Spring Boot整合Elasticsearch

Elasticsearch是一个全文搜索引擎,专门用于处理大型数据集。根据描述,自然而然使用它来存储和搜索应用程序日志。与Logstash和Kibana一起,它是强大的解决方案Elastic Stack的一部分,我之前的一些文章中已经对此进行了描述。
保留应用程序日志不是Elasticsearch的唯一使用场景。它通常用作应用程序的辅助数据库,是一个主关系数据库。如果您必须对大型数据集执行全文搜索或仅存储应用程序不再修改的许多历史记录,这个方法尤其有用。当然,该方法也有优缺点。当您使用包含相同数据的两个不同数据源时,您必须首先考虑同步。你有几个选择:根据关系数据库供应商,您可以利用二进制或事务日志,其中包含SQL更新的历史记录。这种方法需要一些中间件来读取日志,然后将数据放入Elasticsearch。您始终可以将整个职责移至数据库端(触发器)或Elasticsearch端(JDBC插件)。
无论您如何将数据导入Elasticsearch,都必须考虑另一个问题:数据结构。关系数据库中的数据可能分布在几个表之间。如果您想利用Elasticsearch,您应该将其存储为单一类型。它会强制您保留冗余数据,这会导致更大的磁盘空间使用量。当然,如果Elasticsearch查询比等效的关系数据库中的查询能更快,那么这种影响是可以接受的。
好的,在长时间的介绍之后继续这个例子。 Spring Boot提供了一种通过Spring Data存储库与Elasticsearch进行交互的简便方法。
1 启用Elasticsearch支持
按照Spring Boot的惯例,我们不必在上下文中提供任何bean来启用对Elasticsearch的支持。我们只需要在pom.xml中添加以下依赖项:
-
-
org.springframework.boot -
spring-boot-starter-data-elasticsearch -
默认情况下,应用程序尝试在localhost上与Elasticsearch连接。如果我们使用另一个目标URL,我们需要在配置设置中覆盖它。这是我们的application.yml文件的片段,它覆盖了默认的集群名称和地址,以及在Docker容器上启动的Elasticsearch的地址:
-
spring: -
data: -
elasticsearch: -
cluster-name: docker-cluster -
cluster-nodes: 192.168.99.100:9300
应用程序可以通过Spring Boot Actuator health端点监测Elasticsearch连接的运行状况。首先,您需要添加以下Maven依赖项:
-
-
org.springframework.boot -
spring-boot-starter-actuator -
默认情况下启用Healthcheck,并自动配置Elasticsearch检查。但是,这验证是通过Elasticsearch Rest API客户端执行的。在这种情况下,我们需要覆盖属性spring.elasticsearch.rest.uris-负责设置REST客户端使用的地址:
-
spring: -
elasticsearch: -
rest: -
uris: http://192.168.99.100:9200
2 运行 Elasticsearch
对于我们的测试,我们需要在开发模式下运行单节点Elasticsearch实例。像往常一样,我们将使用Docker容器。这是Docker容器启动并在9200和9300端口上公开的命令。
-
$ docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.6.2
3 构建Spring Data库
要启用Elasticsearch存储库,我们只需要使用@EnableElasticsearchRepositories注释主类或配置类:
-
@SpringBootApplication -
@EnableElasticsearchRepositories -
public class SampleApplication { ... }
下一步是创建扩展CrudRepository的存储库接口。它提供了一些基本操作,如save或findById。如果您想要一些额外的find方法,您应该在跟随Spring Data命名规范在接口内定义新方法。
-
public interface EmployeeRepository extends CrudRepository -
ListfindByOrganizationName(String name); -
ListfindByName(String name); -
}
4 构建文档
我们的实体关系结构平铺为包含相关对象(组织,部门)的单个Employee对象。您可以将此方法与在RDBMS中为相关表组创建视图进行比较。在Spring Data Elasticsearch命名法中,单个对象存储为文档。因此,需要使用@Document注释对象。您还应该为Elasticsearch设置目标索引的名称,类型和ID。可以使用@Field注解配置其他映射。
-
@Document(indexName = "sample", type = "employee") -
public class Employee { -
@Id -
private Long id; -
@Field(type = FieldType.Object) -
private Organization organization; -
@Field(type = FieldType.Object) -
private Department department; -
private String name; -
private int age; -
private String position; -
// Getters and Setters ... -
}
5 初始化数据
正如在前言中提到的,您可能决定使用Elasticsearch的主要原因是需要处理大数据。因此,最好使用大量文档填充我们的测试Elasticsearch节点。如果您想在一步就插入许多文档,那么您一定要使用Bulk API。bulk API使得在单个API调用中执行许多索引/删除操作成为可能。这可以大大提高索引速度。可以使用Spring Data ElasticsearchTemplate bean执行批量操作。它在Spring Boot上也可以自动配置。 Template提供了bulkIndex方法,该方法将索引查询列表作为输入参数。这是在应用程序启动时插入样本测试数据的bean的实现:
-
public class SampleDataSet { -
private static final Logger LOGGER = LoggerFactory.getLogger(SampleDataSet.class); -
private static final String INDEX_NAME = "sample"; -
private static final String INDEX_TYPE = "employee"; -
@Autowired -
EmployeeRepository repository; -
@Autowired -
ElasticsearchTemplate template; -
@PostConstruct -
public void init() { -
for (int i = 0; i < 10000; i++) { -
bulk(i); -
} -
} -
public void bulk(int ii) { -
try { -
if (!template.indexExists(INDEX_NAME)) { -
template.createIndex(INDEX_NAME); -
} -
ObjectMapper mapper = new ObjectMapper(); -
Listqueries = new ArrayList<>(); -
Listemployees = employees(); -
for (Employee employee : employees) { -
IndexQuery indexQuery = new IndexQuery(); -
indexQuery.setId(employee.getId().toString()); -
indexQuery.setSource(mapper.writeValueAsString(employee)); -
indexQuery.setIndexName(INDEX_NAME); -
indexQuery.setType(INDEX_TYPE); -
queries.add(indexQuery); -
} -
if (queries.size() > 0) { -
template.bulkIndex(queries); -
} -
template.refresh(INDEX_NAME); -
LOGGER.info("BulkIndex completed: {}", ii); -
} catch (Exception e) { -
LOGGER.error("Error bulk index", e); -
} -
} -
// sample data set implementation ... -
}
如果您不需要在启动时插入数据,则可以通过将属性initial-import由enabled转变为false来禁用该过程。这是SampleDataSet bean的声明:
-
@Bean -
@ConditionalOnProperty("initial-import.enabled") -
public SampleDataSet dataSet() { -
return new SampleDataSet(); -
}
6 查看数据和运行查询
假设您已经启动了示例应用程序,负责扩充索引的bean没有被禁用,并且有足够的耐心等待几个小时,直到所有数据都插入到Elasticsearch节点中,现在它包含100M的员工类型文档。显示集群有关的一些信息是值得的。您可以使用Elasticsearch查询来执行此操作,也可以下载一个可用的GUI工具,例如ElasticHQ。碰巧的是,ElasticHQ也可以作为Docker容器使用。您必须执行以下命令才能启动ElasticHQ容器:
-
$ docker run -d --name elastichq -p 5000:5000 elastichq/elasticsearch-hq
启动ElasticHQ后,Web浏览器通过端口5000访问GUI。它的Web控制台提供有关集群,索引和允许执行查询的基本信息。您只需要输入Elasticsearch节点地址,您将被重定向到带有统计信息的主仪表盘。这是ElasticHQ的主仪表盘。

如您所见,我们有一个名为sample的索引,分为5个分片。这是Spring Data @Document提供的默认值,可以使用分片字段覆盖它。点击后我们可以导航到索引管理面板。您可以对索引执行某些操作例如清除缓存或刷新索引等。您还可以查看所有分片的统计信息。
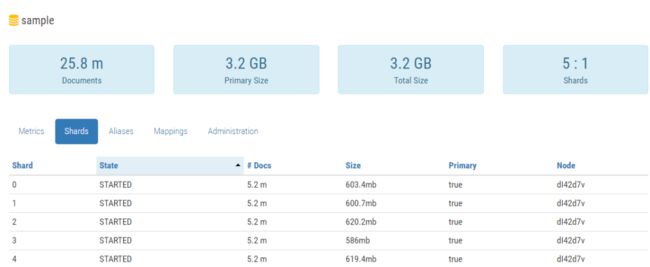
出于当前的测试目的,我有大约25M(约3GB的空间)Employee类型的文档。我们可以执行一些测试查询。我已经公开了两个用于搜索的端点:按员工姓名GET/employees/{name}和组织名称GET/employees / organization / {organizationName}。结果并不是压倒性的。我认为关系数据库使用相同数量的数据也可以获得相同的结果。

7 测试
好的,我们已经完成了开发并对大型数据集进行了一些手动测试。现在,是时候创建一些在构建时运行的集成测试了。我们可以使用允许在JUnit测试期间自动启动数据库的Docker容器的库 - Testcontainers。有关此库的更多信息,请参阅其站点https://www.testcontainers.org或我以前的一篇文章:使用Testcontainers Framework测试Spring与Vault和Postgres的集成。幸运的是,Testcontainers支持Elasticsearch。要在测试范围内启用它,首先需要在pom.xml中添加以下依赖项:
-
-
org.testcontainers -
elasticsearch -
1.11.1 -
test -
下一步是定义指向Elasticsearch容器的@ClassRule或@Rule bean。它在测试类之前或每个依赖使用的注释之前自动启动。公开的端口号是自动生成的,因此您需要将其设置为spring.data.elasticsearch.cluster-nodes属性的值。这是我们的JUnit集成测试的完整实现:
-
@RunWith(SpringRunner.class) -
@SpringBootTest -
@FixMethodOrder(MethodSorters.NAME_ASCENDING) -
public class EmployeeRepositoryTest { -
@ClassRule -
public static ElasticsearchContainer container = new ElasticsearchContainer(); -
@Autowired -
EmployeeRepository repository; -
@BeforeClass -
public static void before() { -
System.setProperty("spring.data.elasticsearch.cluster-nodes", container.getContainerIpAddress() + ":" + container.getMappedPort(9300)); -
} -
@Test -
public void testAdd() { -
Employee employee = new Employee(); -
employee.setId(1L); -
employee.setName("John Smith"); -
employee.setAge(33); -
employee.setPosition("Developer"); -
employee.setDepartment(new Department(1L, "TestD")); -
employee.setOrganization(new Organization(1L, "TestO", "Test Street No. 1")); -
employee = repository.save(employee); -
Assert.assertNotNull(employee); -
} -
@Test -
public void testFindAll() { -
Iterableemployees = repository.findAll(); -
Assert.assertTrue(employees.iterator().hasNext()); -
} -
@Test -
public void testFindByOrganization() { -
Listemployees = repository.findByOrganizationName("TestO"); -
Assert.assertTrue(employees.