:

其中,θ是我们模型的参数,I是一幅图片,S为正确的描述,因为S表示任何句子,因此长度是无界的。于是,利用链式法则来对其在S0,…,SN上的联合概率建模,其中,N是特殊样例的长度:

其中,为了收敛,我们去掉了对θ的依赖,在训练时间上,(S,I)是一个训练样例对,我们在整个训练集合上优化log概率的和,使用梯度下降。
很自然的用RNN对p(St|I,S0,…,St-1)进行建模,其中,我们依赖的直到t-1时刻单词的可变数量用一个固定的隐藏状态或者记忆ht来表达。记忆通过新的输入xt来更新,xt需要经过非线性函数f:
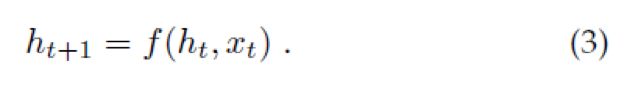
为了使得上述的RNN变成更具体,两个关键设计选择:f的具体形式是什么和图片和单词怎样作为网络的输入xt。对于f,我们使用LSTM网络,她在序列任务上显示了很好的性能表现,例如翻译。
对于图片的表示,我们使用CNN,他们已经被广泛用于图片分类任务了,现在是目标分类和检测最好的方法。我们对CNN的特别选择是选择最近batch normalization的方法,它在ILSVRC 2014分类竞赛上有着最佳的性能表现。另外,研究显示他们对其它的任务也有效,例如通过迁移学习的场景分类,这些单词被表示为嵌入模型。
3.1 基于LSTM的句子产生器
函数f的选择受它处理消失和爆炸梯度的限制,这是设计和训练RNN最普遍的挑战。为了解决这个挑战,引入了一个特别形式的循环网络,叫做LSTM,并且在翻译和序列产生上取得了巨大的成功。

如上图,LSTM模型的核心是记忆单元c,它在每个时间步输入上来编码这步观察到的东西。Cell的行为时有gates来控制的,层间用乘积实现,于是如果gate为1,就保留这个来自gated层的值,如果gate为0,则输出为0.尤其,这三个门用于控制是否遗忘当前的cell的值(forget gate f),如果他应该读取输入(input gate f),是否要输出新的cell值(output gate o).gates和cell以及输出的定义如下:
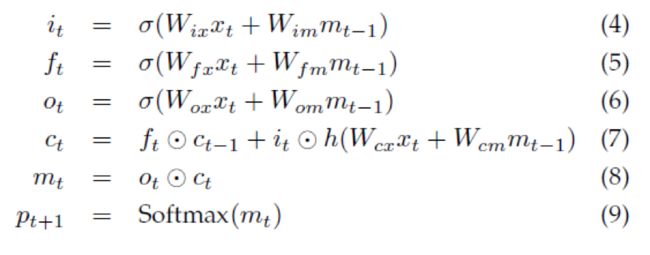
其中,
表示有一个gate值的点积,W为训练的参数。这样的乘积gates使得LSTM的训练更鲁棒,因为这三个gates能更好的处理梯度消失和梯度爆炸。非线性函数σsigmoid函数和h(.)是双曲正切函数。最后的方程mt是softmax的输入,它产生单词的概率分布pt。
3.1.1 训练
在看到图片和所有前言之后,LSTM模型训练用于预测句子中的每个单词,定义为p(St|I,S0,…,St-1)。为了达到这个目的,这对把LSTM作为一个不可控的形式是有指导性的,即LSTM的记忆的副本是为图片和句子单词而创建的,因此,所有的LSTMs共享相同的参数,LSTMs在实践t-1时刻的输出mt-1被送入了t时刻的LSTM.所有的循环链接变为在不可控的版本中的前向连接,如图3。
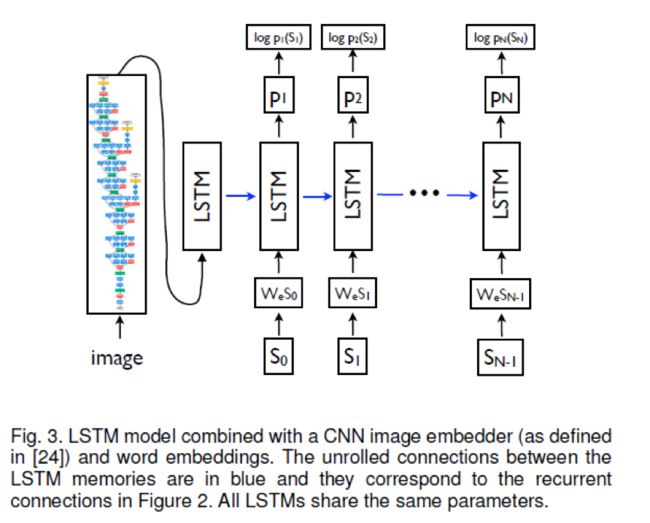
更详细地,如果我们用I表示输入图片,S=(S0,…,SN)是一个真的描述这张图片的句子,不可控过程读取:
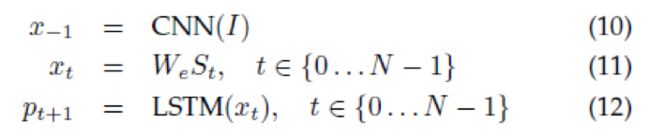
其中,我们把每个单词表示为one-hot向量St,维度为词典的大小。注意我们把S0表示为一个特别的开始单词,SN表示为一个特别的停止单词,分别表示为句子的开始和结尾。尤其是通过停止单词,LSTM信号就产生了一个完整的句子。图片和单词都被映射到相同的空间,图片使用了一个视觉的CNN,单词使用wordembedding We。图片I在t=-1时刻只输入一次,来告知LSTM关于图片的内容。我们经验地证明在每个时间步把图片作为额外的输外的输入会产生很差的效果,因为网络可以经验的利用图片里面的噪声,并且更容易过拟合。
我们的损失是每步中正确单词-log概率的和:
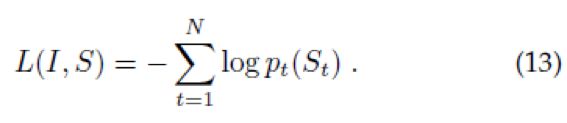
上述的损失在LSTM的所有参数上最小化,图片嵌入CNN的顶层和单词嵌入We。
3.1.2 Inference
在给定一张图片的情况下,有很多方法来产生一个句子。第一个是Sampling,根据p1仅仅采样第一个单词,随后提供对应的嵌入作为输入来采样p2,继续指导我们采样到句子的特别结尾或者一些最大长度。第二种是BeamSearch:迭代地考虑在时刻t上的k个最佳句子的集合,一次作为候选项来产生t+1时刻的句子,仅仅保留最好的K个。更好的近似:

我们在下面的实验中使用BeamSearch方法,Beam的大小为20.使用Beam的大小为1会使我们的结果退化平均2个BLEU点。
4 实验
我们做了几组额外的实验来评估我们模型的有效性,使用了一些评估尺度,数据源,和模型结构。
4.1 Evaluation Metrics
尽管有时候不清楚是否一个描述应该被认为是在给定图片上的成功的,前面的工作已经提出了一些评估标准,最可靠的(耗时的)是询问打分的人对给定图片下每个描述的有用性的客观得分。在这篇文章中,我们使用这个来加强,一些自动的评估实际上和他们的客观分数相关,前面的工作是询问评分员来给每个产生的句子打分,范围为1到4.
对于这个评估尺度,我们建立了一个AmazonMechanical Turk实验,每张图片由两个工人打分,典型的工人之间满意等级是65%。以防不满意,我们简单的对分数求平均,并记录得分的平均值。对于变量分析,我们采用bootstraping。
余下的评估可以自动进行计算,假设有groundtruth。例如人类产生的描述,目前为止在图片描述文学最通用的评估是BLEU得分,它是一个单词预测的一种形式,即产生句子和参考句子的n-grams。即使这个评估有一些显而易见的缺点,但是结果显示它和人类评估关联很好。在这个工作中,我们对其进行了加强,详细见4.3节。评估协议的拓展以及我们系统产生的输出可以在http://nic.droppages.com/找到。
除了BLEU以外还有,可以使用模型对给定模型的转录的perplexity,perplexity是每个预测概率的逆概率的几何平均,我们使用这个评估方式在集合(held-outset)上进行模型选择和参数调优,BLEU一直是更好的选择,因此我们就没有对它进行过多阐述。
最近,出现了一个新颖的评估方式,叫做CIDER,它用于MS COCO Captioning challenge来组织。总而言之,它很亮产生的n-gram和参考的句子的一致性,其中,一致性是带权的n-gram显著性和罕见性加权(n-gramsaliency and rarity)。
上述的评估方式有许多缺点,我们提出了使用METEOR和ROUGE评估方式的额外结果。
最后,当前图片描述的文学也使用代理任务来对图片的一段描述集合进行排序。这样做有其优势,我们可以使用周知的排序评估方式向recall@k,另一方面,把描述生成任务转换为一个排序任务是不满意的:随着图片描述的复杂度上升了,词典和可能的句子的数量成指数性增长,一个预定义的句子适合一幅图片的可能性会下降,除非这样的句子也成指数型增长,但这是不现实的;因潜在的评估这样每幅图片大量句子语料库的计算复杂度很大,相同的方式也用于语音识别了,其中一个在给定声音序列下产生句子;而早期的尝试居中在孤立的音素和单词的分类上,现在这个任务最好的方法是生成式的,模型可以从很大的词典中产生句子。
既然我们的模型可以产生合理质量的描述,即使在衡量图片描述上有模糊性(有很多合法的描述不在groundtruth中)。我们相信我们应该关注生成任务的评估方式而不是排序。
4.2 数据集
为了进行评估,我们使用了许多数据集,它包含图片和对图片的英文描述,数据集的统计如下:

除了SBU数据集,每张图片用5张标记好的句子,句子是相对视觉的(visual)和无偏的(unbiased)。SBU的描述是图片拥有者给的,图片来自Flickr。他们不能保证是视觉的或者无偏的,因此数据集有很多噪声。
Pascal数据集为测试定制的,在SBU的数据集中我们用1000张图片做测试,剩下的图片做训练。相似地,我们从MSCOCO验证集合中随机采样4K图片,叫做COCO-4k,并把它用于下面的部分。
4.3 结果
我们的模型是数据驱动并且是端到端训练的,给定丰富的数据集,我们想要回答一些问题,例如“howdataset size affects generalization”,“what kinds oftransfer learning it would be able to achieve”,“how it would deal with weakly labeled examples”,结果,我们在五个不同的数据集上进行了实验,这使得我们能更深入的理解我们的模型。
4.3.1 训练细节
训练的时候,我们遇见的很多挑战是训练模型的时候得处理过拟合,纯监督的方法,需要大量的数据,但是那些高质量的标签少于100000张。幸亏有像ImageNet的数据集,使得指派一个描述的任务比目标分类更难,数据驱动任务最近成为了主流。结果,我们相信,我们得到的结果会很好,相对于大多数当前人类工程的方法,我们方法的优点在最近几年会随着训练集的增加而增长。
然而,我们用一些技术来处理过拟合。防止过拟合的最显而易见的方式是把我们系统的CNN组件的初始化权重用预训练模型来初始化。我们在所有的实验中都使用了这种方式,就泛华能力而言,这种方式很不错。另一个权重的集合是初始化We,word embeddings。我们尝试用一个大的新闻语料库来初始化他们,但是没有得到很好的效果,为了简单我们未对它们进行初始化。最后,我们做了模型级别的防止过拟合的技术,我们尝试dropout和集成模型,也利用了模型的大小,均衡隐藏单元和深度的数量。Dropout和集成使得BLEU提升了一些。
我们用SGD来在所有的权重集合上进行训练,用了固定的学习率,没有momentum。所有的权重都是随机初始化,除了CNN的权重,CNN的权重不变,因为改变他们有一个负面影响。我们使用512维度用于embedding和LSTM memory的大小。
我们用基本的分词预处理了描述,保留在训练集上至少出现5次的数据集。
4.3.2 Generation Results

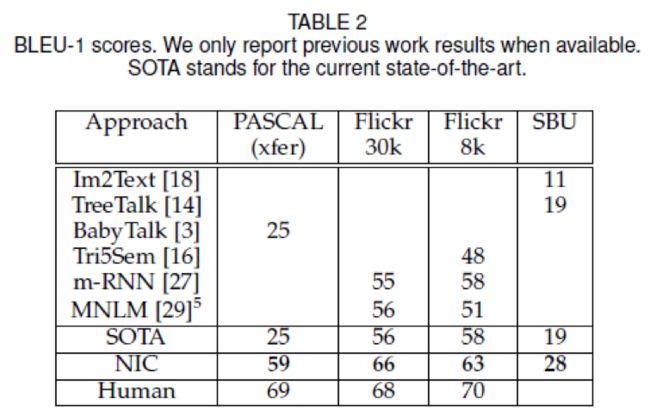
如上表1,表2,由于PASCAL没有训练集,我们使用MSCOCO数据集进行训练,使用PASCAL和SBU数据集的最好结果不是使用基于图片内容的深度学习,因此可以说,这些分数的巨大改善来自于这种变化,最近也使用了Flickr数据集,但是大多是在检索框架上进行评估。但是一个著名的例子除外,他们同时做检索和生成,并且这是在Flickr上的最好性能。
表2的人类的分是通过其中一个人的说明文字和其它四个比较计算得来的。我们用五个评分人来做这件事,然后取他们的BLEU得分的平均值。因为这给我们的系统带来了轻微的优势,给出了BLOU分数,这是根据五个参考句计算出来的,不是四个,我们在人类的基础上加上了五次应用的平均差异,而不是四次。
在过去的几年里,这一领域取得了重大的进展,我们认为BLEU-4的报告更有意义,这是机器翻译的标准。另外,我们展示了更好的联系人类的评估。尽管最近有更好的评估方式的效果,我们的模型和人类评分者相比有很大的差距。可是,当我们使用人类评分来衡量说明文字的时候,我们的模型更差。详细讨论请继续往下看。
4.3.3 迁移学习,数据大小和标签质量
因为我们已经训练了许多模型,我们有一些测试集,我们想要研究是否我们可以把一个模型迁移到一个不同的数据集,有多少域的不匹配会被补偿,例如高质量的标签或者更多的训练数据。
迁移学习和数据大小的最明显的示例是Flickr30k和Flickr8k。这两个数据集标记相似,因为他们是由相同的组来创建的,当在Flickr30k上训练的时候,结果提高了4BLEU点。明显在这个示例中,我们得出,通过增加更多的训练数据,模型性能会提高,因为整个过程是数据驱动并且是过拟合剪枝的。MSCOCO更好,数据集的大小是Flickr30k的5倍,但是由于他们的搜集过程是不一样的,他们在词汇上有很大的不同,并且很多不匹配。因此,所有的BLEU得分退化了10个点。因此,描述仍然是合理的。
因为PASCAL没有官方的训练集,是单独来收集的,独立于Flickr和MSCOCO,我们从MSCOCO上来做迁移学习,如表2.在Flickr30k来做迁移学习得到了更差的结果,BLEU-1是53,而MSCOCO的迁移模型得分是59.
最后,即使SBU有弱标记(weak labeling,例如标签就是说明文字,不是人类产生的描述),有更大和更有噪声的词汇,任务更难。可是,有更多的数据来进行训练。当把MSCOCO模型用于SBU上的时候,我们的得分从28退化到了16。
4.3.4 Generation Diversity Discussion
在训练了一个生成式模型p(S|I),一个很明显的问题是模型是否产生新颖的描述(novel captions),产生的captions是否是多样性和高质量的。

表3显示的是当从beamsearch decoder返回N个最佳的列表的结果,不是假设最佳的。注意样本的多样性的程度可能会显示图片的不同方面。排在前15的产生的句子,BLEU得分是58,这和人类的水平很相似。这意味着我们模型产生的多样性的数量。加黑的是训练集里面没有的句子。如果我们选择最佳的候选,其中句子的80%都是训练集里面的。这不怎么惊讶,因为训练数据的数量是相当小的,因此模型相对很容易来选择“exemplar”句子,并且用它来产生描述。如果我们分析产生前十五的句子,至少有一半的是产生的新描述,但是仍然又一个想死的BLEU得分,意味着他们的质量很好,因此模型又一个健康的多样性(healthy diversity)。
4.3.5 Ranking Results
我们认为排序不是评估看图说话的一种满意的方式,但是许多论文报告了排序了得分,使用测试描述集合作为候选集来排序一个给定的图片。这个方法在这些评估方式上(MNLM)效果最好,特别的实现了了排序感知的损失。然而,NIC在排序任务(给定图片来排序描述,给定描述排序图片)的结果很好。如表4和表5.

4.3.6 人类评估
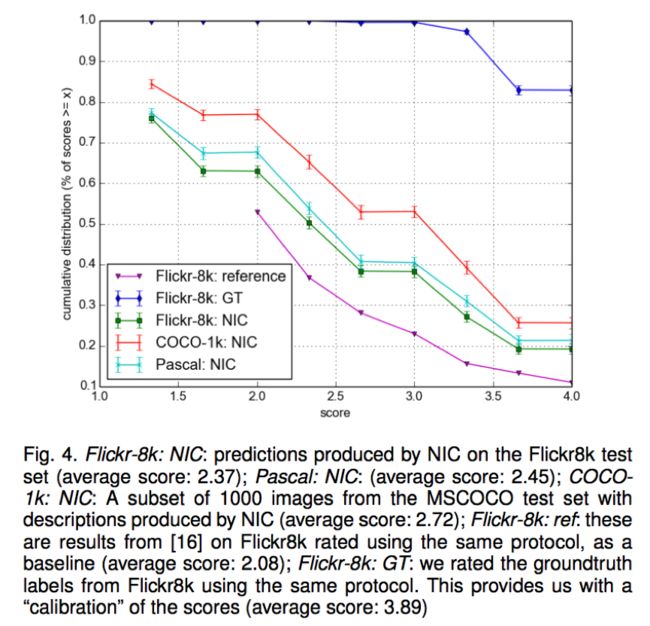
描述的人类评估结果如图4,由NIC和参考系统和不同数据集的groundtruth提供。我们可以看到,NIC比参考系统更好,但是比groundtruth更差。正如预料的那样,BLEU不是一个完美的评估方式,因为它不能捕获NIC和人类描述的区别,人类描述是由评分者评估的。评分的图片的样例如图5,

很有趣的是,例如第一列的第二张图片,模型是怎样注意到frisbee的。
4.3.7 嵌入的分析
为了把前面的单词表示St-1作为输入,用来解码LSTM,以此来产生St,我们使用word embedding向量,它独立于词典的大小,不是一个简单的one-hot-embedding方法。另外,这些word embeddings可以和剩下的模型进行训练。值得注意的是学习到的表示是怎样从语言的统计学中捕获一些语义的。表6显示,对于少量的样例单词序列,其最近的其它单词可以在其嵌入空间中学到。

注意到模型学习到的一些关系对视觉部分是有帮助的。真正的,“horse”,”pony”和“donkey”彼此靠近会使得CNN提取的特征和horse-looking animals相关。我们假设,在一个类别只有很少几个样例的极端例子(“unicorn”)中,它和其它词嵌入(例如“horse”)的邻近应该提供更多的信息,但这些信息会在传统的基于bag-of-words的方法中会完全失去。
5 MS COCO Image Captioning的挑战
在2015年的春天,作为MS COCO数据集部分的一个挑战被提出,并且组织了比赛,参与者用MSCOCO 2014数据集来训练他们的算法,并提交其在验证集和测试集上的结果于评估服务器上,每个组尝试不超过5次,为了限制其在测试集合上的果泥和,人类菜盆评估了竞赛的方法,获胜者被邀请到在CVPR 2015的workshop上来展示他们的方法。
5.1 度量(Metrics)
评估方法已经在第4部分讨论了,特别强调的是CIDER,这是组织者选择用来对队伍排序的。结果,我们在超参数选择期间也选择这种方式。
我们发现所有自动评估彼此相互联系相当强,如表7.

尤其,这些评估方式的主要区别是人类怎样排序VS一些自动看图说话系统。有趣的是,BLEU(人类排16中的13)似乎是相当的差,CIDER(人类排第6)相对高一点;METEROR是自动的评估,人类的得分最高(第三)。
5.2 Improvements Over Our CVPR15 Model
在这个部分,我们分析模型的部分对模型的预测的提升。5.3部分显示的是MSCOCO 竞赛的自动和人类评估。我们在表8里面总结了所有的改进。

为了复现,我们也开源了我们的Tensorflow的模型的实现。地址如下:
https://github.com/tensorflow/models/tree/master/im2txt (failed)
https://github.com/tensorflow/models/tree/master/research/im2txt (update)
5.2.1 图片模型的改进
当我们首次把我们的模型提交到CVPR2015的时候,我们当时使用的是最好的CNN,叫做GoogleLeNet,它有22层,是2014年ImageNet竞赛的获胜者。后来,我们使用了更好的方法,其中包括一个新的方法,Batch Normalization,更好的规范化当前batch样例下每层的神经网络,使得其非线性更加鲁棒。新方法在ImageNet任务中得到了显著的提升,从6.67%减小到4.8%.在MSCOCO image captioning任务上提升了2个BLEU-4的点。
5.2.2 图片模型微调
在原始的实验集合中,为了避免过拟合,我们用一个预训练的模型来初始化图片卷积网络,我们首先用GoogleLeNet,随后转向了更好的Batch Normalization模型。但是固定住其参数,仅仅在MSCOCO训练集上训练模型的LSTM的部分。
为了竞赛,当训练LSTM的时候,我们也考虑了一些图片模型的微调,这样更能帮助图片模型集中到在MSCOCO训练集上的图片上,最终提升了其在captioning任务上的性能。
值得重要的注意是微调图片模型一定要先把LSTM参数调到一个好的语言模型:我们发现,当同时训练两个模型的时候,初始梯度的噪声从LSTM传到图片CNN模型,使得图片模型变差,并且永不恢复。相反,我们把我们的模型训练了500K步,固定了CNN参数,转而联合训练模型达100k步。使用了一个GPU进行训练,每步的时间大约是3秒。于是,训练话了3周时间,并行训练会产生更差的结果,然而它加速了收敛的速度。
这个模型的提升是1个BLEU-4的点,更重要的是,这个改变使得模型把信息从图片传递到语言,这是不可能的,因为ImageNet标签的空间的覆盖度不足。例如,改变后,我们发现了许多阳历,其中我们预测到了正确的颜色。例如.”A blue andyellow train…”。顶层CNN激励在ImageNet-specific类别上被过度训练了,并且可以抛弃有趣的特征,例如颜色。于是,在没有fine tuning图片模型的情况下,captiongeneration模型可能不输出对应那些特征的单词。
5.2.3 Scheduled Sampling
我们的模型使用了一个LSTM来产生给定图片的描述,如图3,在给定最好的模型和caption的前面一个单词的情况下,训练的LSTM尝试来预测caption的每一个单词。在推断中,对于一张新图片,先前的单词显然是未知的,于是通过模型自身产生单词来代替。于是训练和推断上有一个差异。最近,我们提出了一个curriculum学习策略来温和的把训练过程从一个fully guided scheme 转换为一个lessguided scheme,fully guided scheme的意思是使用真实的前面的单词,lessguided scheme的意思是大多使用模型产生的单词。我们应用了这个策略,使用了不同的安排(schedules)来比赛,发现相比标准的目标函数训练提升了1.5个BLEU-4的点。
5.2.4 集成
集成是一个长久以来非常简单且高效的方式,使得机器学习系统得到提升。在深度体系结构的环境下,在相同任务上只需要分开的训练多个模型,潜在的改变一些训练条件,在推断时间来聚合他们的答案。为了竞赛,我们创造了5个集成模型,用Scheduled sampling来进行训练,其中10个模型微调了图片模型来进行训练。结果模型提交到了竞赛中,把我们的结果提升了1.5个BLEU-4个点。
5.2.5 Beam大小约简
为了用我们的方法来产生一个句子,我们使用3.1部分的BeamSearch,其中我们维持了top-k单词序列的列表。在原始的论文中,我们尝试只使用两个值k:1和20.这意味着模型在每个时间步只保留最佳的产生的单词。
为了比赛,我们实际上尝试了很多beam size的大小,选择了根据CIDER评估上产生最佳单词序列的大小,我们考虑与人类判断的的最好的对齐。和我们的期望相反,最佳的beam大小很小:3.
注意到,随着beam的大小的增长,我们得到了更多的候选句子,根据所获得到的可能性选择最佳的。因此,如果模型训练好了,其可能性和人类判断一致,增加beam的带小会产生更好的句子。现实是我们用一个相对小的beam大小来获得的最好的性能,要么就是模型已经过拟合了或者训练的目标函数和人类的判断是不对齐的。
我们也观察到,通过见效beam的大小,例如用一个浅层的句子搜索。我们增加了产生句子的新颖性,而不是重复80%的训练的captions,这个比例减少到了60%。假设支持事实,模型已经过拟合到训练集,我们得出这个约简的beam大小技术作为另一种正则的方式,通过增加推导过程的一些噪声。
减少beam的大小是一个单个的改变,它是的CIDER的得分提升最多。这个简单的改变提升了2个BLEU-4的点。
5.3 竞赛结果
5.3.1 自动评估
所有的队伍允许5次提交到评估服务器,评估的是大规模的未看见的测试图片集合(ona large, unseen set of test images)。允许团队监控进度排行榜,这激发我们持续提升我们的模型,指导deadline,即使自动评估不完全反应captions的质量,有很强的相关性,例如提升一个自动评估的分数通常意味着一个更好的captioning系统。
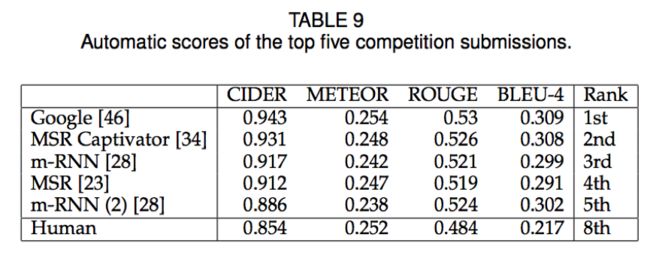
因为我们提交了我们的paper,幸亏所有的改进,我们BLEU-4得分提升了8个绝对点,根据在测试集合上的自动评估方式(按照CIDER评估,使用5个ground truth captions),得到的结果如表9.
5.3.2 人类评估
MSCOCO challenge的最好的15次提交和一个人类的baseline用了5个不同的评估方式来评估。
M1 caption 评估大于或者等于人类评估的比例
M2 通过图灵测试的captions的比例
M3 captions平均正确性(incorrect-correct),范围为1-5。
M4 captions的的斜街的平均数量,维度为1-5(lackof details-very detailed)。
M5 和人类描述相似的比例
注意,M1和M2是来决定获胜者的,其它的仅仅是试验,但是为了完整性,也会报告。
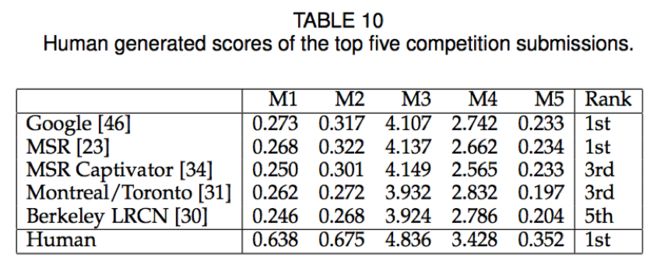
结果在竞赛网站的排行榜上(theLeaderboard of the competition website),网址为http://mscoco.org/dataset/#captions-leaderboard,根据M1和M2的评估,排在前5的提交如表格10:
最终,我们在图6展示了少量的样例图片,伴有caption,这些是由我们原来的模型产生的。

我们从development集合中随机采样20张图片,选择了最有趣的图片。很明显captions的整体质量提升明显,BLEU-4的提升是8个绝对点。
参考文献
[1]. Oriol Vinyals, Alexander Toshev, Samy Bengio, DumitruErhan: Show and Tell: Lessons Learned from the 2015 MSCOCO Image CaptioningChallenge. IEEE Trans. Pattern Anal. Mach. Intell. 39(4): 652-663 (2017)