图解深度学习-梯度下降法优化器可视化(SGD, Momentum,Adam, Adagrad and RMSProp)
图解深度学习-梯度下降法优化器可视化(SGD, Momentum,Adam, Adagrad and RMSProp
- 前言
- 定义了4个基本函数
- 机器学习原理
- 原始的梯度下降算法
- 带动量的梯度下降算法
- 带惯性的梯度下降算法
- Adagrad 自适应调整的梯度下降
- RMSProp
- Adam
前言
主要用了Jupyter Notebook的插件ipywidgets,可以进行交互,可以自己调整参数来看结果,用于理解来说非常好,今后也会继续用这些东西来做图解深度学习,主要代码来自链接,框架是他的,我主要做了点修改,更加方便理解和调试,可以动手改变学习率,训练次数等一些参数,可视化非常友好,当然也可以自己改变咯。提供下修改后的jupyter的文件链接
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import ticker, cm
import seaborn as sns
from ipywidgets import *
import math
#绘图元素比例 比较小
sns.set_context('paper', font_scale=2)
#设置显示中文字体
font = {'family' : 'SimHei',
# 'weight' : 'bold',
'size' : '15'}
plt.rc('font', **font) # 步骤一(设置字体的更多属性)
plt.rc('axes', unicode_minus=False) # 步骤二(解决坐标轴负数的负号显示问题)
定义了4个基本函数
- f_2d(x1, x2) 定义了一个简单的 2 维函数, f ( x 1 , x 2 ) = 0.5 x 1 2 + 2 x 2 2 f(x_1, x_2) = 0.5 x_1^2 + 2x_2^2 f(x1,x2)=0.5x12+2x22. 我们的目标是使用这个函数测试各种梯度下降算法,寻找极小值点。
- f_grad(x1, x2) 计算 f_2d() 沿两个方向的梯度
- train_2d() 函数使用给用的梯度下降算法,迭代N步,返回更新数据,即x1,x2的值
- plot_2d() 函数画出 f_2d 函数的等高图以及N步更新轨迹
- 学习率,迭代次数,变量初始值均可在空间中调试,方便观察
def f_2d(x1, x2):
'''优化的目标函数 有2个变量'''
return 0.5 * x1 ** 2 + 2 * x2 ** 2
def f_grad(x1, x2):
'''x1和x2的梯度'''
dfdx1 = x1
dfdx2 = 4 * x2
return dfdx1, dfdx2
def train_2d(trainer, lr,epoch=50,init_x1=-4,init_x2=-4):
"""自定义训练器:trainer
lr:学习率
epoch:轮次
init_x1:x1的初始值 便于观察
init_x2:x1的初始值
"""
x1, x2 = init_x1, init_x2
s_x1, s_x2 = 0, 0
res = [(x1, x2)]
for i in range(epoch):
x1, x2, s_x1, s_x2, lr = trainer(x1, x2, s_x1, s_x2, lr)
res.append((x1, x2))
return res
def plot_2d(res, figsize=(10, 8), title=None):
x1_, x2_ = zip(*res)
fig = plt.figure(figsize=figsize)
plt.plot([0], [0], 'r*', ms=15)
plt.text(0.0, 0.25, '最小值', color='k')
plt.plot(x1_[0], x2_[0], 'ro', ms=10)
plt.text(x1_[0]+0.2, x2_[0]-0.15, '起点', color='k')
plt.plot(x1_, x2_, '-o', color='r')
plt.plot(x1_[-1], x2_[-1], 'bo',ms=10)
plt.text(x1_[-1]+0.1, x2_[-1]-0.4, '终点', color='k')
x1 = np.linspace(-5,5, 100)
x2 = np.linspace(-5,5, 100)
x1, x2 = np.meshgrid(x1, x2)
#画出等高线区域,并用彩虹颜色填充,设置透明度
cp=plt.contourf(x1, x2, f_2d(x1, x2),alpha=0.75, cmap=cm.rainbow)
#画出等高线
C=plt.contour(x1, x2, f_2d(x1, x2),colors='black')
plt.clabel(C,inline=True,fontsize=15)
cbar = fig.colorbar(cp)
cbar.set_label('损失值')
plt.xlabel('x1')
plt.ylabel('x2')
plt.title(title)
plt.show()
x1,x2=res[-1]
loss=f_2d(x1,x2)
print('最小损失值:',loss,'x1:',x1,' x2:',x2)
机器学习原理
机器学习是一种新的编程模式。这种模式先假设任何输入 x 与输出 y 之间存在连续几何变换,
其函数形式可用 y = f ( x , θ ) y= f(x, \theta) y=f(x,θ) 表示。其中 θ \theta θ 是函数参数,初始化为随机数。
注意,初始化过程并不任意,这里有一篇很好的文章讲参数初始化
deeplearning.ai。
机器学习通过逐步微调函数参数 θ \theta θ的方式,试图最小化模型预言 y ^ \hat{y} y^ 与真实标签 y y y的差别。
此差别最简单的数学表达式是 MAE 或者 MSE,即
L ( θ ) = ∣ y ^ − y ∣ L(\theta) = |\hat{y} - y| L(θ)=∣y^−y∣
或
L ( θ ) = ∣ y ^ − y ∣ 2 L(\theta) = |\hat{y} - y|^2 L(θ)=∣y^−y∣2
为了最小化误差 L ( θ ) L(\theta) L(θ), 我们只需要计算误差对参数 θ \theta θ 的梯度,通过链式规则,
将误差反向传递到 θ \theta θ, 并使用梯度下降,更新 θ \theta θ 即可。
如果增加 θ \theta θ, 损失函数 L ( θ ) L(\theta) L(θ) 增大,那么损失函数对参数 θ \theta θ的梯度为正数, 即 ∇ θ L ( θ ) > 0 \nabla_{\theta} L(\theta) > 0 ∇θL(θ)>0,
只要将 θ \theta θ 减去一个正数 η ⋅ ∇ θ L ( θ ) \eta \cdot \nabla_{\theta} L(\theta) η⋅∇θL(θ) 即可使损失函数减小。
其中 η \eta η 是学习率 (Learning Rate, 简写为 lr),为一个很小的正数。
如果增加 θ \theta θ, 损失函数 L ( θ ) L(\theta) L(θ) 变小,那么 ∇ θ L ( θ ) < 0 \nabla_{\theta} L(\theta) < 0 ∇θL(θ)<0,
将 θ \theta θ 减去一个负数 η ⋅ ∇ θ L \eta \cdot \nabla_{\theta} L η⋅∇θL 同样可使损失函数减小。
你发现无论梯度是正是负,只要将参数减去学习率乘以梯度,总可以将损失降低。
这就是梯度下降的原理!
接下来会以交互式可视化的方式,展示几种最常用的梯度下降算法。
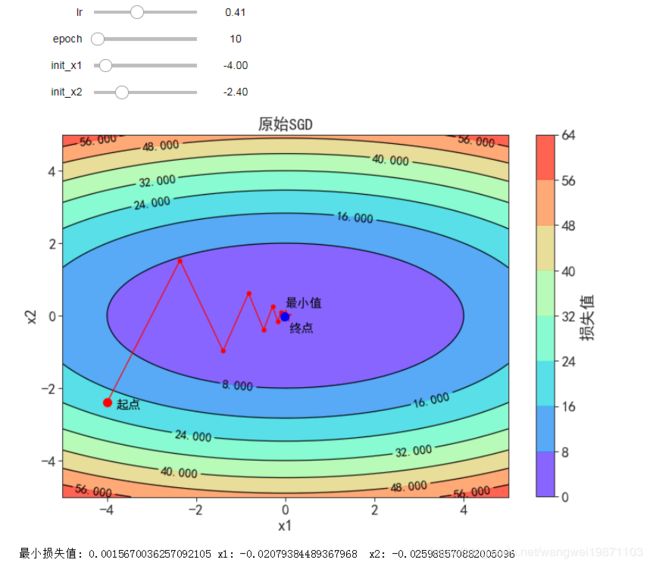
原始的梯度下降算法
θ = θ − η ⋅ ∇ θ L ( θ ) \theta = \theta - \eta \cdot \nabla_{\theta} L(\theta) θ=θ−η⋅∇θL(θ)
#最原始的梯度下降法
def sgd(x1, x2, s1, s2, lr):
dfdx1, dfdx2 = f_grad(x1, x2)
return (x1 - lr * dfdx1, x2 - lr * dfdx2, 0, 0, lr)
#定义了4个变量控件,可以随时调节,查看效果 (最小值,最大值,步长)
@interact(lr=(0, 1, 0.001),epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1),continuous_update=False)
def visualize_gradient_descent(lr=0.05,epoch=50,init_x1=-4,init_x2=-2.4):
res = train_2d(sgd, lr,epoch,init_x1,init_x2)
plot_2d(res,(12,8), title='原始SGD')
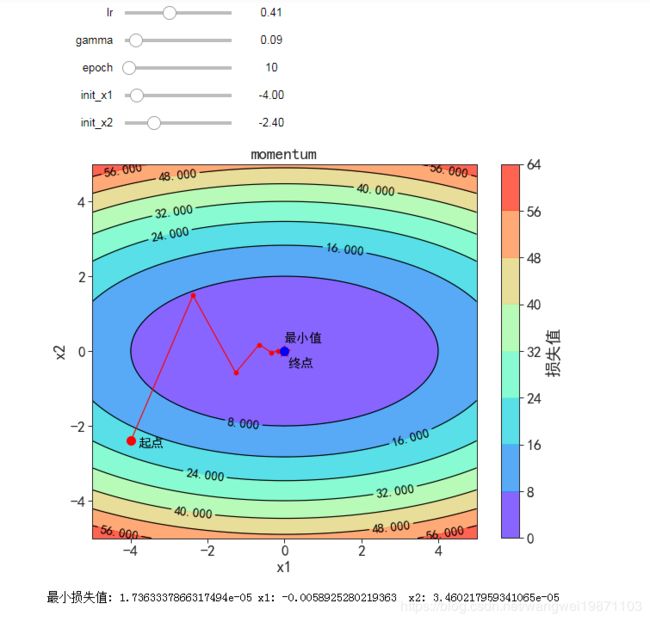
带动量的梯度下降算法
v t = γ v t − 1 + η ⋅ ∇ θ L ( θ ) v_t = \gamma v_{t-1} + \eta \cdot \nabla_{\theta} L(\theta) vt=γvt−1+η⋅∇θL(θ)
θ = θ − v t \theta = \theta - v_t θ=θ−vt
可见下图。对以前的梯度做了指数加权平均,不会像原始的那样直接折线那么厉害,因为有之前速度影响,所以瞬间就折,而是会再向原来那个方向前进一段距离,也可以理解为对原始梯度做了一个平滑,然后再用来做梯度下降
@interact(lr=(0, 0.99, 0.001), gamma=(0, 0.99, 0.001),continuous_update=False,
epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1))
def visualize_sgd_momentum(lr=0.1, gamma=0.1,epoch=10,init_x1=-4,init_x2=-2.4):
'''lr: learning rate
gamma: parameter for momentum sgd
每次都会根据上一次的动量来进行更新
'''
def momentum(x1, x2, v1, v2, lr):
dfdx1, dfdx2 = f_grad(x1, x2)
v1 = gamma * v1 + lr * dfdx1
v2 = gamma * v2 + lr * dfdx2
x1 = x1 - v1
x2 = x2 - v2
return (x1, x2, v1, v2, lr)
res = train_2d(momentum, lr,epoch,init_x1,init_x2)
plot_2d(res, title='momentum')
带惯性的梯度下降算法
v t = γ v t − 1 + ( 1 − γ ) ⋅ ∇ θ L ( θ ) v_t = \gamma v_{t-1} + (1 - \gamma) \cdot \nabla_{\theta} L(\theta) vt=γvt−1+(1−γ)⋅∇θL(θ)
θ = θ − η v t \theta = \theta - \eta v_t θ=θ−ηvt
@interact(lr=(0, 0.99, 0.01), gamma=(0, 0.99, 0.01),
continuous_update=False,epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1))
def visualize_sgd_inertia(lr=0.1, gamma=0.1,epoch=10,init_x1=-4,init_x2=-2.4):
'''lr: learning rate
gamma: parameter for inertia sgd'''
def inertia(x1, x2, v1, v2, lr):
dfdx1, dfdx2 = f_grad(x1, x2)
v1 = gamma * v1 + (1 - gamma) * dfdx1
v2 = gamma * v2 + (1 - gamma) * dfdx2
x1 = x1 - lr * v1
x2 = x2 - lr * v2
return (x1, x2, v1, v2, lr)
res = train_2d(inertia, lr,epoch,init_x1,init_x2)
plot_2d(res, title='inertia')

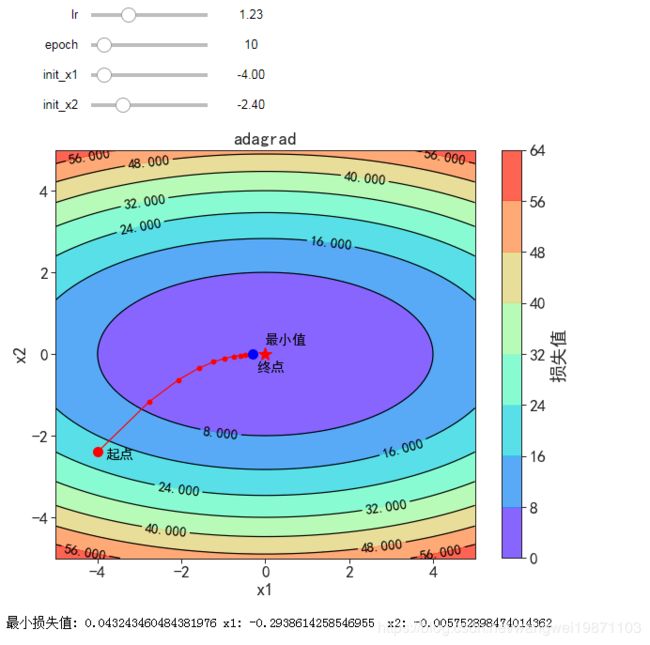
Adagrad 自适应调整的梯度下降
g t = ∇ θ L ( θ ) g_t = \nabla_{\theta} L(\theta) gt=∇θL(θ)
G = ∑ t g t 2 G = \sum_{t} g_t^2 G=t∑gt2
θ = θ − η G + ϵ ⋅ g t \theta = \theta - \frac{\eta}{\sqrt{G + \epsilon}} \cdot g_t θ=θ−G+ϵη⋅gt
可以自动调节学习率,但是下降的太快,学习率很小,可能导致后期学不到东西了
此方法也经常用于参数未标准化时,提供不通的学习率,以便于快速到达最小点
@interact(lr=(0, 4, 0.01),
continuous_update=False,epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1))
def visualize_adagrad(lr=0.1,epoch=10,init_x1=-4,init_x2=-2.4):
'''lr: learning rate'''
def adagrad_2d(x1, x2, s1, s2, lr):
g1, g2 = f_grad(x1, x2)
eps = 1e-6
s1 += g1 ** 2
s2 += g2 ** 2
x1 -= lr / math.sqrt(s1 + eps) * g1
x2 -= lr / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2, lr
res = train_2d(adagrad_2d, lr,epoch,init_x1,init_x2)
plot_2d(res, title='Adagrad')
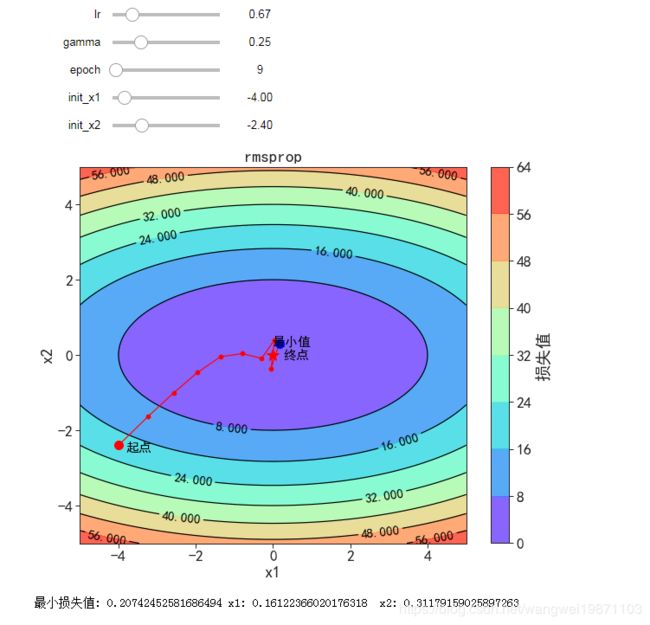
RMSProp
g = ∇ θ L ( θ ) g = \nabla_{\theta} L(\theta) g=∇θL(θ)
E [ g 2 ] = γ E [ g 2 ] + ( 1 − γ ) g 2 E\left[g^2\right] = \gamma E\left[g^2\right] + (1-\gamma) g^2 E[g2]=γE[g2]+(1−γ)g2
θ = θ − η E [ g 2 ] + ϵ ⋅ g \theta = \theta - \frac{\eta}{\sqrt{E\left[g^2\right] + \epsilon}} \cdot g θ=θ−E[g2]+ϵη⋅g
对Adagrad做了相应修改,让学习率不会下降了太快导致后期学不到东西,相当于做了归一化,调整不同参数的步长,加快收敛速度
@interact(lr=(0, 4, 0.001),
gamma=(0, 0.99, 0.001),
continuous_update=False,epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1))
def visualize_rmsprop(lr=0.1, gamma=0.9,epoch=50,init_x1=-4,init_x2=-4):
'''lr: learning rate,
gamma: momentum'''
def rmsprop_2d(x1, x2, s1, s2, lr):
eps = 1e-6
g1, g2 = f_grad(x1, x2)
s1 = gamma * s1 + (1 - gamma) * g1 ** 2
s2 = gamma * s2 + (1 - gamma) * g2 ** 2
x1 -= lr / math.sqrt(s1 + eps) * g1
x2 -= lr / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2, lr
res = train_2d(rmsprop_2d, lr,epoch,init_x1,init_x2)
plot_2d(res, title='RMSProp')
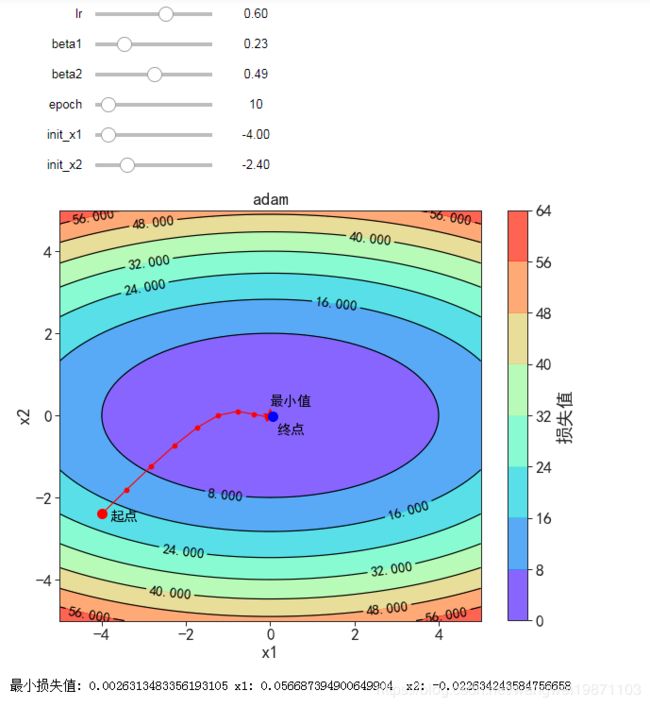
Adam
g = ∇ θ L ( θ ) g = \nabla_{\theta} L(\theta) g=∇θL(θ)
m = β 1 m + ( 1 − β 1 ) g m = \beta_1 m + (1 - \beta_1) g m=β1m+(1−β1)g
n = β 2 n + ( 1 − β 2 ) g 2 n = \beta_2 n + (1 - \beta_2) g^2 n=β2n+(1−β2)g2
m ^ = m ( 1 − β 1 t ) \hat{m} = \frac{m}{(1 - \beta_1^t)} m^=(1−β1t)m
n ^ = n ( 1 − β 2 t ) \hat{n} = \frac{n}{(1 - \beta_2^t)} n^=(1−β2t)n
θ = θ − η n ^ + ϵ m ^ \theta = \theta - \frac{\eta}{\sqrt{\hat{n}} + \epsilon} \hat{m} θ=θ−n^+ϵηm^
结合Momentum和RMSProp的2个特征,即做指数加权平均,又做归一化
@interact(lr=(0, 1, 0.001),
beta1=(0, 0.999, 0.001),
beta2=(0, 0.999, 0.001),
continuous_update=False,epoch=(0,100,1),init_x1=(-5,5,0.1),init_x2=(-5,5,0.1))
def visualize_adam(lr=0.1, beta1=0.9, beta2=0.999,epoch=10,init_x1=-4,init_x2=-2.4):
'''lr: learning rate
beta1: parameter for E(g)
beta2: parameter for E(g^2)
'''
def Deltax(m, n, g, t):
eps = 1.0E-6
m = beta1 * m + (1 - beta1) * g
n = beta2 * n + (1 - beta2) * g*g
m_hat = m / (1 - beta1**t)
n_hat = n / (1 - beta2**t)
dx = lr * m_hat / (math.sqrt(n_hat) + eps)
return m, n, dx
def adam_2d(x1, x2, m1, n1, m2, n2, lr, t):
'''m1, m2: E(g1), E(g2)
n1, n2: E(g1^2), E(g2^2) where E() is expectation
lr: learning rate
t: time step'''
eps = 1e-6
g1, g2 = f_grad(x1, x2)
m1, n1, dx1 = Deltax(m1, n1, g1, t)
m2, n2, dx2 = Deltax(m2, n2, g2, t)
x1 -= dx1
x2 -= dx2
return x1, x2, m1, n1, m2, n2, lr
def train_adam(trainer, lr,epoch=10,init_x1=-4,init_x2=-4):
"""Train a 2d object function with a customized trainer"""
x1, x2 = init_x1,init_x2
m1, n1, m2, n2 = 0, 0, 0, 0
res = [(x1, x2)]
for i in range(epoch):
x1, x2, m1, n1, m2, n2, lr = trainer(x1, x2, m1, n1, m2, n2, lr, i+1)
res.append((x1, x2))
return res
res = train_adam(adam_2d, lr,epoch,init_x1,init_x2)
plot_2d(res, title='adam')
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。