本文记录使用BERT预训练模型,修改最顶层softmax层,微调几个epoch,进行文本分类任务。
BERT源码
首先BERT源码来自谷歌官方tensorflow版:https://github.com/google-research/bert
注意,这是tensorflow 1.x 版本的。
BERT预训练模型
预训练模型采用哈工大讯飞联合实验室推出的WWM(Whole Word Masking)全词覆盖预训练模型,主要考量是BERT对于中文模型来说,是按照字符进行切割,但是注意到BERT随机mask掉15%的词,这里是完全随机的,对于中文来说,很有可能一个词的某些字被mask掉了,比如说让我预测这样一句话:
原话: ”我今天早上去打羽毛球了,然后又去蒸了桑拿,感觉身心愉悦“
MASK:”我[MASK]天早上去打[MASK]毛球了,然后[MASK]去蒸了[MASK]拿,感觉身心[MASK]悦“
虽然说从统计学意义上来讲这样做依然可以学得其特征,但这样实际上破坏了中文特有的词结构,那么全词覆盖主要就是针对这个问题,提出一种机制保证在MASK的时候要么整个词都不MASK,要么MASK掉整个词。
WWM MASK:”我今天早上去打[MASK][MASK][MASK]了,然后又去蒸了[MASK][MASK],感觉身心愉悦“
例子可能举得不是很恰当,但大概是这个意思,可以参考这篇文章:
https://www.jiqizhixin.com/articles/2019-06-21-01
修改源码
首先看到下下来的项目结构:
可以看到run_classifier.py文件,这个是我们需要用的。另外,chinese开头的文件是我们的模型地址,data文件是我们的数据地址,这个每个人可以自己设置。
在run_classifier.py文件中,有一个基类DataProcessor类,这个是我们需要继承并重写的:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
可以看到我们需要实现获得训练、验证、测试数据接口,以及获得标签的接口。
这里我自己用的一个类。注释比较详细,就不解释了,主要体现了只要能获得数据,不论我们的文件格式是什么样的,都可以,所以不需要专门为了这个项目去改自己的输入数据格式。
class StatutesProcessor(DataProcessor):
def _read_txt_(self, data_dir, x_file_name, y_file_name):
# 定义我们的读取方式,我的工程中已经将x文本和y文本分别存入txt文件中,没有分隔符
# 用gfile读取,打开一个没有线程锁的的文件IO Wrapper
# 基本上和python原生的open是一样的,只是在某些方面更高效一点
with tf.gfile.Open(data_dir + x_file_name, 'r') as f:
lines_x = [x.strip() for x in f.readlines()]
with tf.gfile.Open(data_dir + y_file_name, 'r') as f:
lines_y = [x.strip() for x in f.readlines()]
return lines_x, lines_y
def get_train_examples(self, data_dir):
lines_x, lines_y = self._read_txt_(data_dir, 'train_x.txt', 'train_y.txt')
examples = []
for (i, line) in enumerate(zip(lines_x, lines_y)):
guid = 'train-%d' % i
# 规范输入编码
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
# 这里有一些特殊的任务,一般任务直接用上面的就行,下面的label操作可以注释掉
# 这里因为y会有多个标签,这里按单标签来做
label = label.strip().split()[0]
# 这里不做匹配任务,text_b为None
examples.append(
InputExample(guid=guid, text_a=text_a, label=label)
)
return examples
def get_dev_examples(self, data_dir):
lines_x, lines_y = self._read_txt_(data_dir, 'val_x.txt', 'val_y.txt')
examples = []
for (i, line) in enumerate(zip(lines_x, lines_y)):
guid = 'train-%d' % i
# 规范输入编码
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
label = label.strip().split()[0]
# 这里不做匹配任务,text_b为None
examples.append(
InputExample(guid=guid, text_a=text_a, label=label)
)
return examples
def get_test_examples(self, data_dir):
lines_x, lines_y = self._read_txt_(data_dir, 'test_x.txt', 'test_y.txt')
examples = []
for (i, line) in enumerate(zip(lines_x, lines_y)):
guid = 'train-%d' % i
# 规范输入编码
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
label = label.strip().split()[0]
# 这里不做匹配任务,text_b为None
examples.append(
InputExample(guid=guid, text_a=text_a, label=label)
)
return examples
def get_labels(self):
# 我事先统计了所有出现的y值,放在了vocab_y.txt里
# 因为这里没有原生的接口,这里暂时这么做了,只要保证能读到所有的类别就行了
with tf.gfile.Open('data/statutes_small/vocab_y.txt', 'r') as f:
vocab_y = [x.strip() for x in f.readlines()]
return vocab_y
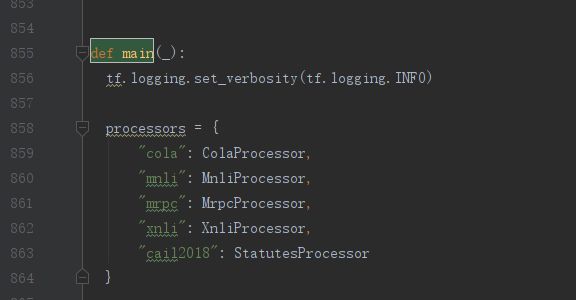
写好了之后需要更新一下processors列表,在main函数中,最下面一条就是我新加的。
执行训练微调
python run_classifier.py --data_dir=data/statutes_small/ --task_name=cail2018 --vocab_file=chinese_wwm_ext_L-12_H-768_A-12/vocab.txt --bert_config_file=chinese_wwm_ext_L-12_H-768_A-12/bert_config.json --output_dir=output/ --do_train=true --do_eval=true --init_checkpoint=chinese_wwm_ext_L-12_H-768_A-12/bert_model.ckpt --max_seq_length=200 --train_batch_size=16 --learning_rate=5e-5 --num_train_epoch=3相信我,写在一行,这个会有很多小问题,在centos服务器上如果不能按上返回上一条命令,将会很痛苦。。具体参数含义就和参数名是一致的,不需要解释。
另外,可以稍稍修改一些东西来动态输入训练集上的loss,因为BERT源码封装的太高了,所以只能按照这篇文章:https://www.cnblogs.com/jiangxinyang/p/10241243.html里面讲的方法,每100个step输出一次train loss(就是100个batch),这样做虽然意义不大,但是可以看在你的数据集上模型是不是在收敛,方便调整学习率。

在测试集上进行测试
默认test_batch_size = 8
python run_classifier.py --data_dir=data/statutes_small/ --task_name=cail2018 --vocab_file=chinese_wwm_ext_L-12_H-768_A-12/vocab.txt --bert_config_file=chinese_wwm_ext_L-12_H-768_A-12/bert_config.json --output_dir=output/ --do_predict=true --max_seq_length=200需要注意的是,调用测试接口会在out路径中生成一个test_results.tsv,这是一个以’\t’为分隔符的文件,记录了每一条输入测试样例,输出的每一个维度的值(维度数就是类别数目),需要手动做一点操作来得到最终分类结果,以及计算指标等等。
# 计算测试结果
# 因为原生的predict生成一个test_results.tsv文件,给出了每一个sample的每一个维度的值
# 却并没有给出具体的类别预测以及指标,这里再对这个“中间结果手动转化一下”
def cal_accuracy(rst_file_dir, y_test_dir):
rst_contents = pd.read_csv(rst_file_dir, sep='\t', header=None)
# value_list: ndarray
value_list = rst_contents.values
pred = value_list.argmax(axis=1)
labels = []
# 这一步是获取y标签到id,id到标签的对应dict,每个人获取的方式应该不一致
y2id, id2y = get_y_to_id(vocab_y_dir='../data/statutes_small/vocab_y.txt')
with open(y_test_dir, 'r', encoding='utf-8') as f:
line = f.readline()
while line:
# 这里因为y有多个标签,我要取第一个标签,所以要单独做操作
label = line.strip().split()[0]
labels.append(y2id[label])
line = f.readline()
labels = np.asarray(labels)
# 预测,pred,真实标签,labels
accuracy = metrics.accuracy_score(y_true=labels, y_pred=pred)
# 这里只举例了accuracy,其他的指标也类似计算
print(accuracy)
def get_y_to_id(vocab_y_dir):
# 这里把所有的y标签值存在了文件中
y_vocab = open(vocab_y_dir, 'r', encoding='utf-8').read().splitlines()
y2idx = {token: idx for idx, token in enumerate(y_vocab)}
idx2y = {idx: token for idx, token in enumerate(y_vocab)}
return y2idx, idx2y
这部分代码在classifier/cal_test_matrix.py中。
我的代码地址:
点击这里
参考:
https://github.com/google-research/bert
https://www.cnblogs.com/jiangxinyang/p/10241243.html
https://www.jiqizhixin.com/articles/2019-06-21-01
https://arxiv.org/abs/1906.08101