python里使用iterrows()对dataframe进行遍历
假设我们有一个很简单的OTU表:
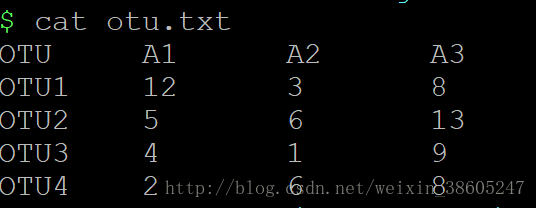
现在对这个表格进行遍历,一般写法为:
import pandas as pd
otu = pd.read_csv("otu.txt",sep="\t")
for index,row in otu.iterrows():
print index
print row这里的iterrows()返回值为元组,(index,row)
上面的代码里,for循环定义了两个变量,index,row,那么返回的元组,index=index,row=row.

如果for循环时,只定义一个变量:
import pandas as pd
otu = pd.read_csv("otu.txt",sep="\t")
for row in otu.iterrows():
print row
那么row就是整个元组。输出结果可以看出:
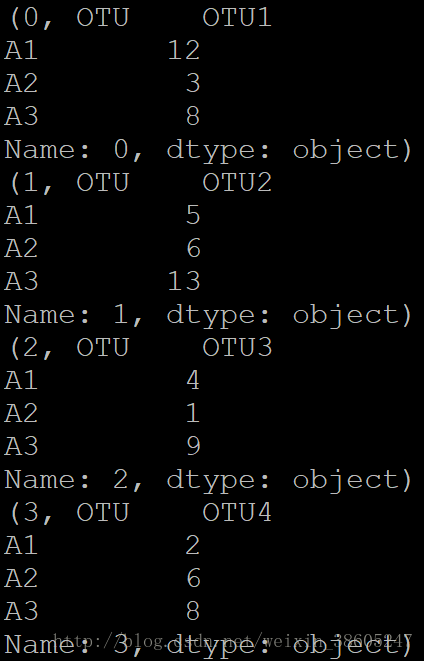
所以还是第一种写法比较方便。