Scrapy实例————爬取学堂在线合作院校页面内容
目标
通过Scrapy爬取到合作院校的名称及该所院校在学堂在线开课的数量,将爬取到的数据保存到一个json文件中,例如:“清华大学,308”,地址 http://www.xuetangx.com/partners 。
环境
博主是在Windows平台使用PyCharm基于Python 3.7和Scrapy 2.0.1编写爬虫,不赘述环境配置了。
建立项目
右键Scrapy文件夹,选择在终端中打开
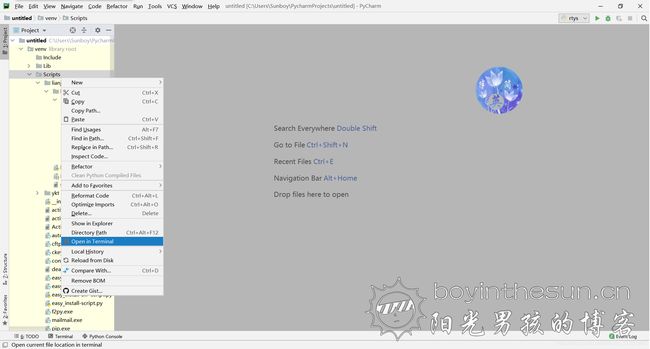
在终端中输入scrapy startproject xtzx,其中xtzx为项目名(忽略图中lianjia,只是博主懒得再重新截图了,下同)。
新建begin.py
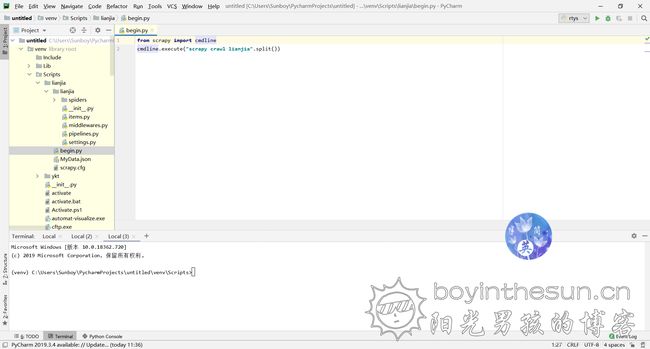
在项目文件夹中新建begin.py,内容为:
from scrapy import cmdline
cmdline.execute("scrapy crawl xtzx".split())
其中xtzx为爬虫名(无须与项目名相同)。目的是为了方便运行爬虫。否则,需要在终端手动输入scrapy crawl xtzx来运行
更改items.py
import scrapy
class MyItem (scrapy.Item):
school = scrapy.Field()
num = scrapy.Field()
分析网页
右键爬取内容,检查,以下以school为例讲解。
复制三个school的xpath路径,不难找到规律。
/html/body/article[1]/section/ul/li[1]/a/div[2]/h3
/html/body/article[1]/section/ul/li[2]/a/div[2]/h3
/html/body/article[1]/section/ul/li[3]/a/div[2]/h3
新建并更改spider.py
在spider文件夹中新建spider.py,并键入:
import scrapy
from xtzx.items import MyItem
class mySpider(scrapy.spiders.Spider):
name = "xtzx"
allowed_domains = ["xuetangx.com"]
start_urls = ["http://www.xuetangx.com/partners"]
def parse(self, response):
item = MyItem ()
#开课院校
for each in response.xpath("/html/body/article[1]/section/ul/*"):
item['school'] = each.xpath("a/div[2]/h3/text()").extract()
item['num'] = each.xpath("a/div[2]/p/text()").extract()
yield item
#edX合作院校和伙伴
for each in response.xpath("/html/body/article[2]/section/ul/*"):
item['school'] = each.xpath("a/div[2]/h3/text()").extract()
item['num'] = each.xpath("a/div[2]/p/text()").extract()
yield(item)
更改setting.py
#不遵守机器人协议
ROBOTSTXT_OBEY = False
BOT_NAME = 'xtzx'
SPIDER_MODULES = ['xtzx.spiders']
NEWSPIDER_MODULE = 'xtzx.spiders'
#开启管道
ITEM_PIPELINES = {'xtzx.pipelines.MyPipeline': 300,}
#客户端伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
更改pipelines.py
import json
class MyPipeline (object):
#打开文件
def open_spider (self,spider):
try:
self.file = open('MyData.json ', "w", encoding="utf-8")
except Exception as err:
print(err)
#写入
def process_item (self, item, spider):
dict_item = dict (item)
# 生成 json 串
json_str = json.dumps(dict_item , ensure_ascii=False) + "\n"
self.file.write(json_str)
return item
#关闭文件
def close_spider (self,spider):
self.file.close()
运行爬虫
运行begin.py,成功爬取到数据。这里只列举部分数据。
{"school": ["清华大学"], "num": ["31门课程"]}
{"school": ["台湾清华大学"], "num": ["0门课程"]}
{"school": ["台湾交通大学"], "num": ["0门课程"]}
{"school": ["斯坦福大学"], "num": ["0门课程"]}
{"school": ["中央社会主义学院"], "num": ["0门课程"]}
{"school": ["西安交通大学"], "num": ["16门课程"]}
{"school": ["中南财经政法大学"], "num": ["3门课程"]}
{"school": ["复旦大学"], "num": ["0门课程"]}
{"school": ["北京理工大学"], "num": ["0门课程"]}
{"school": ["中国科学技术大学"], "num": ["0门课程"]}
交流讨论等具体内容请访问我的博客
原文地址:https://www.boyinthesun.cn/post/python-scrapy1/