Basic Paxos原理及推导
文章目录
- 引言
- 问题的提出
- 提案的选定
- 初步尝试 - Single Acceptor
- 多个acceptor
- 推导
- 一个acceptor必须批准它收到的第一个提案
- 一个acceptor必须能够批准不止一个提案
- 有序提案的组成
- 提案value的约束
- proposer生成提案
- acceptor批准提案
- 算法陈述
- learner学习被选定的value
- 选取主Proposer保证算法的活性
- 参考
引言
Paxos是啥,引用大牛Leslie Lamport的论文《Paxos Make Simple》的一句话:
In fact, it is among the simplest and most obvious of distributed algorithms.
At its heart is a consensus algorithm—the “synod” algorithm of “The part-time parliament”.
因此,Basic Paxos是一个共识(consensus)算法,用于解决分布式共识问题。其目的是在一个分布式系统中如何就某一个值(proposal) 达成一致。
问题的提出
在常见的分布式系统中,总会发生诸如机器宕机或网络异常(包括消息的延迟、丢失、重复、乱序,还有网络分区)等情况。Paxos算法需要解决的问题就是如何在一个可能发生上述异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致,并且保证不论发生以上任何异常,都不会破坏整个系统的一致性。
具体地,对于分布式共识问题,很多进程提出(propose)不同的提案(Proposal,最终要达成一致的value就在提案里),共识算法保证最终只有其中一个值被选定,Safety表述如下:
- 只有被提出(propose)的值才可能被最终选定(chosen)。
- 只有一个值会被选定(chosen),不会挑选第二个值,也不会改变其值。
- 进程只会获知到已经确认被选定(chosen)的值。
Paxos以这几条约束作为出发点进行设计,只要算法最终满足这几点,正确性就不需要证明了。
Paxos算法中共分为三种角色:
- proposer:可以提出提案(Proposal)。
- acceptor:可以接受proposer提出的提案。一旦接受提案,提案里面的 value 值就被选定了。
- learner:acceptor 告诉 learner 哪个提案被选定了(chosen),那么 learner 就学习这个被选择的 value。
在具体的实现中,一个进程可能同时充当多种角色。比如一个进程可能既是Proposer又是Acceptor又是Learner。实际上,通常实现中每个进程都同时扮演这三个角色。这些角色之间在异步的非拜占庭场景下(the customary asynchronous, non-Byzantine model),通过发送消息的方式来相互通信。
提案的选定
初步尝试 - Single Acceptor
假设只有一个acceptor(多个proposer),只要acceptor接受它收到的第一个提案,则该提案被选定,该提案里的value就是被选定的value。这样就保证只有一个value会被选定。
但是一个共识模块最关键的特性是:对于一个系统来说,只要有大多数的服务器是可用的,那么它就可以提供所有的服务。所以如果我们有一个 5 台服务器的集群,那么它可以在仅有 3 台服务器可用的情况下,仍然能正常提供服务。所以我们可以容忍 5 台其中的 2 台宕掉。通常情况下,集群的大小会是一个奇数,如 3、5 或 7 。
因此在该方案下,如果这个唯一的acceptor宕机GG了,那么系统就废了,不满足上述要求。So,必须要有多个acceptor,通常是一个奇数,如 3 、5 或 7 。如果一个值被大多数 接受者acceptors选定,那么我们认为这个值被认为是选定的。这样即使在少数服务器崩溃的情况下,还有多数服务器可以接受值。仲裁(quorum)方法可以让我们在某些服务器崩溃后,仍然能保证集群能正常工作。
多个acceptor
现在问题变成了:如何在多个proposer和多个acceptor的情况下选定一个value。
proposers向acceptors提出proposal,为了保证最多只有一个值被选定(chosen),proposal必须被超过一半的acceptors(majority)所接受(accept),且每个acceptor只能接受一个值。由于任意两个majority的acceptors至少有一个公共 成员,因此如果每一个acceptors只能批准一个提案的话,那么就能保证只有一个提案被选定了。
推导
一个acceptor必须批准它收到的第一个提案
因为消息是有可能丢失的,因此,当只有一个value被提出的时候,acceptor应该接受它,这暗示了如下的需求:
P1. An acceptor must accept the first proposal that it receives.
一个acceptor必须批准它收到的第一个提案。
但单单这个会导致其他问题:如果有多个提案被不同的proposer同时提出,这可能会导致虽然每个acceptor都批准了它收到的第一个提案,但是没有一个提案是由大部分acceptor批准的,如下图。
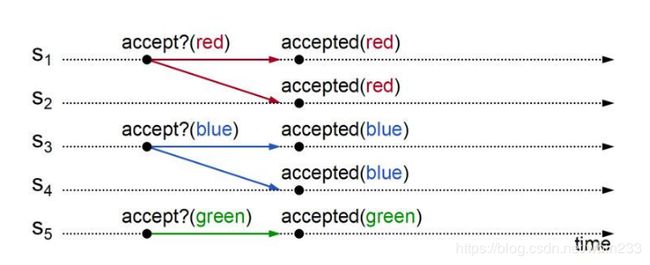
例如,我们假设每个acceptor都接受它第一次收到的值,然后让多数票的值获胜,如上图我们可以看到,也存在没有任何值是大多数的情况。服务器 S1 和 S2 接受的值是 red ,服务器 S3 和 S4 接受的值是 blue ,服务器 S5 接受的值是 green 。没有任何值在五个服务器中的三个达成一致的。这也就意味着acceptors有时需要改变他们的想法,在某些情况下,它们接受了一个值后需要接受另外一个不同的值。也就是说,几乎无法在一轮投票下就能达成一致,往往需要进行几轮的投票才能达到一致。这里接受(accepted)并不代表被选定(chosen),一个值只有在集群大多数节点接受之后才被认为是选定的。
一个acceptor必须能够批准不止一个提案
但走到这里又会造成另外的问题,导致违背了Safety里的要求:
- 例如,S1 提议一个值 red ,让其他的服务器接受,这样服务器 S1、S2、S3 接受了这个值,那么现在被选定的值是 red ,因为它已经被多数服务器(3/5)选择。不过随后服务器 S5 来了,提议了一个不同的值 blue ,然后让acceptors接受这个值(服务器 S3、S4、S5 接受了这个值),因为它们会接受任何传递给它们的值,那么此时服务器 S3 接受的值是 blue ,尽管它之前接受的值是 red 。所以现在我们选择的值是 blue(它也被多数服务器(3/5)选择) 。这样就违背了我们所定义的基础的安全属性Safety的要求 — 我们只能选定一个值。
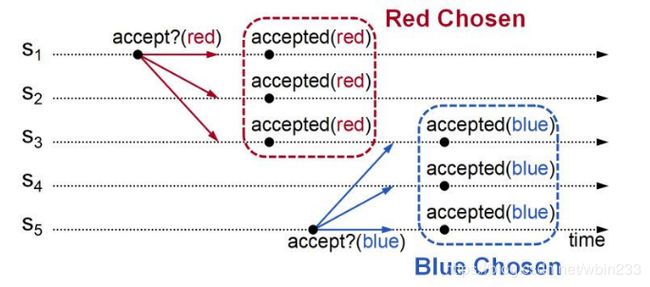
这个问题的解决办法是,每个proposer提出新的提案前,这里是服务器 S5,此时如果已经有选定的值,那么它就必须放弃它自己的值,并提议当前已经选定的值,所以在这种规约下,在服务器 S5 向其他服务器发出请求要求接受它的值之前,它就需要查看集群里的其他服务器,看是否有其他值的存在,如果已经有其他选定的值,服务器 S5 就需要放弃它自己的值,然后使用 red 来代替,这样最终就可以使 red 成为选定的值,我们以第二次选择为终结点,但是最终选择的值是第一次选定的那个值(red)。这也就说,我们需要使用一个两段协议(two-phase protocol)。 - 不幸地是,单单这样还是不够的。。。如下图:
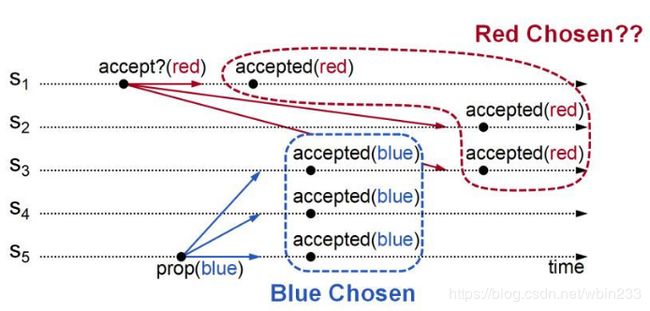
例如,服务器 S1 提议了一个值 red 。它首先检查其他的服务器,其他的服务器还没有接受任何值,所以它开始向其他服务器发起请求,希望它们能接受自己的值 red 。不过同时,在其他服务器真正应答之前,另外一个服务器 S5 又提议了另一个值 blue 。这时它也发现还没有其他服务器确定了选定值,那么它就开始发送消息,希望其他服务器能选择 blue 。然后,如果这个请求先结束,服务器 S3、S4、S5 接受并选定 blue ,但与此同时,red 值的服务器仍然处于运行中,因为acceptors会接受多个值,所以最终可以看到,会发生仲裁,最终 red 值会被选定,这样就违背了基本安全的属性要求。这个问题的解决办法是,一旦我们已经选定了值,任何其他的竞争性提议必须被放弃。 在上面的例子中,我们就需要服务器 S3 在已经接受了值 blue 后,拒绝对 red 值的接受请求。要想这么做,我们会给提议安排顺序,新的提议优先于所有提议。也就是说 blue 的请求更晚,它会截断 red 请求,这样请求就不会以选择竞争值为结束。
所以总结如下:我们需要一个两段协议(two-phase protocol)。在发起请求前先进行检查,然后我们需要请求有序,这样就能消除老的请求。
有序提案的组成
显然,既要满足Safety里只能选定一个值的要求,又要满足一个acceptor必须能够批准不止一个提案,且要求提案有序,那么【提案=value】已经不能满足需求了,于是需要给每个提案再加上一个提案编号,表示提案被提出的顺序。令【提案=提案编号+value】,这样就能满足上述几个条件啦。proposer生成全局唯一且递增的提案 ID(Proposalid,例如以高位时间戳 + 低位机器 IP 可以保证唯一性和递增性)。
提案value的约束
通过上述经历,我们虽然允许多个提案被选定,但同时必须要保证所有被选定的提案都具有相同的value值,则需要提案value进行约束,如下:
P2. If a proposal with value v is chosen, then every higher-numbered proposal that is chosen has value v.
如果编号为M0、value值为V0的提案(即[M0,V0])被选定了,那么所有比编号M0更高的,且被选定的提案,其value值必须也是V0。
因为提案的编号是全序的,P2就满足了Safety里只能选定一个值的要求。同时,一个提案要被选定(chosen),其首先必须被至少一个acceptor批准,因此可以满足如下条件进而来满足P2.
P2a. If a proposal with value v is chosen, then every higher-numbered proposal accepted by any acceptor has value v.
如果编号为M0、value值为V0的提案(即[M0,V0])被选定了,那么所有比编号M0更高的,且被Acceptor批准的提案,其value值必须也是V0。
由于通信是异步的,一个提案可能会在某个acceptor还未收到任何提案时就被选定了,如下图:
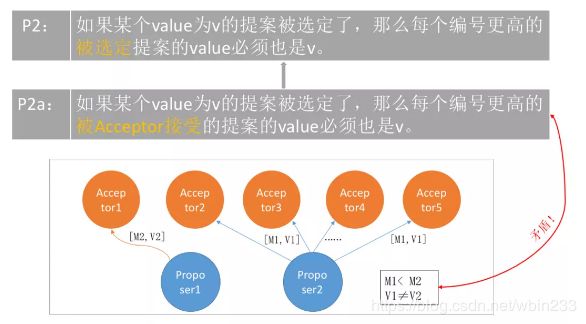
假设有 5 个 Acceptor。proposer2 提出 [M1,V1]的提案,acceptor2 ~ 5(半数以上)均接受了该提案,于是对于 acceptor2~5 和 proposer2 来讲,它们都认为 V1 被选定。acceptor1 刚刚从 宕机状态 恢复过来(之前 acceptor1 没有收到过任何提案),此时 Proposer1 向 Acceptor1 发送了 [M2,V2] 的提案 (V2≠V1且M2>M1)。对于 acceptor1 来讲,这是它收到的 第一个提案。根据 P1(一个 acceptor 必须接受它收到的第一个提案),acceptor1 必须接受该提案,但又与P2a矛盾。因此如果要同时满足P1和P2a,需要对P2a进行如下强化:
P2b. If a proposal with value v is chosen, then every higher-numbered proposal issued by any proposer has value v.
如果编号为M0、value值为V0的提案(即[M0,V0])被选定了,那么之后任何proposer产生的编号更高的提案,其value值必须也是V0。
因为一个提案必须在被proposer提出后才能被acceptor批准,因此P2b包含了P2a,进而包含了P2。
更进一步地,为了满足P2b,还需要保持下面P2c的不变性。
P2c. For any v and n, if a proposal with value v and number n is issued, then there is a set S consisting of a majority of acceptors such that either (a) no acceptor in S has accepted any proposal numbered less than n, or (b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the acceptors in S.
对于任意的Mn和Vn,如果提案[Mn,Vn]被提出,那么肯定存在一个由半数以上的acceptor组成的集合S,满足以下条件中的任意一个。
- S中不存在任何批准过编号小于Mn的提案的acceptor。
- 选取S中所有acceptor批准的编号小于Mn的提案,其中编号最大的那个提案其value值是Vn。
至此,只需要通过保持P2c,就能够满足P2b了,而满足P2b,就能够满足P2了。通过P1和P2来保证一致性。
proposer生成提案
通过上述P2及一系列扩展,可以自然地引出如下的提案生成算法。
- proposer选择一个新的提案编号Mn,然后向某个acceptor集合(至少需满足majority)发送请求,要求该集合中的acceptor做出如下回应:
- 保证不再批准任何编号小于Mn的提案。
- 如果acceptor已经批准过任何提案,那么其就向proposer反馈当前该acceptor已经批准的编号小于Mn但为最大编号的那个提案的值。
将该请求成为编号Mn的提案的prepare请求。
- 如果proposer收到了来自半数以上(majority)的acceptor的反馈,那么有两种情况:
- 可以产生编号为Mn、value值为Vn的提案,其中Vn是所有响应中编号最大的提案的value值。
- 返回的所有反馈中,都没有批准过任何提案,即响应中不包含任何的提案,那么此时Vn值就可以由proposer任意选择。
在确定提案之后,proposer就会将该提案再次发送给某个acceptor集合(同样需要满足majority),并期望获得它们的批准,该请求称之为accept请求。需要注意的是,这里的acceptor集合不一定是之前相应prepare请求的acceptor集合,只需要满足majority即可,因为任意两个半数以上的acceptor集合,必定包含至少一个公共acceptor。
acceptor批准提案
根据proposer的生成提案流程,一个acceptor可能会收到来自proposer的两种请求,分别是prepare请求和accept请求。Paxos算法允许acceptor可以忽略任何请求(包括Prepare请求和Accept请求)而不用担心破坏算法的安全性,对acceptor接受提案给出如下约束:
P1a. An acceptor can accept a proposal numbered n iff it has not responded
to a prepare request having a number greater than n.
一个acceptor只要尚未相应过任何编号大于Mn的prepare请求,那么它就可以接受这个编号为Mn的提案。
因此acceptor批准提案流程为:
- 接收到一个编号为Mn的prepare请求:
- 编号Mn大于该acceptor已经响应的所有prepare请求的编号,那么它就会将它已经批准过的最大编号的提案作为响应反馈给proposer,同时该acceptor承诺不会再批准任何编号小于Mn的提案。
- 反之,由于该acceptor已经对编号大于Mn的prepare请求做出了响应,那么此时该acceptor肯定不会批准编号Mn的提案,因此可以选择忽略该prepare请求,也可以发送错误码让proposer更快地感知到结果。
- 接收到 [Mn,Vn] 提案的accept请求:
只要该acceptor尚未对编号大于Mn的prepare请求做出响应,它就可以通过这个提案。
算法陈述
把上述proposer生成提案以及对应的acceptor批准提案合起来,就是Basic Paxos算法了。以一张图作为总结吧。
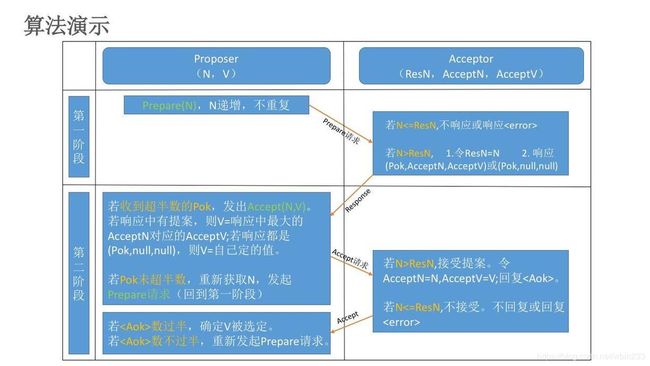
Prepare阶段:
- Proposer选择proposal number n,并向acceptors发送Prepare(n)消息
- Acceptor收到Prepare(n):
if n > minProposal then minProposal = n ; return (acceptedProposal, acceptedValue)
else return error;
Accept阶段:
- 如果Proposer收到了超过多数派acceptors对于Prepare(n)的回复,如果回复中有包含acceptedValue,则选择acceptedProposal值最大的作为value, 否则Proposer可以自行选择value。Proposer向某个acceptor集合(满足majority)发出Accept(n, value)消息。
- Acceptor收到Accept(n, value):if n >= minProposal then acceptedProposal = n; acceptedValue = value,并回复AcceptAck(n)
- Proposer收到来自多数派acceptors的AcceptAck消息,value已达成决议(chosen)
显然,为了保证算法在容灾(节点故障重启)场景下的正确性,acceptor上需要持久化(minProposal、acceptedProposal 、acceptedValue )。
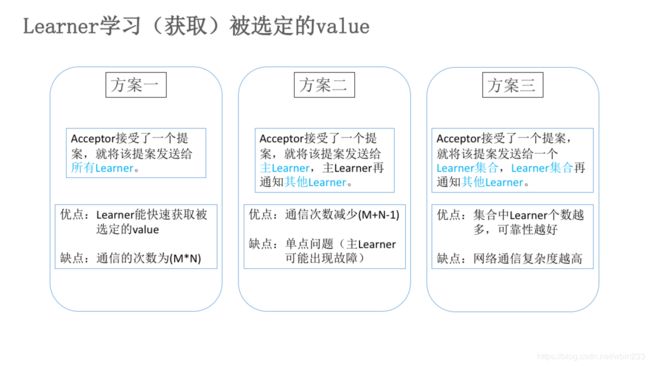
learner学习被选定的value
大体上有三种方案:
- 一旦acceptor批准了一个提案,就将该提案发送给所有的learner。
- 一旦acceptor批准了一个提案,就将该提案发送给一个特定的learner(主learner),再由其负责通知其他的learner。
- 一旦acceptor批准了一个提案,就将该提案发送给一个特定的learner集合,再由它们通知其余的learner。
选取主Proposer保证算法的活性
竞争提议可能会导致死锁。
假设有两个proposer依次提出编号递增的提案,最终谁都不服谁,会陷入死循环,没有提案被选定,从而无法保证算法的活性。
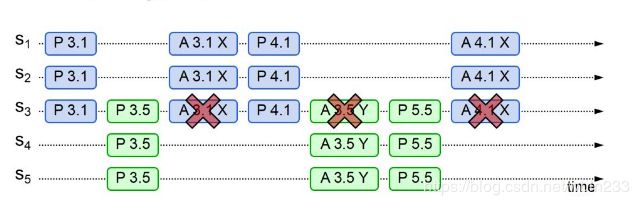
如图,假设服务器 S1 成功接收到请求,并处于准备阶段(P 3.1)。在接受值 X 之前(A 3.1 X),另外一个服务器 S5 正处于它的准备阶段(P 3.5),这会阻止前序值的接受(A 3.1 X)。然后 S1 会重新选择提议序号并再次开始提议过程(P 4.1),假设它正进入了第二轮的准备阶段,在接受值之前,服务器 S5 正试图完成接受值的选定 Y (A 3.5 Y),不过此时因为(P 4.1)的序号高于(A 3.5 Y),所以它阻止了(A 3.5 Y)的接受,这样 S5 的提议就失败了,然后 S5 又重新开始下一轮的提议,如此往复,这个过程会无限循环下去。
为了不发生死锁,Paxos 需要以某种补充机制来保证它可以正确运行。
- 一个方式是让服务器等待一会,如果发生接受失败的情况,必须返回重新开始。在重新开始之前等待一会,让提议能有机会完成。可以让集群下服务器随机的延迟,从而避免所有服务器都处于相同的等待时间下。
- 也可以选择一个主proposer(distinguished proposer),并规定只有主proposer才能提出议案。这样一来,只要主proposer和过半的acceptor能够正常进行网络通信,那么但凡主proposer提出一个编号更高的提案,该提案终将会被批准。从而保证了算法的活性。
以上。
后续有机会再把Multi-Paxos以及相关开源实现PhxPaxos源码分析补上呢,有点懒的写呢。

参考
- Lamport L. Paxos made simple[J]. ACM Sigact News, 2001, 32(4): 18-25.
- Lamport L. The part-time parliament[J]. ACM Transactions on Computer Systems (TOCS), 1998, 16(2): 133-169.
- 《从Paxos到ZooKeeper》
- 2013 Raft user study
- 分布式系列文章——Paxos算法原理与推导