深度学习中的数学(二)——线性代数
文章目录
- 一、理解线性
- 1.1 线性方程组
- 1.2线性代数的角度理解过拟合
- 1.3 线性可分与线性不可分
- 1.3.1 与(&)、或(|)、抑或(^)
- 1.4 张量
- 1.5 范数
- 1.6 Normalize
- 1.7 行列式
- 1.8 奇异矩阵
- 1.9 矩阵和张量的基本运算
- 1.10 逆和伪逆
- 1.11 最小二乘法
- 1.12 其他矩阵
- 二、內积与投影
- 2.1 內积与投影
- 2.2 余弦相似度
- 2.3 相关性
- 2.4 线性变换(特殊的仿射变换)
- 2.5 仿射变换
- 2.6 特征方程
- 2.7 相似变换
- 2.8 奇异值分解(SVD)
- 2.9 谱范数
一、理解线性
1.1 线性方程组
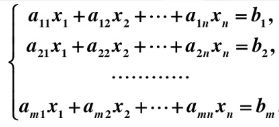
AX=B

1.2线性代数的角度理解过拟合
过拟合:参数量过多,数据过少(这里数据等价了)
解决:减伤参数量,增加数据量
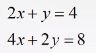
正常情况:

欠拟合:参数量过少,数据过多(这里不等价)
解决:增加参数量

1.3 线性可分与线性不可分
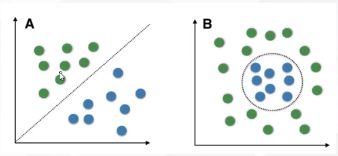
线性可分的定义:
线性可分就是说可以用一个线性函数把两类样本分开,比如二维空间中的直线、三维空间中的平面以及高维空间中的超平面。(所谓可分指可以没有误差地分开;线性不可分指有部分样本用线性分类面划分时会产生分类误差的情况。)
判断是否线性可分:不同样本集用凸包包起来,判断不同凸包的边是否有交叉。
1.3.1 与(&)、或(|)、抑或(^)
与问题:两位同时为“1”,结果才为“1”,否则为0
或问题:只要a,b两个条件有一个成立,则整个语句成立
抑或问题:如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0
解决线性不可分问题:①非线性的方法②核方法(是一类把低维空间的非线性可分问题,转化为高维空间的线性可分问题的方法。核方法不仅仅用于SVM,还可以用于其他数据为非线性可分的算法。)
1.4 张量
标量(0维)
向量(1维)
矩阵(2维)
张量(多维数组)
from PIL import Image
import numpy as np
img = Image.open("1.jpg")
img_data = np.array(img)
print(img_data.shape)# (H,W,C)
1.5 范数
它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。

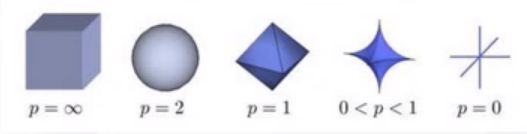
零范数:非零的个数
一范数(曼哈顿距离):绝对值相加
二范数(欧式距离):向量的模
无穷范数(切比雪夫距离):向量中取最大值
关于范数,可以看这篇文章:范数与距离的关系
1.6 Normalize

适用于符合正态分布的数据
归一化原因:
①数据过大,梯度很平滑,不利于梯度下降;
②数据过大,矩阵结果过大,计算机不能显示(NaN);
③进行归一化的原因是把各个特征的尺度控制在相同的范围内,这样可以便于找到最优解,不进行归一化时如左图,进行归一化后如右图,可发行能提高收敛效率。(用身高体重财富来想,反向传播时梯度不一样,梯度下降会不平稳,模型不稳定,精度收敛差,即错过最优解,训练不出来)
1.7 行列式
要求:必须是方阵,即行=列
行列式用来衡量矩阵的大小。
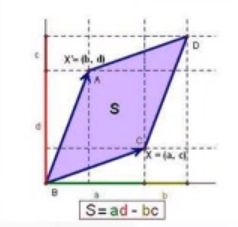
![]()
代码计算行列式:
import numpy as np
import torch
a = np.array([[1,2],[3,4]])
print(np.linalg.det(a))# -2.0000000000000004
b = torch.tensor([[1.,2.],[3.,4.]])
print(b.det())# tensor(-2.0000)
1.8 奇异矩阵
行列式等于0位奇异矩阵如np.array([[1,2],[1,2]])
行列式不等于0位非奇异矩阵
1.9 矩阵和张量的基本运算
加\减(对应位置相加\减)
数加\数减(一个数与矩阵加减)
点乘(对应位置相乘)
数乘(一个数与矩阵相乘)
叉乘(满足mxn@nxp–>mxp;或者HXY@HYN–>HXN;或者ABCD@ABDN–>ABCN)(不满足交换律)
转置:换轴
叉乘代码举例:
import torch
a = torch.arange(12).reshape(2,3,2)
b = torch.arange(12).reshape(2,2,3)
print((torch.matmul(a,b)).shape)# torch.Size([2, 3, 3])
print((b@a).shape)# torch.Size([2, 2, 2])
转置代码举例:
# torch
a = torch.arange(12).reshape(2,3,2)
print(a.permute(2,1,0))
print(a.T)
# numpy
c = np.arange(12).reshape((2,3,2))
print(c.T)
print(np.transpose(c))
代码实现矩阵:点乘(內积)、叉乘(矩阵乘法):
import numpy as np
import torch
#向量点乘(对应位置相乘再相加)
a = np.array([1,2,3])
b = np.array([2,3,4])
print(np.multiply(a,b))# [ 2 6 12]
print(a*b)# [ 2 6 12]
print(np.sum(a*b)) # 20
# 矩阵乘法(叉乘)
# a的列数等于b的行数方可相乘
a = torch.arange(6).reshape(2,3)
b = torch.arange(6).reshape(3,2)
print(a @ b)
# tensor([[10, 13],
# [28, 40]])
print(torch.matmul(a,b))
# tensor([[10, 13],
# [28, 40]])
# 矩阵乘法
# a的列数等于b的行数方可相乘
a = np.arange(6).reshape(2,3)
b = np.arange(6).reshape(2,3)
print(a@b.T)
print(a.dot(b.T))
print(np.matmul(a,b.T))
#三个结果都是:
#[[ 5 14]
# [14 50]]
1.10 逆和伪逆
逆的运算相当于矩阵的除法运算
只有非奇异方阵才有逆
伪逆是逆的推广,去除了方阵的限制

1.11 最小二乘法
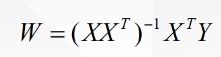
代码实现最小二乘法,在数据量小的时候可以使用:
import numpy as np
x = np.matrix(np.array([[3],[1],[6]]))
y = 4*x
print(x)
print(y)
print((x.T@x).I@x.T@y)# [[4.]]
1.12 其他矩阵
对角矩阵:是一个主对角线之外的元素皆为0的矩阵。对角线上的元素可以为0或其他值。
单位矩阵:它是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1。除此以外全都为0。
零矩阵:零矩阵即所有元素皆为0的矩阵。
一矩阵:一矩阵即所有元素皆为1的矩阵。
对称矩阵:是指以主对角线为对称轴,各元素对应相等的矩阵。
稀疏矩阵:在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。
下三角阵:主对角线及下面有值,上面没值
正交阵:P的逆等于P的转置或P的转置乘以P等于单位阵I
代码实现:
import numpy as np
import torch
# 对角矩阵
a = np.diag([1,2,3,4])
print(a)
b = torch.diag(torch.tensor([1,2,3,4]))
print(b)
# 单位矩阵
c = np.eye(3,4)# 多余的用0替代
print(c)
d = torch.eye(4,3)
print(d)
# 下三角阵
e = np.tri(3,3)
print(e)
f = torch.tril(torch.ones(3,3))
print(f)
# 零矩阵、一矩阵
g = np.ones((3,3))
print(g)
h = np.zeros((3,3))
print(h)
out:
"""
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
tensor([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 0.]])
[[1. 0. 0.]
[1. 1. 0.]
[1. 1. 1.]]
tensor([[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]])
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
"""
二、內积与投影
2.1 內积与投影

代数定义:
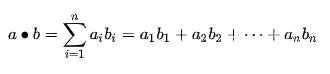
几何定义:
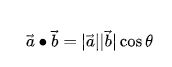
2.2 余弦相似度


正相关、负相关、不相关
余弦相似度与欧式距离的关系:
当向量做了二范数归一化后的向量(即模为1),有这个等价关系(欧式距离越小,余弦相似度越大)

2.3 相关性
![]()
线性相关(正、负)
线性无关
基与标准正交基
完备正交基
理解:两个向量,有一个点投影到一个向量上,如果它移动了,会对另外一个向量产生影响,这两个向量就是相关的。(建一个坐标系,每个轴应该不相关)
轴在线性代数里面称为基。轴可以代表一个特征方向
如果两个轴能构成一个平面空间,则他们就是这个平面空间的完备基。(三维空间中两个轴就不能构成完备基)
垂直一定不相关;不相关不一定垂直(傅里叶变换)。.
机器学习的本质:将数据分解到特征方向上,在每个特征方向单独判断,结果统一起来得到一个结果。(做特征分解)
矩阵由多个向量构成,如果多个向量之间是两两不相关的,如果矩阵是方阵,则其为完备正交基,可以构成一个空间,每个向量就是空间上的轴。(3x3可以构成3维空间,4x4构成4维空间)(4x3不能构成基;3x4:4维空间有3根轴,基就不完备,相当于4维空间到3维空间的投影)
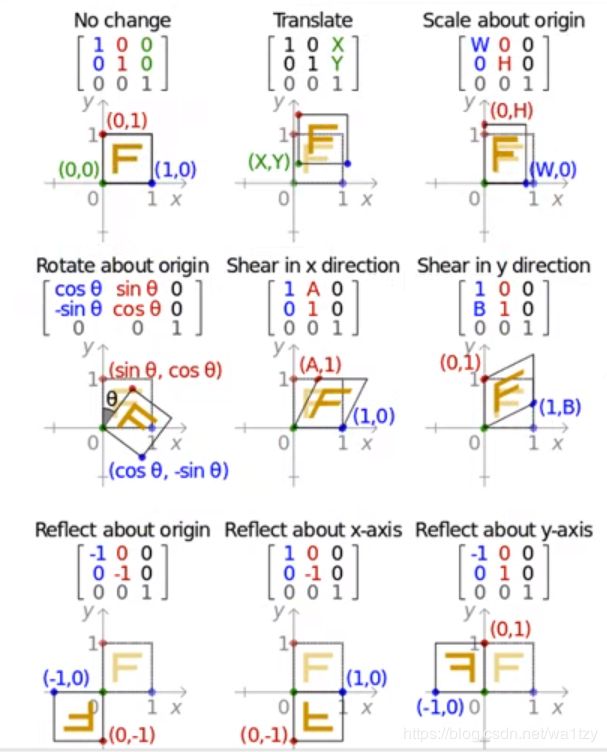
2.4 线性变换(特殊的仿射变换)
定义:线性变换是线性空间V到自身的映射通常称为V上的一个变换。
本质:改变坐标系这个空间,使点移动。
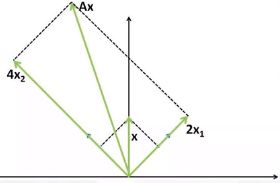
上图:一个向量x要变换到Ax上去,就给它乘以一个矩阵,做线性变换。
一个例子理解矩阵乘法:一个向量A与一个矩阵B做向量乘法,这就是一个线性变换的过程。矩阵B是一个方阵,且每一列两两不相关,则他们构成一个完备空间,B称为变换矩阵。得到一个新的向量,这个新的向量就是经过线性变换后的向量。
用图像理解,一张图片乘一个矩阵,就相当于给它做平移旋转的操作。
2.5 仿射变换
2.6 特征方程
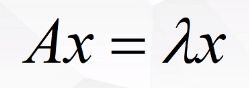
特征方程的理解:可以给等式两边同乘一个向量v,相当于向量v乘以一个变换矩阵A,得到的新向量再乘一个向量x,相当于在x方向上的投影 等价于 向量v做缩放,在向量x上的投影。(相当于线性变换矩阵A与缩放系数λ是等价的)
其中λ为缩放系数,也称为特征向量x的特征值。
代码实现求矩阵的特征向量与特征值:
import torch
a = torch.tensor([[1.,2.],[3.,4.]])
print(torch.eig(a))# 特征值
print(torch.eig(a,eigenvectors=True))# 特征向量
2.7 相似变换
一个轴求的是在x向量上的投影,如果多个轴就是矩阵P,P就是特征向量的集合。A和B就是相似矩阵。

如果P是正交阵(P的转置乘P=单位阵),得到的B就是斜对角阵,主对角线上的值就是A的特征值。
可以用此公式对角化一个矩阵。
2.8 奇异值分解(SVD)
奇异值的优点在于其不受限于原始矩阵A是否是方阵这个约束。但不是方阵可以用逆求得,不是方阵求出来的特征值叫做奇异值。
![]()
奇异值类似于下图:

将矩阵分解为用户对哪种类型的书和这本书更偏向于哪种特征和偏好的权重有多大,算到对一本新书的评价。
import numpy as np
a = np.array([[1,2],[3,4],[5,6]])
u,s,v = np.linalg.svd(a)
print(u)
print(s)# 特征值
print(v)
# 3x2 分解为 3x3 3x2 2x2 三个矩阵
SVD分解的应用:
降维(用前个非零奇异值对应的奇异向量表示矩阵的主要特征)、
压缩(要表示原来的大矩阵,我们只需要存三个较小的矩阵的即可)
2.9 谱范数
矩阵的特征值被称为谱
最大的特征值被称为矩阵的谱范数
用谱范数做归一化被称为谱范数归一化