文本特征提取方法
1. one-hot
1.1 one-hot编码
什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
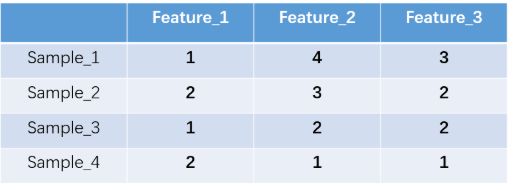
上图中已经对每个特征进行了普通的数字编码:feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。
这里feature_2 有4种取值(状态),用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,可以得到这些样本特征的新表示:
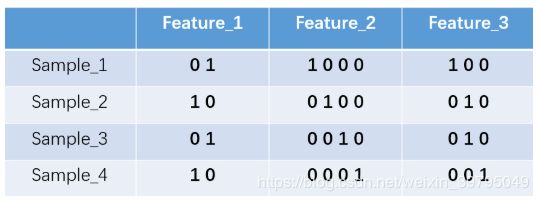
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

为什么使用one-hot编码来处理离散型特征?
在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
而我们使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。
比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,其表示分别是x_1 = (1), x_2 = (2), x_3 = (3)。两个工作之间的距离是,d(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2。那么x_1和x_3工作之间就越不相似吗?显然这样的表示,计算出来的特征的距离是不合理。那如果使用one-hot编码,则得到x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1),那么两个工作之间的距离就都是sqrt(2).即每两个工作之间的距离是一样的,显得更合理。
one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。假设语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:

优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
sklearn实现one hot encode
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder() # 创建对象
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 拟合
array = enc.transform([[0,1,3]]).toarray() # 转化
print(array)
2. TF-IDF
IF-IDF是信息检索(IR)中最常用的一种文本表示法。算法的思想也很简单,就是统计每个词出现的词频(TF),然后再为其附上一个权值参数(IDF)。举个例子:
假设要统计一篇文档中的前10个关键词.首先想到的是统计一下文档中每个词出现的频率(TF),词频越高,这个词就越重要。但是统计完你可能会发现你得到的关键词基本都是“的”、“是”、“为”这样没有实际意义的词(停用词),这个问题怎么解决呢?你可能会想到为每个词都加一个权重,像这种”停用词“就加一个很小的权重(甚至是置为0),这个权重就是IDF。下面再来看看公式:

IF应该很容易理解就是计算词频,IDF衡量词的常见程度。为了计算IDF我们需要事先准备一个语料库用来模拟语言的使用环境,如果一个词越是常见,那么式子中分母就越大,逆文档频率就越小越接近于0。这里的分母+1是为了避免分母为0的情况出现。TF-IDF的计算公式如下:
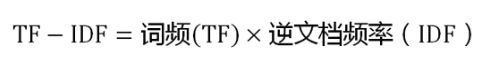
根据公式很容易看出,TF-IDF的值与该词在文章中出现的频率成正比,与该词在整个语料库中出现的频率成反比,因此可以很好的实现提取文章中关键词的目的。
优缺点分析
优点:简单快速,结果比较符合实际
缺点:单纯考虑词频,忽略了词与词的位置信息以及词与词之间的相互关系。
sklearn实现tfidf
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
tag_list = ['青年 吃货 唱歌',
'少年 游戏 叛逆',
'少年 吃货 足球']
vectorizer = CountVectorizer() #将文本中的词语转换为词频矩阵
X = vectorizer.fit_transform(tag_list) #计算个词语出现的次数
"""
word_dict = vectorizer.vocabulary_
{'唱歌': 2, '吃货': 1, '青年': 6, '足球': 5, '叛逆': 0, '少年': 3, '游戏': 4}
"""
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X) #将词频矩阵X统计成TF-IDF值
print(tfidf.toarray())
参考:
1.https://www.cnblogs.com/lianyingteng/p/7755545.html
2.https://www.imooc.com/article/35900