2019独角兽企业重金招聘Python工程师标准>>> 
本文隶属于新手图文教程《IDEA+Maven搭建Spring+SpringMVC+Mybatis项目骨架》
下一篇:Maven使用图示-关于生命周期、命令行和IDEA插件
目录 & 项目地址:http://git.oschina.net/mzdbxqh/ssm-study/
本文即将介绍各个子模块的依赖配置。在此之前,有必要先明确一下依赖传递、依赖范围和类加载器等概念,确保新手能清晰地理解配置的原理。下面摘录study-common的pom.xml作为例子:
study-parent/study-common/pom.xml
study-parent
com.oschina
1.0-SNAPSHOT
4.0.0
study-common
junit
junit
com.alibaba
fastjson
com.google.guava
guava
org.slf4j
slf4j-api
org.slf4j
slf4j-log4j12
一、依赖的传递
1. 传递依赖
在maven里,依赖是会传染的。传染有两种方式,一种是Sub Module对Parent Module的继承依赖,另一种就是依赖传递。首先,如红1在maven插件中选中study-common,然后点击红2的图标,生成study-common的依赖关系图如下:

红色区域中,study-common后面有五条连接线,分别对应五个在pom中配置的依赖。而junit和slf4j-log4j12后面各还有一条连接线,连接着两个陌生的依赖。它们是从哪冒出来的?现在从junit入手,追溯一下hamcrest-core的来源。我们先到maven本地仓库找一下junit/pom.xml:

如图中红色区域所示,Junit项目依赖于hamcrest-core,导致study-common间接地依赖hamcrest-core。这就是传递依赖,其规则是:A依赖B,B依赖C,那么A依赖C。
在上一张依赖关系图中,与study-common直接相连的五个就是“直接依赖”,间接通过junit与study-common相连的hamcrest-core就是“传递依赖”。
2. 可选依赖
举个栗子,我在店铺了买了一个USB充电器。除了这个充电器,店家还卖一些配件,例如USB小台灯、USB小风扇、USB充电数据线等等。如果我想点个小灯,我可以买那个小台灯接上;我觉得热,可以要了那个小风扇;我手机没电,就接上充电数据线。
在上面这个例子中,USB充电器就是我的一个依赖。但是这个组件可能还需要其他一些配件才能工作。这些可选的配件被配置为optional=true(可选依赖),我想用哪一个配件,就显式地在我的pom上配置该配件的依赖。
这就是含有可替换特性的包了,例如日志功能,你给配log4j他能用,给配logback也能用。这种情况在后面解释scope的时候会提到。
特殊一点的情况是,我买的这个东西其实是一个多功能插座,插座上带有USB插口。我买配件让USB插口发挥作用也行,不买配件,它仍然是个略贵但能正常工作的插座。
这就好比含可选特性的包,你要用到它的某项特性,就手动配置该特性所需要的依赖,而不会自动传递。
3. 依赖冲突
既然有传递依赖,就不可避免的会出现下图这种情况:
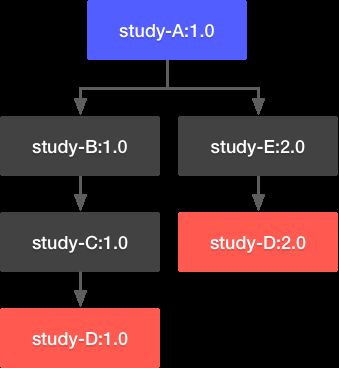
如图,因为传递依赖机制,项目study-A既依赖于项目study-D:1.0版本,又依赖于项目study-D:2.0版本,造成依赖冲突。解决这个问题有两个办法,一个是通过手工排除其中一个依赖;另一个就是由maven自行通过算法去选择。
算法有两种:
- 选择传递依赖 - 同样是传递依赖,maven优先选传递路径短的那个。
如上图中的D:2.0,它离A只差一个节点;而D:1.0离A差两个节点。 - 选择直接依赖 - maven优先选配置在前面的那个(老版本没有这个特性)。
例如同一个pom里面约定了两个study-F,先约定的是2.0,后约定的是1.0,maven选2.0那个。
4. 依赖排除
好了,如上所说,出现了依赖冲突或者我想将某个依赖替换为同类的其他实现怎么办?用依赖排除。
以下是:study-parent/pom.xml/dependencyManagement的一段
org.springframework
spring-core
${spring.version}
commons-logging
commons-logging
二、依赖的范围
解释依赖范围之前,需要先简单说明一下类加载器。
1. 类加载器 - ClassLoader
Java创造了一套自己的指令系统(字节码),并号称这套指令可以运行在任何系统上,也就是传说中的跨平台。实际上呢,人家操作系统根本就不认识字节码。Java之所以能跑起来,是因为他们给不同的平台分别定制了一个能运行在该平台上的Java虚拟机(Java Virtual Machine,简称 JVM),然后依靠JVM来把字节码解释为操作系统能看懂的机器码,从而实现跨平台运行。
而JVM呢,基本是用C、C++和汇编写的,这也就是为什么在程序员鄙视链中Java会排在C++后面了...
假设现在要跑一个Java程序 - Tomcat7:
java org.apache.catalina.startup.Bootstrap- 首先会启动JVM。
- JVM有一个内置的程序叫Bootstrap ClassLoader。它会加载$JAVA_HOME/jre/lib/rt.jar。
这不是前端的那个bootstrap框架,而是一个用C++写的java类加载器。
rt即runtime,是个实现Java运行时环境的基础包,包含了java.lang.String等所有基础类。 - 刚加载的基础类,有个sun.misc.Launcher类,定义了另外两个用Java写的类加载器Extension ClassLoader和APP ClassLoader,其中,Extension ClassLoader会先加载$JAVA_HOME/jre/lib/ext/下的扩展包。然后,APP ClassLoader会到$ClassPath目录加载其他系统包。
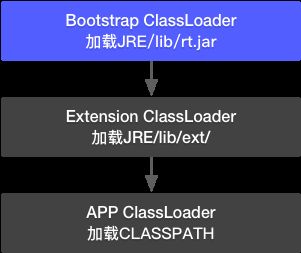
正常情况下,当APP ClassLoader收到了一个请求,要获取org.apache.catalina.startup.Bootstrap,它将做以下尝试(上源码,更直观):
protected Class loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查该class是否已经加载
Class c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 如果没有加载,检查是否有“父加载器”
// 如果有,交给父加载器的loadClass
// 如果没有,交给Bootstrap
// 即责任链模式
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// 如果父加载器没有返回该类,就在本加载器环节尝试加载
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
源码在$JAVA_HOME目录下的src.zip里面。
用时序图来表示如下图(没找到bootstrap源码,其内部逻辑是我猜的)
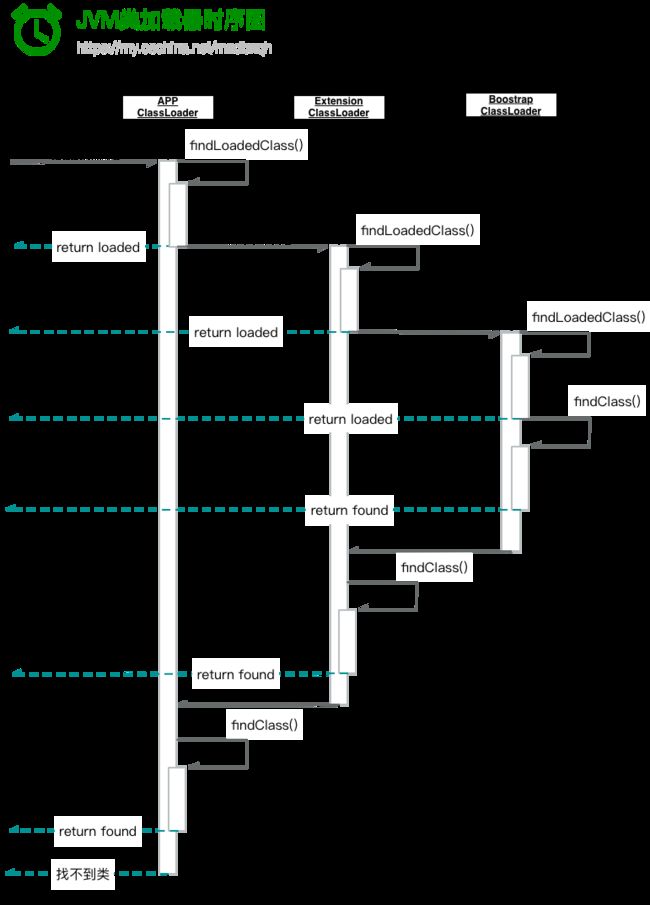
上述继承自ClassLoader类的loadClass方法利用了责任链模式,它实现以下内容:
- 每个类首次被加载时,是按类加载器父子结构的顶端到底端依次加载的。加载后,类会被缓存在相应的加载器一段时间。当类加载器收到请求时,如果该类还在某一个类加载器缓存内,就是逐步向上委托查找缓存时找到的;如果已经不在缓存里了,就是从Bootstrap开始往下尝试加载时加载的,这被称为委派机制。
- 通过委派机制,子类加载器可以看见父类加载器加载过的类,反之不成立,这被称为可视机制。
- 同一个JVM里面,判断两个类是否相同的依据是类的全路径名称和类加载器名称是否完全相同。但由于委派机制的存在,每个类只要在父类加载器哪里被找到,子类加载器就不会再尝试加载了,因此,同名的类只能被加载一次,这被称为单一原则。
以上机制能保证Java依赖被按次序层层加载,并避免核心类被恶意篡改。
到了这里,就可以执行org.apache.catalina.startup.Bootstrap.main()了。然后问题来了,上面三个默认的类加载器只加载固定目录下的类,那由谁来加载我们的webapp呢?答案是tomcat自己实现的类加载器。

如上图所示:
- JVM的APP类加载器加载了tomcat的几个核心包以支持其启动
- tomcat临时覆盖了系统的ClassPath,改为tomcat的启动支持包 - Tomcat的Common类加载器加载了tomcat的运行支持包及对web的支持包。
- Tomcat的webapp加载器加载web程序的包以支持web程序运行。
发现没有,上图跟委派机制的流程完全不同!因为tomcat的webapp类加载器重写了loadClass方法,刻意违反了向上委托原则。参考链接
2. 依赖范围 - scope
大致理解了类加载器的工作机制,就可以开始看第三方依赖的依赖范围了。首先要明确,对于一个第三方依赖,可以把使用场景分成以下五种:
- 开发时
- 编译时
- 运行时
- 测试编译时
- 测试运行时
对应这些使用场景,maven设计了scope(依赖范围),把依赖的范围分为compile、provided、runtime、test、system和import六种。注意,只要配置了第三方依赖,无论是哪一种scope,IDEA都会把它列入External Libaraies进行索引,以用作在我们开发时弹出相应的代码补全提示等用途。
下面我们来看前四种Scope:
★ compile
当一个第三方依赖在上述五种场景都要用到时,即选用compile这种范围。这也是scope的默认值。在打包war时,该类依赖会被一起打包。
★ provided
IDEA、Javac、maven-compile-plugin的本质都是Java程序,其运行需依赖于JVM实例,自然也就加载了上文所说的那些基础类包和扩展类包。在自己的程序中引入、使用这些类包时是不需要配置依赖的。但是,对于只在运行时才由容器提供的那些类包,例如tomcat的servlet API,是这几个IDE/工具所不了解的。
因此,如果你要使用如servlet API进行开发,就必须配置相应的依赖,并把scope配置为provided。意思是,我开发时请帮我索引以实现代码补全提示,编译时请加载这些包以校验我的代码正确性,但是,不要打包,因为容器会提供这些包。
更具体地说,如果我依赖了servlet API并且没有配置scope,那么我的war包里边就会含有servlet-api.jar。按照tomcat的类加载顺序,启动时已经由Common ClassLoader加载了一个servlet-api,运行时如需加载servlet-api,请求会发往Webapp ClassLoaderwar,而该加载器会先到我的webapp里找到并发现我包里的servlet-api,结果就是一个jvm里面出现了两个相同的包以及包里相同或版本有差异的类,导致报错(官方文档提到webapp ClassLoader会刻意忽略掉webapp里面的servlet-api包,但实测发现仍会报错)。
★ runtime
为了解耦,我们经常是面向接口编程而不是面向具体实现类编程,最终打包的时候,就分成了接口和实现两种包。在开发和编译时,我们调用一个方法,IDEA和Javac并不要求知道具体的实现类,只要我们引用的依赖能告诉它们接口就行。这样一来,只要把scope配置为runtime,就可以不参与编译,但是会被打包,因为测试时和运行时都要加载该依赖。
举个栗子来说明这种scope的应用场景:
开发一个ORM框架,连接数据库部分全部面向JDBC接口编程,然后通过Spring来注入具体的实现类。这时候,项目的pom.xml就可以同时配置Mysql、Oracle、Sqlserver的实现类依赖,scope设置为runtime,并配置为optional(可选依赖)。然后运行的时候,只需要修改Spring的配置文件,改变注入的实现,就可以分别连接不同类型的数据库。
其他项目引用该依赖时,因为orm/pom.xml里JDBC实现类都配置成了optional,故项目不会传递这些实现类的依赖,此时要根据具体环境手动配置一个实现类。例如我们给Mybatis配置的Mysql连接包。
★ test
test依赖就简单了,就是Junit一类的测试框架准备的,用在test类开发、test类编译(测试编译)和test类运行(测试运行)三种场景。
依赖范围会影响依赖的传递,例如范围为test的依赖并不会被传递。详见maven官方文档。
三、依赖配置
基于以上两点说明,各模块的依赖关系就比较清晰了。study-plugin是预留的模块,只依赖于junit和study-common,暂不做其他配置。
1. study-blog
如第三天所说的工程结构变体,这个模块的作用其实是Aggregator(聚合器)而不是Parent(父模块),所以这个模块不需要配置依赖,而在多子系统的结构下需要配置的build部分此时已经放在了study-parent中,故也不需要配置。
2. study-blog-pojo
pojo基于贫血模型,只有领域模型的属性和get/set方法,其他行为全部放在了逻辑层。因此它不需要任何依赖。
3. study-blog-mapper
根据mapper的职责,他需要能通过orm框架连接数据库,并将数据与po实体绑定。那么它需要依赖pojo、mybatis、mysql驱动和连接池,后续开发时还要加入一些增强Mybatis的插件。
com.oschina
study-blog-pojo
${project.version}
org.mybatis
mybatis
org.mybatis
mybatis-spring
mysql
mysql-connector-java
com.alibaba
druid
4. study-blog-service
作为三层架构最厚的一层,service几乎用到了Spring的大部分特性。虽然诸如Ioc相关的依赖放在离tomcat启动最近的web模块也没有问题,但出于职责划分以及service模块需要实现独立于controller进行测试的考虑,在这一层引入依赖。
com.oschina
study-blog-mapper
${project.version}
com.oschina
study-plugin
${project.version}
org.springframework
spring-context
org.springframework
spring-aspects
org.springframework
spring-jdbc
${spring.version}
org.springframework
spring-tx
${spring.version}
实际依赖的Spring模块有:
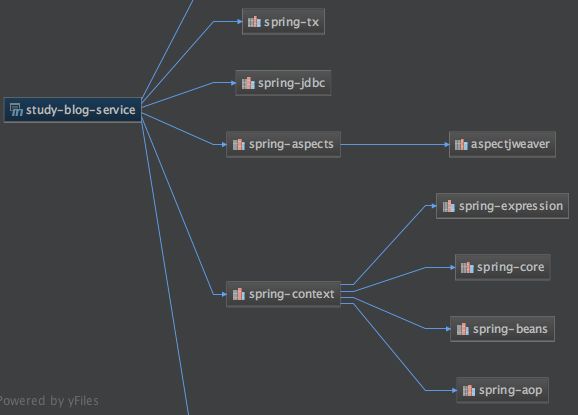
实际依赖的模块数量远多于配置的数量,而且都是必须的依赖。对于这个问题,有两种观点:
- 通过传递依赖,大幅减少了配置的代码量;而且采用官方推荐的传递依赖,稳定性更佳。
- 在非正式版本中,Spring-context及其传递的依赖可能分别属于两个临近的小版本,很容易出现依赖冲突,建议明确手动配置所有依赖(即在上面配置中加入Spring-core、Spring-beans、Spring-aop等)。
这里采用的是4.3.6的最终发布版本,我检查过了,所有模块及其依赖版本一致,故采用观点1的做法。
5. study-controller
com.oschina
study-blog-service
${project.version}
org.springframework
spring-webmvc
同样,通过spring-webmvc和study-service的传递,controller模块依赖了大部分Spring模块。图片较大,请自行通过插件查看依赖关系图。
6. study-web
这里后续可能会加入与前端交互相关的依赖,例如文件上传组件等。
com.oschina
study-blog-controller
${project.version}
jstl
jstl
javax.servlet
servlet-api
javax.servlet
jsp-api
完整代码以Github项目为准。