python学习笔记(三十九) -- yield from 、asyncio、async/await 、aiohttp
Table of Contents
前言
yield from
asyncio
async/await
aiohttp
前言
由于 cpu和 磁盘读写的 效率有很大的差距,往往cpu执行代码,然后遇到需要从磁盘中读写文件的操作,此时主线程会停止运行,等待IO操作完成后再继续进行,这要就导致cpu的利用率非常的低。
协程可以实现单线程同时执行多个任务,但是需要自己手动的通过send函数和yield关键字配合来传递消息,asyncio模块能够自动帮我们传递消息。
在介绍asyncio模块之前我们先来了解一下yield from 关键字
yield from
作用1 包含yield from 关键字的函数也会编程一个generator对象。
作用2 yield from 关键字后面是一个iterable对象,其含义与下面类似
for item in iterable:
print(item)看案例
>>> def test1():
yield [1,2,3,4,5]
>>> t1 = test1()
>>> next(t1)
[1, 2, 3, 4, 5]
-----------------------------------------------------------------------------------------
>>> def test1():
yield from [1,2,3,4,5]
>>> t=test1()
>>> next(t)
1
>>> next(t)
2
>>> next(t)
3
>>> next(t)
4
>>> next(t)
5
如果yield from 关键字后面是一个generator对象,又因为包含yield from的函数也会变成Iterator对象,所以之后迭代该Iterator对象,实际上迭代的是yield from 后面的Iterator对象,话说起来比较绕
看个简单的案例
>>> def test1():
a = 0
while 1:
a = a+1
yield a
>>> def test2():
yield from test1()
>>> t2=test2()
>>> next(t2) # 实际迭代的是test1这个generator
1
>>> next(t2)
2
>>> next(t2)
3
>>> next(t2)
4
>>> next(t2)
5再看一个案例
def htest():
i = 1
while i < 4:
print('i', i)
n = yield i
print('n', n)
if i == 3:
return 100
i += 1
def itest():
val = yield from htest()
print(val)
t = itest()
print(type(t))
t.send(None)
j = 0
while j < 3:
j += 1
try:
t.send(j)
except StopIteration as e:
print('异常了')结果如下
i 1
n 1
i 2
n 2
i 3
n 3
100
异常了 过程分析:
t.send(None) 首先会执行itest()函数中的yield from htest() 语句,然后会进入到函数htest中,并执行到 yield i,然后htest函数执行到这里会被阻塞,返回到itest函数中,val 不会接收yield i 的返回值,val只会接收 htest函数中return的返回值,并由于itest函数目前也是一个generator对象且htest函数由于yield语句被阻塞,也就导致了itest函数被阻塞,所以会继续执行
j = 0 , 以及while 语法块里面的内容,语法块中执行到t.send(j)时,会从htest函数中阻塞的位置继续执行同时将 j 的值赋给 n。
这样循环几次之后,当i的值 等于 3时,htest通过return 返回100,100被赋值给val,val获取到值以后itest函数就会继续向下执行,打印val的值。但是由于itest此时也是一个迭代器,我们通过send函数使itest迭代器向下迭代,但其最终没有返回值,所以会抛出异常,如果我们将 print(val) 改成 yield val 就不会抛出异常。了解了yield from关键字以后我们就可以看asyncio模块了。
asyncio
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个Eventloop的引用,然后把需要执行的协程扔到Eventloop中执行,就实现了异步IO。
import threading
import asyncio
import time
@asyncio.coroutine # 将一个generator定义为coroutine
def hello(name):
print('Hello %s! (%s), current time : %s' % (name, threading.currentThread(), time.time()))
yield from asyncio.sleep(1) # 停止1s,但线程不会中断,线程会继续执行下一个任务,1s过后会通知线程
print('Hello %s! (%s), current time : %s' % (name, threading.currentThread(), time.time()))
print(type(hello('zzh')))
loop = asyncio.get_event_loop() # 获取一个循环事件
tasks = [hello('zzh1'), hello('zzh2')] # 定义一个任务列表
# 通过 run_until_complete 将任务放入消息循环中
loop.run_until_complete(asyncio.wait(tasks)) # wait 会分别把各个协程包装进一个 Task 对象。
loop.close()
结果如下
Hello zzh2! (<_MainThread(MainThread, started 13812)>), current time : 1537098336.281302
Hello zzh1! (<_MainThread(MainThread, started 13812)>), current time : 1537098336.281302
间隔1s左右
Hello zzh2! (<_MainThread(MainThread, started 13812)>), current time : 1537098337.2820885
Hello zzh1! (<_MainThread(MainThread, started 13812)>), current time : 1537098337.2820885 至于上面的 hello函数是一个generator但其没有使用yield返回值,且未抛出异常,是因为yield from 函数为我们做了很多的异常处理。
下面使用asyncio模块结合协程,实现单线程并发获取3个网站的数据
import asyncio
@asyncio.coroutine
def wget(host):
print('wget %s...' % host)
connect = asyncio.open_connection(host, 80) # 与要获取数据的网页建立连接
# 连接中包含一个 reader和writer
reader, writer = yield from connect # 通过writer向服务器发送请求,通过reader读取服务器repnse回来的请求
header = 'GET / HTTP/1.0\r\nHost: %s\r\n\r\n' % host # 组装请求头信息
writer.write(header.encode('utf-8')) # 需要对请求头信息进行编码
yield from writer.drain() # 由于writer中有缓冲区,如果缓冲区没满不且drain的话数据不会发送出去
while True:
line = yield from reader.readline() # 返回的数据放在了reader中,通过readline一行一行地读取数据
if line == b'\r\n': # 因为readline实际上已经把\r\n转换成换行了,而此时又出现\r\n说明以前有连续两组\r\n
break # 即\r\n\r\n,所以下面就是response body了
print('%s header > %s' % (host, line.decode('utf-8').rstrip()))
# Ignore the body, close the socket
writer.close()
# reader.close() AttributeError: 'StreamReader' object has no attribute 'close'
loop = asyncio.get_event_loop()
tasks = [wget(host) for host in ['www.sina.com.cn', 'www.sohu.com', 'www.163.com']]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()async/await
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
请注意,async和await是针对coroutine的新语法,要使用新的语法,只需要做两步简单的替换:
1.把@asyncio.coroutine替换为async
2.把yield from 替换为 await
import threading
import asyncio
import time
async def hello(name): # 这里把@asyncio.coroutine替换为async;
print('Hello %s! (%s), current time : %s' % (name, threading.currentThread(), time.time()))
# 下面把yield from 替换为 await
await asyncio.sleep(1) # 停止1s,但线程不会中断,线程会继续执行下一个任务,1s过后会通知线程
print('Hello %s! (%s), current time : %s' % (name, threading.currentThread(), time.time()))
loop = asyncio.get_event_loop() # 获取一个循环事件
tasks = [hello('zzh1'), hello('zzh2')] # 定义一个任务列表
# 通过 run_until_complete 将任务放入消息循环中
loop.run_until_complete(asyncio.wait(tasks)) # wait 会分别把各个协程包装进一个 Task 对象。
loop.close()
aiohttp
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
之前在 多线程与多进程 一文中我提到过 nginx就是通过协程来实现高并发的。
下面是一个使用aiohttp的小案例
import asyncio
from aiohttp import web
async def index(request):
await asyncio.sleep(0.5)
# 这里数据的传输必须将其转换成byte类型,content_type用来告诉浏览器显示的内容是文本类型
return web.Response(body='Index
'.encode(), content_type='text/html')
# 如果没有参数content_type 默认是附件类型,因为Response源码中有如下几行代码
# if content_type is None:
# content_type = 'text/plain'
async def hello(request):
await asyncio.sleep(0.5)
# request.match_info['name'] 能够匹配到url http://127.0.0.1:8000/hello/zzh ,hello后面的部分,如zzh
text = 'hello, %s!
' % request.match_info['name']
return web.Response(body=text.encode('utf-8'), content_type='text/html')
async def init(loop):
app = web.Application(loop=loop)
app.router.add_route('GET', '/', index) # url与函数绑定
app.router.add_route('GET', '/hello/{name}', hello)
# create_server函数用来绑定ip和端口号,且create_server是一个coroutine对象
srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000) #app。make_handler 用来绑定HTTP协议簇
print('Server started at http://127.0.0.1:8000...')
return srv
# 获取循环事件
loop = asyncio.get_event_loop()
# 将coroutine放入循环事件中
loop.run_until_complete(init(loop)) # 由于init函数内使用了await,所以init()也是coroutine对象
loop.run_forever()效果如下
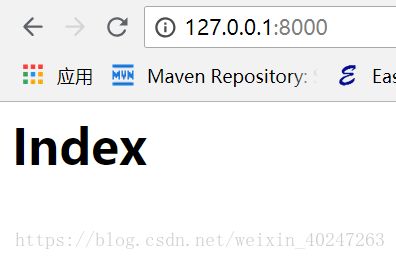

hello 后面没有地址会访问不到
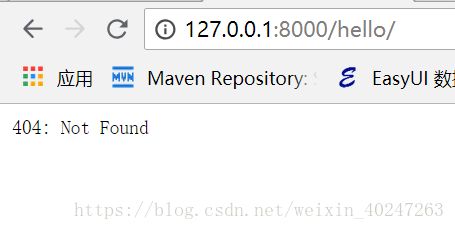
后面多出一部分也不行
