综合一
自我介绍
左固定右自适应布局
这是一个很常见的布局,当然也可以实现右侧自适应,左侧自适应。比如常见的网页中,左侧导航栏是固定的,右侧的内容区要自适应浏览器的大小。
现在我们来看下HTML布局:
<div id="outer">
<div id="sidebar" style="height:240px;">固定宽度区div>
<div id="content" style="height:340px;">自适应区div>
div>
<div id="footer">后面的一个DIV,以确保前面的定位不会导致后面的变形div>
下面讲一下常见的方法:
1、将左侧div浮动,右侧div设置margin-left。
.sidebar{
width: 300px;
height: 300px;
background-color: pink;
float:left;
}
.content{
margin-left: 300px;
height: 100px;
background-color: blue;
}
.footer{
background-color: red;
}
.outer:after{
display: block;
content:'';
clear: both;
visibility: hidden;
}
.outer{
zoom:1;
}
效果图如下:
大家要注意html中必须使用div标签,不要妄图使用什么p标签来达到目的。因为div有个默认属性,即如果不设置宽度,那他会自动填满他的父标签的宽度。这里的content就是例子。
当然我们不能让他填满了,填满了他就不能和sidebar保持同一行了。我们给他设置一个margin。由于sidebar在左边,所以我们设置content的margin-left值,值比sidebar的宽度大一点点——以便区分他们的范围。例子中是300.
假设content的默认宽度是100%,那么他设置了margin后,他的宽度就变成了100%-300,此时content发现自己的宽度可以与sidebar挤在同一行了,于是他就上来了。
而宽度100%是相对于他的父标签来的,如果我们改变了他父标签的宽度,那content的宽度也就会变——比如我们把浏览器窗口缩小,那wrap的宽度就会变小,而content的宽度也就变小——但,他的实际宽度100%-300始终是不会变的。
这个方法看起来很完美,只要我们记得清除浮动(这里我用了最简单的方法),那footer也不会错位。而且无论content和sidebar谁更长,都不会对布局造成影响.
但实际上这个方法有个限制——html中sidebar必须在content之前!
如果siderbar当到了content后面,就会出现如下的效果:
但我需要sidebar在content之后!因为我的content里面才是网页的主要内容,我不想主要内容反而排在次要内容后面。
但如果sidebar在content之后,那上面的一切都会化为泡影。
可能有的人不理解,说你干嘛非要sidebar在后面呢?这个问题说来话长,反正问题就是——content必须在sidebar之前,但content宽度要自适应,怎么办?接着往下看。
2、固定区采用绝对定位,自适应区仍然设置margin。
CSS代码如下:
.sidebar{
width: 300px;
height: 300px;
background-color: pink;
position: absolute;
top:0;
left: 0;
}
.content{
height: 100px;
background-color: blue;
}
.footer{
background-color: red;
}
.outer{
position: relative;
}
效果图:
可以发现,此时下面的红色div受影响了。其实这与footer无关,而是因为outer对sidebar的无视造成的。看来这种定位方式只能满足sidebar自己,但对他的兄弟们却毫无益处。
3、标准浏览器的方法
当然,以不折腾人为标准的w3c标准早就为我们提供了制作这种自适应宽度的标准方法。那就简单了:把outer设为display:table并指定宽度100%,然后把content+sidebar设为display:table-cell;然后只给sidebar指定一个宽度,那么content的宽度就变成自适应了。
对应的CSS代码
.sidebar{
width: 300px;
height: 300px;
background-color: pink;
display:table-cell;
}
.content{
height: 100px;
background-color: blue;
display:table-cell;
}
.footer{
background-color: red;
}
.outer{
display: table;
width:100%;
}
不过这种做法,如果sidebar写在content前面,sidebar会固定在左侧,否则固定在右侧。
HTML:
<div class="outer">
<div class="sidebar">
sidebar固定区域
div>
<div class="content">
content自适应区域
div>
div>
<div class="footer">
后面的一个DIV,以确保前面的定位不会导致后面的变形
div>
代码很少,而且不会有额外标签。不过这是IE7都无效的方法。
———————再说一点————————
如果不考虑ie7及以下版本,则使用标准方法;如果不在意sidebar与content的顺序,则用第一种方法;如果不考虑对其他兄弟元素的影响,用第3种方法。
以上代码都没在IE6测试,有问题不负责解释。让IE6寿终正寝的办法就是——从此不再理他。
左边定宽,右边自适应布局的几种方法
实际的页面开发中经常会遇到左边定宽,右边自适应的需求,特别是一些管理系统,比如左边显示信息或操作列表,右边显示详情,如下所示:、

针对这种布局,首先抽象出页面结构如下:
1 2 3 4 5 Document 6 28 29 30 31 32 33 Right 34 35
浏览器中效果:

需要实现的效果如下:

那么针对这种常见的布局,方式是非常多的,下面给出几种比较简单和常见的方法。
方法一:左边设置左浮动,右边宽度设置100%
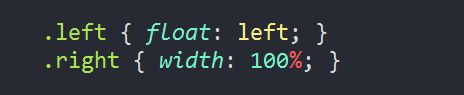
【分析】这样的方式简单得让我怀疑,但是效果上确实是实现了。
方法二: 父容器设置 display:flex;Right部分设置 flex:1

【分析】display:flex; 设置为弹性盒子,其子元素可以通过设置 flex 的数值来控制所占空间的比例。
方法三:设置浮动 + 在 css 中使用 calc() 函数
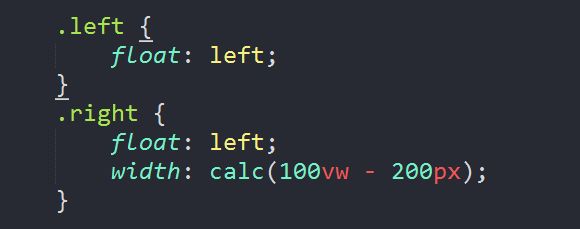
【分析】
1. 浮动。(注意:为了不影响其他元素,别忘了在父级上清除浮动)
2. calc() = calc(四则运算) 用于在 css 中动态计算长度值,需要注意的是,运算符前后都需要保留一个空格,例如:width: calc(100% - 10px);
3. vw: viewport width。1vw = viewport 宽度的 1%, 100vw = viewport width,
同样的还有 vh: viewport height。1vw = viewport 高度的 1%, 100vh = viewport height。
浏览器支持情况: 主流浏览器、IE10+
vw 和 vh 会随着viewport 的变化而变化,因此十分适合于自适应场景来使用。
方法四:使用负margin
首先修改页面结构,为自适应部分添加容器 .container, 同时改变左右部分的位置,如下:

设置样式:
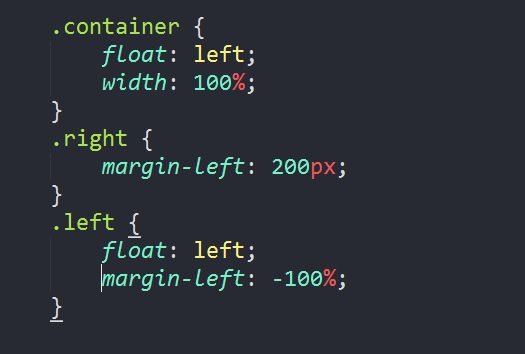
【分析】
1. 首先设置左边部分和右边部分左浮动,并为自适应部分(Right)设置宽度100%。此时的效果是这样的:

2. 设置左边部分左外边距为负100%,此时效果如下:

但是右边部分的宽度仍然为100%,部分内容被 Left 所覆盖。
3. 为 Right 部分添加左边距(即 Left 部分的宽度)

此时可以看到,Right 部分的内容居中显示了。
清除浮动的方式
在各种浏览器中显示效果也有可能不相同,这样让清除浮动更难了,下面总结8种清除浮动的方法,测试已通过 ie chrome firefox opera,需要的朋友可以参考下
清除浮动是每一个 web前台设计师必须掌握的机能。css清除浮动大全,共8种方法。
浮动会使当前标签产生向上浮的效果,同时会影响到前后标签、父级标签的位置及 width height 属性。而且同样的代码,在各种浏览器中显示效果也有可能不相同,这样让清除浮动更难了。解决浮动引起的问题有多种方法,但有些方法在浏览器兼容性方面还有问题。
下面总结8种清除浮动的方法(测试已通过 ie chrome firefox opera,后面三种方法只做了解就可以了):
1,父级div定义 height
复制代码
代码如下:
div2
原理:父级div手动定义height,就解决了父级div无法自动获取到高度的问题。
优点:简单、代码少、容易掌握
缺点:只适合高度固定的布局,要给出精确的高度,如果高度和父级div不一样时,会产生问题
建议:不推荐使用,只建议高度固定的布局时使用
2,结尾处加空div标签 clear:both
复制代码
代码如下:
div2
原理:添加一个空div,利用css提高的clear:both清除浮动,让父级div能自动获取到高度
优点:简单、代码少、浏览器支持好、不容易出现怪问题
缺点:不少初学者不理解原理;如果页面浮动布局多,就要增加很多空div,让人感觉很不好
建议:不推荐使用,但此方法是以前主要使用的一种清除浮动方法
3,父级div定义 伪类:after 和 zoom
复制代码
代码如下:
div2
原理:IE8以上和非IE浏览器才支持:after,原理和方法2有点类似,zoom(IE转有属性)可解决ie6,ie7浮动问题
优点:浏览器支持好、不容易出现怪问题(目前:大型网站都有使用,如:腾迅,网易,新浪等等)
缺点:代码多、不少初学者不理解原理,要两句代码结合使用才能让主流浏览器都支持。
建议:推荐使用,建议定义公共类,以减少CSS代码。
4,父级div定义 overflow:hidden
复制代码
代码如下:
div2
原理:必须定义width或zoom:1,同时不能定义height,使用overflow:hidden时,浏览器会自动检查浮动区域的高度
优点:简单、代码少、浏览器支持好
缺点:不能和position配合使用,因为超出的尺寸的会被隐藏。
建议:只推荐没有使用position或对overflow:hidden理解比较深的朋友使用。
5,父级div定义 overflow:auto
复制代码
代码如下:
div2
原理:必须定义width或zoom:1,同时不能定义height,使用overflow:auto时,浏览器会自动检查浮动区域的高度
优点:简单、代码少、浏览器支持好
缺点:内部宽高超过父级div时,会出现滚动条。
建议:不推荐使用,如果你需要出现滚动条或者确保你的代码不会出现滚动条就使用吧。
6,父级div 也一起浮动
复制代码
代码如下:
div2
原理:所有代码一起浮动,就变成了一个整体
优点:没有优点
缺点:会产生新的浮动问题。
建议:不推荐使用,只作了解。
7,父级div定义 display:table
复制代码
代码如下:
div2
原理:将div属性变成表格
优点:没有优点
缺点:会产生新的未知问题。
建议:不推荐使用,只作了解。
8,结尾处加 br标签 clear:both
复制代码
代码如下:
div2
原理:父级div定义zoom:1来解决IE浮动问题,结尾处加 br标签 clear:both
建议:不推荐使用,只作了解。
Js继承
大多OO语言都支持两种继承方式: 接口继承和实现继承 ,而ECMAScript中无法实现接口继承,ECMAScript只支持实现继承,而且其实现继承主要是依靠原型链来实现,下文给大家技术js实现继承的六种方式,需要的朋友参考下
前言:大多OO语言都支持两种继承方式: 接口继承和实现继承 ,而ECMAScript中无法实现接口继承,ECMAScript只支持实现继承,而且其实现继承主要是依靠 原型链 来实现。
1.原型链
基本思想:利用原型让一个引用类型继承另外一个引用类型的属性和方法。
构造函数,原型,实例之间的关系:每个构造函数都有一个原型对象,原型对象包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。
原型链实现继承例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function SuperType() { this.property = true; } SuperType.prototype.getSuperValue = function() { return this.property; } function subType() { this.property = false; } //继承了SuperType SubType.prototype = new SuperType(); SubType.prototype.getSubValue = function (){ return this.property; } var instance = new SubType(); console.log(instance.getSuperValue());//true |
2.借用构造函数
基本思想:在子类型构造函数的内部调用超类构造函数,通过使用call()和apply()方法可以在新创建的对象上执行构造函数。
例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 |
function SuperType() { this.colors = ["red","blue","green"]; } function SubType() { SuperType.call(this);//继承了SuperType } var instance1 = new SubType(); instance1.colors.push("black"); console.log(instance1.colors);//"red","blue","green","black" var instance2 = new SubType(); console.log(instance2.colors);//"red","blue","green" |
3.组合继承
基本思想:将原型链和借用构造函数的技术组合在一块,从而发挥两者之长的一种继承模式。
例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
function SuperType(name) { this.name = name; this.colors = ["red","blue","green"]; } SuperType.prototype.sayName = function() { console.log(this.name); } function SubType(name, age) { SuperType.call(this,name);//继承属性 this.age = age; } //继承方法 SubType.prototype = new SuperType(); Subtype.prototype.constructor = Subtype; Subtype.prototype.sayAge = function() { console.log(this.age); } var instance1 = new SubType("EvanChen",18); instance1.colors.push("black"); consol.log(instance1.colors);//"red","blue","green","black" instance1.sayName();//"EvanChen" instance1.sayAge();//18 var instance2 = new SubType("EvanChen666",20); console.log(instance2.colors);//"red","blue","green" instance2.sayName();//"EvanChen666" instance2.sayAge();//20 |
4.原型式继承
基本想法:借助原型可以基于已有的对象创建新对象,同时还不必须因此创建自定义的类型。
原型式继承的思想可用以下函数来说明:
?
| 1 2 3 4 5 |
function object(o) { function F(){} F.prototype = o; return new F(); } |
例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 |
var person = { name:"EvanChen", friends:["Shelby","Court","Van"]; }; var anotherPerson = object(person); anotherPerson.name = "Greg"; anotherPerson.friends.push("Rob"); var yetAnotherPerson = object(person); yetAnotherPerson.name = "Linda"; yetAnotherPerson.friends.push("Barbie"); console.log(person.friends);//"Shelby","Court","Van","Rob","Barbie" |
ECMAScript5通过新增Object.create()方法规范化了原型式继承,这个方法接收两个参数:一个用作新对象原型的对象和一个作为新对象定义额外属性的对象。
?
| 1 2 3 4 5 6 7 8 9 10 11 |
var person = { name:"EvanChen", friends:["Shelby","Court","Van"]; }; var anotherPerson = Object.create(person); anotherPerson.name = "Greg"; anotherPerson.friends.push("Rob"); var yetAnotherPerson = Object.create(person); yetAnotherPerson.name = "Linda"; yetAnotherPerson.friends.push("Barbie"); console.log(person.friends);//"Shelby","Court","Van","Rob","Barbie" |
5.寄生式继承
基本思想:创建一个仅用于封装继承过程的函数,该函数在内部以某种方式来增强对象,最后再像真正是它做了所有工作一样返回对象。
例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
function createAnother(original) { var clone = object(original); clone.sayHi = function () { alert("hi"); }; return clone; } var person = { name:"EvanChen", friends:["Shelby","Court","Van"]; }; var anotherPerson = createAnother(person); anotherPerson.sayHi();///"hi" |
6.寄生组合式继承
基本思想:通过借用函数来继承属性,通过原型链的混成形式来继承方法
其基本模型如下所示:
?
| 1 2 3 4 5 |
function inheritProperty(subType, superType) { var prototype = object(superType.prototype);//创建对象 prototype.constructor = subType;//增强对象 subType.prototype = prototype;//指定对象 } |
例子:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function SuperType(name){ this.name = name; this.colors = ["red","blue","green"]; } SuperType.prototype.sayName = function (){ alert(this.name); }; function SubType(name,age){ SuperType.call(this,name); this.age = age; } inheritProperty(SubType,SuperType); SubType.prototype.sayAge = function() { alert(this.age); } |
以上内容给大家介绍了javascript实现继承的六种方式,希望对大家有所帮助!
1.js原型(prototype)实现继承
代码如下
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
2.构造函数实现继承
代码如下:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
3.call , apply实现继承 -----很方便!
代码如下:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持脚本之家!
怎么去除url地址的参数
javascript 删除 url 中指定参数,并返回 url
前言
在之前写了一篇博文《javascript 操作 url 中 search 部分方法函数》.在这篇博文里面,我们通过写好的函数可以对url中的各种参数进行查询,设置.唯独,忘记了删除.
而今天就是遇到要删除某个参数的问题.郁闷,于是,写了这个函数.
实现代码
// 删除url中某个参数,并跳转function funcUrlDel(name){varloca = window.location;
varbaseUrl = loca.origin + loca.pathname +"?";
varquery = loca.search.substr(1);
if(query.indexOf(name)>-1) {
varobj = {}
vararr = query.split("&");
for(vari =0; i < arr.length; i++) {
arr[i] = arr[i].split("=");
obj[arr[i][0]] = arr[i][1];
};deleteobj[name];
varurl = baseUrl +JSON.stringify(obj).replace(/[\"\{\}]/g,"").replace(/\:/g,"=").replace(/\,/g,"&");
returnurl
};}功能:删除url中指定的参数,并返回删除参数后的完整url
使用方法
示例
url: http//xx.com/list?page=1&a=5
执行代码
funcUrlDel("page")
返回
http//xx.com/list?a=5
其他说明
会忽略 hash 值,如果需要,自行加上即可.
使用jquery获取url以及使用jquery获取url参数是我们经常要用到的操作,下面通过文字说明加代码分析的形式给大家解析,具体详情请看下文。
1、jquery获取url很简单,代码如下:
复制代码代码如下:
window.location.href;
其实只是用到了javascript的基础的window对象,并没有用jquery的知识。
2、jquery获取url参数比较复杂,要用到正则表达式,所以学好javascript正则式多么重要的事情
首先看看单纯的通过javascript是如何来获取url中的某个参数:
?
| 1 2 3 4 5 6 |
//获取url中的参数 function getUrlParam(name) { var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)"); //构造一个含有目标参数的正则表达式对象 var r = window.location.search.substr(1).match(reg); //匹配目标参数 if (r != null) return unescape(r[2]); return null; //返回参数值 } |
通过这个函数传递url中的参数名就可以获取到参数的值,比如url为
http://localhost:33064/WebForm2.aspx?reurl=WebForm1.aspx
我们要获取reurl的值,可以这样写:
复制代码代码如下:
var xx = getUrlParam('reurl');
明白了javascript获取url参数的方法,我们可以通过这个方法为jquery扩展一个方法来通过jquery获取url参数,下面的代码为jquery扩展了一个getUrlParam()方法
?
| 1 2 3 4 5 6 7 |
(function ($) { $.getUrlParam = function (name) { var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)"); var r = window.location.search.substr(1).match(reg); if (r != null) return unescape(r[2]); return null; } })(jQuery); |
为jquery扩展了这个方法了之后我们就可以通过如下方法来获取某个参数的值了:
复制代码代码如下:
var xx = $.getUrlParam('reurl');
完整代码:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
2014-4-23 修改
今天在用上面的方法获取url中的参数时,url中传递的中文参数在解析的时候无论怎么测试,获取的都是乱码。经过一番调试后发现,我再传递参数时,对汉字编码使用的是 encodeURI ,而上面的方法在解析参数编码时使用的是unescape ,修改为 decodeURI 就可以了。
附: W3School中的介绍:
JavaScript unescape() 函数
unescape() 函数可对通过 escape() 编码的字符串进行解码。
| 参数 |
描述 |
| string |
必需。要解码或反转义的字符串。 |
说明
该函数的工作原理是这样的:通过找到形式为 %xx 和 %uxxxx 的字符序列(x 表示十六进制的数字),用 Unicode 字符 \u00xx 和 \uxxxx 替换这样的字符序列进行解码。
提示和注释
注释:ECMAScript v3 已从标准中删除了 unescape() 函数,并反对使用它,因此应该用 decodeURI() 和 decodeURIComponent() 取而代之。
综上: javascript对参数编码解码方法要一致:
escape() unescape()
encodeURI() decodeURI()
encodeURIComponent() decodeURIComponent()
网上找的另一种javascript获取url中参数的方法:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
jquery 取url参数和在url加参数
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
(function ($) { $.extend({ Request: function (m) { var sValue = location.search.match(new RegExp("[\?\&]" + m + "=([^\&]*)(\&?)", "i")); return sValue ? sValue[1] : sValue; }, UrlUpdateParams: function (url, name, value) { var r = url; if (r != null && r != 'undefined' && r != "") { value = encodeURIComponent(value); var reg = new RegExp("(^|)" + name + "=([^&]*)(|$)"); var tmp = name + "=" + value; if (url.match(reg) != null) { r = url.replace(eval(reg), tmp); } else { if (url.match("[\?]")) { r = url + "&" + tmp; } else { r = url + "?" + tmp; } } } return r; }
}); })(jQuery); |
使用方法
dev.zhang.com/IOF.Signup/index_uscn_chs.html?act=1
1、取值使用
$.Request("act") = 1
2、url加参数
$.UrlUpdateParams(window.location.href, "mid", 11111),
结果window.location.href?mid=11111
盒子居中
布局中经常会遇到让一个盒子水平且垂直居中的情况,以下总结了几种居中方法:
- margin固定宽高居中
- 负margin居中
- 绝对定位居中
- table-cell居中
- flex居中
- transform居中
- 不确定宽高居中(绝对定位百分数)
- button居中
不兼容IE低版本的可以用其他方法hack。
不多说,直接上代码:
大多数方法的html都相同,所以写一个了,不同的再单独写出来。
(demo中有代码和效果)
HTML:
- margin固定宽高居中
这种定位方法,纯粹是靠宽高和margin拼出来的,不灵活。
CSS:
#container {
width: 600px;
height: 500px;
border: 1px solid #000;
margin: auto;
}
#box {
width: 200px;
height: 200px;
margin: 150px 200px;
background-color: #0ff;
}
点击查看demo
- 负margin居中
利用负的margin来进行居中,需要知道固定宽高,限制比较大。
CSS:
#container {
position: relative;
width: 600px;
height: 500px;
border: 1px solid #000;
margin: auto;
}
#box {
position: absolute;
width: 200px;
height: 200px;
left: 50%;
top: 50%;
margin: -100px -100px;
background-color: #0ff;
}
点击查看demo
- 绝对定位居中
利用绝对定位居中,非常常用的一种方法。
CSS:
#container {
position: relative;
width: 600px;
height: 500px;
border: 1px solid #000;
margin: auto;
}
#box {
position: absolute;
width: 200px;
height: 200px;
left: 0;
top: 0;
right: 0;
bottom: 0;
margin: auto;
background-color: #0ff;
}
点击查看demo
- table-cell居中
利用table-cell来控制垂直居中。
CSS:
#container {
display: table-cell;
width: 600px;
height: 500px;
vertical-align: middle;
border: 1px solid #000;
}
#box {
width: 200px;
height: 200px;
margin: 0 auto;
background-color: #0ff;
}
点击查看demo
- flex居中
CSS3中引入的新布局方式,比较好用。缺点:IE9以及IE9一下不兼容。
CSS:
#container {
display: -webkit-flex;
display: flex;
-webkit-align-items: center;
align-items: center;
-webkit-justify-content: center;
justify-content: center;
width: 600px;
height: 500px;
border: 1px solid #000;
margin: auto;
}
#box {
width: 200px;
height: 200px;
background-color: #0ff;
}
点击查看demo
- transform居中
这种方法灵活运用CSS中transform属性,较为新奇。缺点是IE9下不兼容。
CSS:
#container {
position: relative;
width: 600px;
height: 600px;
border: 1px solid #000;
margin: auto;
}
#box {
position: relative;
top: 50%;
left: 50%;
width: 200px;
height: 200px;
transform: translate(-50%, -50%);
-webkit-transform: translate(-50%, -50%);
-ms-transform: translate(-50%, -50%);
-moz-transform: translate(-50%, -50%);
background-color: #0ff;
}
点击查看demo
- 不确定宽高居中(绝对定位百分数)
这种不确定宽高的居中,较为灵活。只需要保证left和right的百分数一样就可以实现水平居中,保证top和bottom的百分数一样就可以实现垂直居中。
CSS:
#container {
position: relative;
width: 600px;
height: 500px;
border: 1px solid #000;
margin: auto;
}
#box {
position: absolute;
left: 30%;
right: 30%;
top: 25%;
bottom: 25%;
background-color: #0ff;
}
点击查看demo
- button居中
利用button做外容器,里边的块元素会自动垂直居中,只需要控制一下水平居中就可以达到效果。
HTML:
CSS:
button {
width: 600px;
height: 500px;
border: 1px solid #000;
}
div {
width: 200px;
height: 200px;
margin: 0 auto;
background-color: #0ff;
}
说到让一个div水平居中,立马想到最常用的就是margin:0 auto;但是这个的前提是必须知道盒子的宽度,盒子居中主要有两种情况:
一.确定盒子的宽度,解决办法有:
1.1 margin:0 auto;
1.2 position:relative;left:50%;margin-left:-0.5*width;(用绝对定位也可以)
二.不确定盒子宽度的,而且盒子宽度可变的,方法如下
2.1 position:relative:left:50%;transform:translateX(-50%);-webkit-transform:translateX(-50%);-moz-transform:translateX(-50%);//这里的50%是指盒子本身的50%;
2.2 width:fit-content;width:-moz-fit-content;width:-webket-fit-content;margin:auto;
1.第一种
利用margin,div1的宽减去div2的宽就是div2margin-left的数值:(100-40)/2=30
div1的高减去div2的高就是div2margin-top的数值:(100-40)/2=30
按 Ctrl+C 复制代码
demo
第一种
第2种
利用css的 position属性,把div2相对于div1的top、left都设置为50%,然后再用margin-top设置为div2的高度的负一半拉回来,用marg-left设置为宽度的负一半拉回来,css如下设置
demo
第二种
第三种
【】【】还是用css的position属性,如下的html
demo
第三种
第四种
利用css3的新增属性table-cell, vertical-align:middle;
demo
第四种
第五种方法
demo
div居中方法
第五种方法
第六种方法
利用flexbox布局
直接在父元素上使用flexbox的布局
demo
第六种方法
第七种方法
利用transform的属性,注意子绝父相定位
缺点:需要支持Html5
demo
我是外部盒子
我要居中
第七种
第八种
两者都要固定定位,不常用
缺点:需要设置position属性,网页复杂时容易扰乱页面布局,而且只是元素的起始位置居中
demo
我要居中
第八种方法
Js实现eventHandler
js事件的监听器的使用
1、当同一个对象使用.onclick的写法触发多个方法的时候,后一个方法会把前一个方法覆盖掉,也就是说,在对象的onclick事件发生时,只会执行最后绑定的方法。而用事件监听则不会有覆盖的现象,每个绑定的事件都会被执行。如下:
[javascript] view plain copy
- var btn = document.getElementById("yuanEvent");
- btn.onclick = function(){
- alert("第一个事件");
- }
- btn.onclick = function(){
- alert("第二个事件");
- }
- btn.onclick = function(){
- alert("第三个事件");
- }
- }
最后只输出:第三个事件,因为后一个方法都把前一个方法覆盖掉了。
原生态的事件绑定函数addEventListener:
[javascript] view plain copy
- var eventOne = function(){
- alert("第一个监听事件");
- }
- function eventTwo(){
- alert("第二个监听事件");
- }
- window.onload = function(){
- var btn = document.getElementById("yuanEvent");
- //addEventListener:绑定函数
- btn.addEventListener("click",eventOne);
- btn.addEventListener("click",eventTwo);
- }
输出:第一个监听事件 和 第二个监听事件
2、采用事件监听给对象绑定方法后,可以解除相应的绑定,写法如下:
[javascript] view plain copy
- var eventOne = function(){
- alert("第一个监听事件");
- }
- function eventTwo(){
- alert("第二个监听事件");
- }
- window.onload = function(){
- var btn = document.getElementById("yuanEvent");
- btn.addEventListener("click",eventOne);
- btn.addEventListener("click",eventTwo);
- btn.removeEventListener("click",eventOne);
- }
输出:第二个监听事件
3、解除绑定事件的时候一定要用函数的句柄,把整个函数写上是无法解除绑定的。
错误写法:
[javascript] view plain copy
- btn.addEventListener("click",function(){
- alert(11);
- });
- btn.removeEventListener("click",function(){
- alert(11);
- });
正确写法:
[javascript] view plain copy
- btn.addEventListener("click",eventTwo);
- btn.removeEventListener("click",eventOne);
总结:对函数进行封装后的监听事件如下,兼容各大主流浏览器。
[javascript] view plain copy
- /*
- * addEventListener:监听Dom元素的事件
- *
- * target:监听对象
- * type:监听函数类型,如click,mouseover
- * func:监听函数
- */
- function addEventHandler(target,type,func){
- if(target.addEventListener){
- //监听IE9,谷歌和火狐
- target.addEventListener(type, func, false);
- }else if(target.attachEvent){
- target.attachEvent("on" + type, func);
- }else{
- target["on" + type] = func;
- }
- }
- /*
- * removeEventHandler:移除Dom元素的事件
- *
- * target:监听对象
- * type:监听函数类型,如click,mouseover
- * func:监听函数
- */
- function removeEventHandler(target, type, func) {
- if (target.removeEventListener){
- //监听IE9,谷歌和火狐
- target.removeEventListener(type, func, false);
- } else if (target.detachEvent){
- target.detachEvent("on" + type, func);
- }else {
- delete target["on" + type];
- }
- }
- var eventOne = function(){
- alert("第一个监听事件");
- }
- function eventTwo(){
- alert("第二个监听事件");
- }
- window.onload = function(){
- var bindEventBtn = document.getElementById("bindEvent");
- //监听eventOne事件
- addEventHandler(bindEventBtn,"click",eventOne);
- //监听eventTwo事件
- addEventHandler(bindEventBtn,"click",eventTwo );
- //监听本身的事件
- addEventHandler(bindEventBtn,"click",function(){
- alert("第三个监听事件");
- });
- //取消第一个监听事件
- removeEventHandler(bindEventBtn,"click",eventOne);
- //取消第二个监听事件
- removeEventHandler(bindEventBtn,"click",eventTwo);
- }
[javascript] view plain copy
实例:
[html] view plain copy
- >
-
-
</span></strong><span style="color:#000000;">Event</span><strong><span style="color:#993300;"> -
- function addEventHandler(target,type,func){
- if(target.addEventListener){
- //监听IE9,谷歌和火狐
- target.addEventListener(type, func, false);
- }else if(target.attachEvent){
- target.attachEvent("on" + type, func);
- }else{
- target["on" + type] = func;
- }
- }
- function removeEventHandler(target, type, func) {
- if (target.removeEventListener){
- //监听IE9,谷歌和火狐
- target.removeEventListener(type, func, false);
- } else if (target.detachEvent){
- target.detachEvent("on" + type, func);
- }else {
- delete target["on" + type];
- }
- }
- var eventOne = function(){
- alert("第一个监听事件");
- }
- function eventTwo(){
- alert("第二个监听事件");
- }
- window.onload = function(){
- var bindEventBtn = document.getElementById("bindEvent");
- //监听eventOne事件
- addEventHandler(bindEventBtn,"click",eventOne);
- //监听eventTwo事件
- addEventHandler(bindEventBtn,"click",eventTwo );
- //监听本身的事件
- addEventHandler(bindEventBtn,"click",function(){
- alert("第三个监听事件");
- });
- //取消第一个监听事件
- removeEventHandler(bindEventBtn,"click",eventOne);
- //取消第二个监听事件
- removeEventHandler(bindEventBtn,"click",eventTwo);
- }
-
-
js事件(Event)知识整理
转载 2012-10-11 作者: 我要评论
事件(Event)知识整理,本文由网上资料整理而来,需要的朋友可以参考下
鼠标事件
鼠标移动到目标元素上的那一刻,首先触发mouseover
之后如果光标继续在元素上移动,则不断触发mousemove
如果按下鼠标上的设备(左键,右键,滚轮……),则触发mousedown
当设备弹起的时候触发mouseup
目标元素的滚动条发生移动时(滚动滚轮/拖动滚动条。。)触发scroll
滚动滚轮触发mousewheel,这个要区别于scroll
鼠标移出元素的那一刻,触发mouseout
事件注册
平常我们绑定事件的时候用dom.onxxxx=function(){}的形式
这种方式是给元素的onxxxx属性赋值,只能绑定有一个处理句柄。
但很多时候我们需要绑定多个处理句柄到一个事件上,而且还可能要动态的增删某个处理句柄
下面的事件注册方式就能解决这个需求。
先介绍一下四个方法
复制代码代码如下:
//IE以外
target.addEventListener(type,listener,useCapture)
target.removeEventListener(type,listener,useCapture);
target :文档节点、document、window 或 XMLHttpRequest。
type :字符串,事件名称,不含“on”,比如“click”、“mouseover”、“keydown”等。
listener :实现了 EventListener 接口或者是 JavaScript 中的函数。
useCapture :是否使用捕捉,一般用 false。
//IE
target.attachEvent(type, listener);
target.detachEvent(type, listener);
target :文档节点、document、window 或 XMLHttpRequest。
type :字符串,事件名称,含“on”,比如“onclick”、“onmouseover”、“onkeydown”等。
listener :实现了 EventListener 接口或者是 JavaScript 中的函数。
两者使用的原理:可对执行的优先级不一样,实例讲解如下:
ele.attachEvent("onclick",method1);
ele.attachEvent("onclick",method2);
ele.attachEvent("onclick",method3);
执行顺序为method3->method2->method1
ele.addEventListener("click",method1,false);
ele.addEventListener("click",method2,false);
ele.addEventListener("click",method3,false);
执行顺序为method1->method2->method3
兼容后的方法
var func = function(){};
//例:addEvent(window,"load",func)
function addEvent(elem, type, fn) {
if (elem.attachEvent) {
elem.attachEvent('on' + type, fn);
return;
}
if (elem.addEventListener) {
elem.addEventListener(type, fn, false);
}
}
//例:removeEvent(window,"load",func)
function removeEvent(elem, type, fn) {
if (elem.detachEvent) {
elem.detachEvent('on' + type, fn);
return;
}
if (elem.removeEventListener) {
elem.removeEventListener(type, fn, false);
}
}
获取事件对象和事件源(触发事件的元素)
复制代码代码如下:
function eventHandler(e){
//获取事件对象
e = e || window.event;//IE和Chrome下是window.event FF下是e
//获取事件源
var target = e.target || e.srcElement;//IE和Chrome下是srcElement FF下是target
}
取消事件默认行为(例如点击一个后不跳转页面而是执行一个函数)
复制代码代码如下:
function eventHandler(e) {
e = e || window.event;
// 防止默认行为
if (e.preventDefault) {
e.preventDefault();//IE以外
} else {
e.returnValue = false;//IE
//注意:这个地方是无法用return false代替的
//return false只能取消元素
}
}
阻止事件冒泡
复制代码代码如下:
function myParagraphEventHandler(e) {
e = e || window.event;
if (e.stopPropagation) {
e.stopPropagation();//IE以外
} else {
e.cancelBubble = true;//IE
}
}
复制代码代码如下: 复制代码代码如下: 在JS中创建对象有很多种方法,而创建自定义类型的最常见的方式,就是使用组合使用构造函数模式和原型模式创建对象。构造函数模式用于定义实例属性,而原型模式用于定义方法和共享的属性,那么来看看为什么这种方式是最常用的。 依次来看: function createPerson(name,age,gender){ var obj = new Object(); obj.name = name; obj.age = age; obj.gender = gender; obj.sayName = function(){ alert(this.name); }; return obj; } //接下来就可以创建对象了var person = createPerson("Stan",0000,"male"); 如果创建多个这种类似的对象,当然很ok啦,但是有更好的模式创建对象。 function Person(name,age,gender){ this.name = name; this.age = age; this.gender = gender; this.sayName = function(){ alert(this.name); }; } //然后可以用new操作符来创建Person的新实例 var person = new Person("Stan",0000,"male"); //最直观的就是代码比工厂模式少吧。 //另外,创建自定义的构造函数意味着将来可以将它的实例标识为一种特定类型,这是构造函数模式胜过工厂模式的地方(努力理解中。) //也可以像下面这种创建并调用 Person("Stan",0000,"male"); window.sayName(); //或是在另一个对象的作用域中调用 var obj = new Object(); Person.call(obj,"Stan",0000,"male"); obj.sayName(); //这里是在obj对象的作用域中调用Person(),因此调用后obj就拥有了所有属性和sayName()方法 这里说说构造函数模式的问题,定义在构造函数中的方法在每次实例化的时候都会被创建一次,并且每次被创建的方法都是一个新的对象(JS中函数即对象),即创建两个完成同样任务的Function实例是没有必要的,也就是说,如果一个方法可以被共享使用的话,不应该这么做。如果写成下面这样: function Person(name,age,gender){ this.name = name; this.age = age; this.gender = gender; this.sayName = sayName; } function sayName(){ alert(this.name); } 这样把sayName()定义成全局函数,虽然解决了多个函数做同一样件事情而不用每次创建的问题,但是假如需要N个全局函数,那么我们这个自定义的引用类型就没有丝毫的封装性可言了。所以有更好的原型模式可以解决这个问题 3.原型模式 function Person(){} Person.prototype.name = "Stan"; Person.prototype.age = 0000; Person.prototype.gender = "male"; Person.prototype.sayName = function(){ alert(this.name); } var person = new Person(); person.sayName(); //原型对象中的所有属性和方法都是可以被实例所共享的 当我们在调用person.sayName()方法时,会先后执行两次搜索,先从对象实例本身开始,如果在实例中找到该方法,则调用 ,若没有找到,会继续搜索指针指向的原型对象,找到则调用方法。有一个问题,如果我们在实例中添加一个属性,而该属性与实例原型中的一个属性同名,该属性将会屏蔽掉原型中的那个属性,就像下面这样: function Person(){} Person.prototype.name = "Stan"; var person = new Person(); person.name = "Joe"; alert(person.name);//结果是Joe 即使将这个name属性设置为null,也只会在实例中设置这个属性,而不会恢复其指向原型的连接 。可以使用delete操作符完全的删除实例属性,从而可以重新访问到原型中的属性。像下面这样: function Person(){} Person.prototype.name = "Stan"; var person = new Person(); person.name = null; alert(person.name);//结果是null,而不是Stan //可以这样做: delete person.name; alert(person.name); 另外还可以把原型语法像下面这样写: function Person(){} Person.prototype = { name : "Stan", age : 0000, gender : "male", sayName : function(){ alert(this.name); } }; 这种写法实际上是重写了原型对象,所以接下来看一个问题,即原型的动态性 function Person(){} var person = new Person(); Person.prototype.name = "Stan"; alert(person.name); 虽然person实例是在添加新属性之前创建的,但是仍然可以立即在实例中访问到name属性,但是如果全部重写了原型对象,就会出问题了,像下面这样: function Person(){} var person = new Person(); Person.prototype = { name : "Stan", age : 0000, gender : "male", sayName : function(){ alert(this.name); } }; alert(person.name);//undefined 这是为什么呢?因为重写原型切断了现有原型(重写后的原型)与任何之前已经存在的对象实例之间的联系,person引用的仍然是最初的原型,这里person实例最初的原型中除了默认的一些属性外,是没有name属性的,所以就会undefined咯! 原型对象看似还可以,但它也是有问题的,什么问题呢,就是其共享的本性,分析下,原型中所有属性是被很多实例共享的,这种共享对于函数非常合适,对于那些包含基本值的属性也还行,因为我们还可以通过在实例上添加一个同名属性来隐藏掉原型中的对应属性(不会影响到其它的实例的属性),但是如果包含引用类型值的属性来说,问题就来了,看下面: function Person(){} Person.prototype = { colors : ["red","green","pink"] }; var person1 = new Person(); person1.colors.push("black"); var person2 = new Person(); alert(person2.colors); // red,green,pink,black 看到问题了吧,大多数时候,实例一般都是要属于自己的全部属性的,即我们不会这么单独使用原型模式,所以这才到今天我们要说的主题:组合使用构造函数模式和原型模式创建对象 function Person(name,age,gender){ this.name = name; this.age = age; this.gender = gender; this.colors = ["red","green","pink"]; } Person.prototype = { sayName : function(){ alert(this.name); } } var person1 = new Person("Stan",0000,"male"); var person2 = new Person("Joe",1111,"female"); person1.colors.push("black"); alert(person1.colors); // red,green,pink,black alert(person2.colors); // red,green,pink alert(person1.sayName == person2.sayName); // true 先说到这里吧。 这么基础的东西实在不应该再记录了,不过嘛,温故知新~就先从数据类型开始吧 js六大数据类型:number、string、object、Boolean、null、undefined string: 由单引号或双引号来说明,如"string" number:什么整数啊浮点数啊都叫数字,你懂的~ Boolean: 就是true和false啦 undefined:未定义,就是你创建一个变量后却没给它赋值~ null: 故名思久,null就是没有,什么也不表示 object: 这个我也很难解释的说。就是除了上面五种之外的类型 --------------------上面的都是浮云,下面的才是神马------------------------------ 数据类型判断之 typeof typeof可以解决大部分的数据类型判断,是一个一元运算,放在一个运算值之前,其返回值为一个字符串,该字符串说明运算数的类型,所以判断某个是否为String类型,可以直接 if(typeof(你的值) == "string"){} 以下是各种数据类型返回结果: ? 1 2 3 4 5 6 7 8 9 10 var a="string"; console.log(a); //string var a=1; console.log(a); //number var a=false; console.log(a); //boolean var a; console.log(typeof a); //undfined var a = null; console.log(typeof a); //object var a = document; console.log(typeof a); //object var a = []; console.log(a); //object var a = function(){}; console.log(typeof a) //function 除了可以判断数据类型还可以判断function类型 这样一来就很明显了,除了前四个类型外,null、对象、数组返回的都是object类型; 对于函数类型返回的则是function,再比如typeof(Date),typeof(eval)等。 然后这里就可以再引申出另一个灰常热门并且解决方法已普遍存在的问题,如何判断数据是个数组类型? ---------------------------------------其实这才是我的目的,咩~---------------------------------------------- js判断数组类型的方法 方法一之 instanceof instance,故名思义,实例,例子,所以instanceof 用于判断一个变量是否某个对象的实例,是一个三目运算式---和typeof最实质上的区别 a instanceof b?alert("true"):alert("false") //注意b值是你想要判断的那种数据类型,不是一个字符串,比如Array 举个栗子: ? 1 2 var a=[]; console.log(a instanceof Array) //返回true 方法二之 constructor 在W3C定义中的定义:constructor 属性返回对创建此对象的数组函数的引用 就是返回对象相对应的构造函数。从定义上来说跟instanceof不太一致,但效果都是一样的 如: (a instanceof Array) //a是否Array的实例?true or false (a.constructor == Array) // a实例所对应的构造函数是否为Array? true or false 举个栗子: ? 1 2 3 4 5 6 7 8 function employee(name,job,born){ this.name=name; this.job=job; this.born=born; } var bill=new employee("Bill Gates","Engineer",1985); console.log(bill.constructor); //输出function employee(name, jobtitle, born){this.name = name; this.jobtitle = job; this.born = born;} 那么判断各种类型的方法就是: ? 1 2 3 4 5 console.log([].constructor == Array); console.log({}.constructor == Object); console.log("string".constructor == String); console.log((123).constructor == Number); console.log(true.constructor == Boolean); -------------------------------------以下不是原创-------------------------------------- 较为严谨并且通用的方法: ? 1 2 3 4 function isArray(object){ return object && typeof object==='object' && Array == object.constructor; } !!注意: 使用instaceof和construcor,被判断的array必须是在当前页面声明的!比如,一个页面(父页面)有一个框架,框架中引用了一个页面(子页面),在子页面中声明了一个array,并将其赋值给父页面的一个变量,这时判断该变量,Array == object.constructor;会返回false; 原因: 1、array属于引用型数据,在传递过程中,仅仅是引用地址的传递。 方法三之 特性判断法 以上方法均有一定的缺陷,但要相信人民大众的智慧是无所不能及的,我们可根据数组的一些特性来判断其类型 ? 1 2 3 4 5 6 7 function isArray(object){ return object && typeof object==='object' && typeof object.length==='number' && typeof object.splice==='function' && //判断length属性是否是可枚举的 对于数组 将得到false !(object.propertyIsEnumerable('length')); } 有length和splice并不一定是数组,因为可以为对象添加属性,而不能枚举length属性,才是最重要的判断因子。 ps: 在这里普及下 propertyIsEnumerable 方法: object. propertyIsEnumerable(proName) 判断指定的属性是否可列举 备注:如果 proName 存在于 object 中且可以使用一个 For…In 循环穷举出来,那么 propertyIsEnumerable 属性返回 true。如果 object 不具有所指定的属性或者所指定的属性不是可列举的,那么 propertyIsEnumerable 属性返回 false。 propertyIsEnumerable 属性不考虑原型链中的对象。 示例: ? 1 2 var a = new Array("apple", "banana", "cactus"); document.write(a.propertyIsEnumerable(1)); 方法四之 最简单的方法 ? 1 2 3 function isArray(o) { return Object.prototype.toString.call(o) === ‘[object Array]‘; } 以上就是本文的全部内容,了解更多JavaScript的语法,大家可以查看:《JavaScript 参考教程》、《JavaScript代码风格指南》,也希望大家多多支持脚本之家。 因为无论是数组还是对象,对于typeof的操作返回值都为object,所以就有了区分数组类型和对象类型的需要: 方一:通过length属性:一般情况下对象没有length属性值,其值为undefiend,而数组的length值为number类型 缺点:非常不实用,当对象的属性存在length,且其值为number(比如类数组),则该方法失效,不建议使用,看看即可。 *方二:通过instanceof来判断区分 *方三:通过constructor *方四:通过toString()方法,数组原型和对象原型定义的toString()方法不同 原理参考:http://www.cnblogs.com/ziyunfei/archive/2012/11/05/2754156.html 方五:随便找一个数组仅有的方法,来判断数组和对象谁有该方法即可(样例以sort来举例) 总结:方法应用权重: 优先使用方四toString,因为该方法几乎无缺陷。 次之可以使用方二instanceof和方三constructor 剩下的方法玩玩即可,不实用 判断objectName是否是数组 基本数据类型也可以使用此方法。 1、2判断有误差。 a)length 有length和splice并不一定是数组,因为可以为对象添加属性,而不能枚举length属性,才是最重要的判断因子。 ES5方法 获取this对象的[[Class]]属性的值.[Class]]是一个内部属性,所有的对象都拥有该属性. 表明该对象的类型 其中 变量 这就是 ps: 关于 typeof 操作符 由于 需要注意的是 Undefined Null 如果定义的变量准备在将来用于保存对象,那么最好将该变量初始化为 实际上,undefined值是派生自null值的,因此ECMA-262规定对它们的相等性测试要返回true。 尽管null和undefined有这样的关系,但它们的用途完全不同。无论在什么情况下都没有必要把一个变量的值显式地设置为undefined,可是同样的规则对null却不适用。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存null值。这样做不仅可以体现null作为空对象指针的惯例,而且也有助于进一步区分null和undefined。 Boolean 该类型只有两个字面值:true和false。这两个值与数字值不是一回事,因此true不一定等于1,而false也不一定等于0。 虽然Boolean类型的字面值只有两个,但JavaScript中所有类型的值都有与这两个Boolean值等价的值。要将一个值转换为其对应的Boolean值,可以调用类型转换函数Boolean(),例如: 在这个例子中,字符串message被转换成了一个Boolean值,该值被保存在messageAsBoolean变量中。可以对任何数据类型的值调用Boolean()函数,而且总会返回一个Boolean值。至于返回的这个值是true还是false,取决于要转换值的数据类型及其实际值。下表给出了各种数据类型及其对象的转换规则。 数据类型 转换为true的值 转换为false的值 Boolean true false String 任何非空的字符串 ""(空字符串) Number 任何非0数值(包括无穷大) 0和NAN Object 任何对象 null Undefined 不适用 undefined 运行这个示例,就会显示一个警告框,因为字符串message被自动转换成了对应的Boolean值(true)。由于存在这种自动执行的Boolean转换,因此确切地知道在流控制语句中使用的是什么变量至关重要。 ps:使用!!操作符转换布尔值 对null与undefined等其他用隐式转换的值,用!操作符时都会产生true的结果,所以用两个感叹号的作用就在于将这些值转换为“等价”的布尔值; 这段例子,演示了在undifined和null时,用一个感叹号返回的都是true,用两个感叹号返回的就是false,所以两个感叹号的作用就在于,如果明确设置了变量的值(非null/undifined/0/”“等值),结果就会根据变量的实际值来返回,如果没有设置,结果就会返回false。 还有其他的小技巧,可以参考这12个JavaScript技巧 Number 这种类型用来表示整数和浮点数值,还有一种特殊的数值,即NaN(非数值 Not a Number)。这个数值用于表示一个本来要返回数值的操作数未返回数值的情况(这样就不会抛出错误了)。例如,在其他编程语言中,任何数值除以0都会导致错误,从而停止代码执行。但在JavaScript中,任何数值除以0会返回NaN,因此不会影响其他代码的执行。 NaN本身有两个非同寻常的特点。首先,任何涉及NaN的操作(例如NaN/10)都会返回NaN,这个特点在多步计算中有可能导致问题。其次,NaN与任何值都不相等,包括NaN本身。例如,下面的代码会返回false。 String String类型用于表示由零或多个16位Unicode字符组成的字符序列,即字符串。字符串可以由单引号(')或双引号(")表示。 String类型的特殊性 string类型有些特殊,因为字符串具有可变的大小,所以显然它不能被直接存储在具有固定大小的变量中。由于效率的原因,我们希望JS只复制对字符串的引用,而不是字符串的内容。但是另一方面,字符串在许多方面都和基本类型的表现相似,而字符串是不可变的这一事实(即没法改变一个字符串值的内容),因此可以将字符串看成行为与基本类型相似的不可变引用类型 Boolean、Number、String 这三个是Javascript中的基本包装类型,也就是这三个其实是一个构造函数,他们是Function的实例,是引用类型,至于这里的String与以上说的String是同名,是因为其实上文说的String是指字符串,这里的String指的是String这个构造函数,上面那么写,是为了更好的理解,因为Javascript是松散类型的。我们可以看下String实例化的例子: 至于author这个会有length,substring等等这些方法,其实string只是String的一个实例,类似于C#中的String,和string. 注意,typeof 变量 如果值是"string" 的话,也就是这个变量是字符串,在Javascript中,字符串是基本类型,而在C#或Java中,字符串是引用类型,但是Javascript中的String是引用类型,因为它是Javascript中定义好的基本包装类型,在C#中,String跟string其实是一样的。 本帖只是简要的copy了一些JavaScript高级程序设计(第三版)内容,外加了自己侧重的角度,看本帖的朋友还是要看书啊,这里只是做个参考。 1、Symbol概述 JavaScript基本数据类型有6种:Undefined、Null、Boolean、String、Number、Object。 ES6新增了一种数据类型:Symbol,表示独一无二的值,Symbol最大的用途是用来定义对象的唯一属性名。 ES5的对象属性名都是字符串,容易造成属性名的冲突。如使用了一个其他人提供的对象,但又想为其添加新的方法(mixin模式),那么新方法的名字有可能与已有方法产生冲突。因此,需要保证每个属性的名字都是独一无二,以防止属性名的冲突。这就是ES6引入Symbol的原因。 Symbol值通过Symbol函数生成。 [javascript] view plain copy typeof运算符用于Symbol类型值,返回symbol。 [javascript] view plain copy Symbol类型的值是一个独一无二的值,Symbol函数的参数只是表示对当前Symbol值的描述,因此相同参数的Symbol函数的返回值是不相等的。 [javascript] view plain copy Symbol不是一个构造函数,如果用new Symbol会报错(Symbol是一个原始类型的值,不是对象)。 [javascript] view plain copy 由于Symbol值不是对象,所以不能添加属性。 [javascript] view plain copy Symbol值不能与其他类型的值进行运算。 [javascript] view plain copy Symbol值可以显式转为字符串,也可以转为布尔值,但是不能转为数值。 [javascript] view plain copy 2、作为对象属性名的Symbol 由于每一个Symbol值都是不相等的,这意味着Symbol值可以用于对象的属性名,保证不会出现同名的属性,这对于一个对象由多个模块构成的情况非常有用,能防止某一个键被不小心改写或覆盖。 对象的属性名可以有两种类型,一种是原来的字符串,另一种是新增的Symbol类型。凡是属性名属于Symbol类型,就都是独一无二的,可以保证不会与其他属性名产生冲突。 通过方括号结构和Object.defineProperty,将对象的属性名指定为一个Symbol值。 方法一: [javascript] view plain copy 方法二: [javascript] view plain copy 方法三: [javascript] view plain copy 在对象的内部,使用Symbol值定义属性时,Symbol值必须放在方括号之中,如果不放在方括号中,该属性名就是字符串,而不是代表的Symbol值。 [javascript] view plain copy Symbol值作为对象属性名时,不能用点运算符。由于点运算符后面总是字符串,所以不会读取name作为标识名所指代的那个值,导致属性名实际上是一个字符串,而不是一个Symbol值。 [javascript] view plain copy 3、作为对象函数名的Symbol [javascript] view plain copy 4、获取对象属性的两种方法 1) Object.getOwnPropertySymbols()方法 返回只包含Symbol类型的属性名的数组 2) Object.getOwnPropertyNames()方法 返回只包含字符串类型的属性名的数组 [javascript] view plain copy 5、Symbol.for()和Symbol.keyFor()方法 1) Symbol.for()方法 类似于单例模式,首先在全局中搜索有没有以该参数为名称的Symbol值,如果有则返回该Symbol值,否则新建并返回一个以该参数为名称的Symbol值。 [javascript] view plain copy 2) Symbol.keyFor()方法 返回一个已创建的Symbol类型值的key,实质是检测该Symbol是否已创建。 [javascript] view plain copy 版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhouziyu2011/arti 数据结构中的基础排序算法包括冒泡,选择和插入排序,它们的核心思想都是对一组数据按照一定的顺序重新排列,排列时用到的主要是一组嵌套的for循环,其中外循环遍历数组的每一项,内循环则用于比较元素。以下将按照升序排列为例。 1.冒泡排序 冒泡排序时数组的数据会像气泡一样从数组的一段漂浮到另一端,因此才有了冒泡这个命名。基本步骤如下: 1.依次两两比较相邻的元素,如果第一个比第二个大,则进行交换。 2.经过第一轮比较之后,最大的数已经出现在数组最后一个位置了。 3.然后再对除了最后一个元素外的所有数都重复一遍上述比较,结束后第二个的数会到达数组倒数第二个位置。 4.再依次对剩下的数进行重复,直到排序完毕。 下面看看代码描述: function bubbleSort(arr){ for(var i=0; i<arr.length; i++){ for(var j=0; j<arr.length-i; j++){ //当第一个数大于第二个时,交换它们 if(arr[j]>arr[j+1]){ var temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } } } } //测试 var testArr = [35,22,1,56,88,25]; bubbleSort(testArr); alert(testArr); //输出1,22,25,35,56,88 2.选择排序 步骤如下: 1.从数组的开头起,将第一个元素和其他所有元素都进行一次比较,选择出最小的元素放在数组的第一个位置。 2.然后再从第二个元素开始,将第二个元素和除第一个之外的所有元素进行一次比较,选择出最小的元素放在数组的第二个位置。 3.对后面的第三,第四……的元素分别重复上面的步骤,知道所有的数据完成排序。 代码描述如下: function selectSort(arr){ var minIndex;//定义minIndex变量用于存储每一趟比较时的最小数的下标 for(var i=0; i<arr.length; i++){ minIndex = i; for(var j=i+1; j<arr.length; j++){ if(arr[minIndex]>arr[j]){ minIndex = j; } } //每轮比较后若arr[i]不是我们需要的最小那个数,则进行交换 if(minIndex!=i){ var temp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = temp; } } } //测试 var testArr = [35,22,1,56,88,25]; selectSort(testArr); alert(testArr); //输出1,22,25,35,56,88 3.插入排序 插入排序的思想非常简单,主要如下: 步骤: 1.首先将数组第1个数看成是一个有序序列。 2.将数组的第2个数按照关键字大小插入到这个有序序列中,插入后得到了一包含两个数的有序序列。 3.接下来再重复上面的步骤将第3,第4……第n-1个数分别插入到该有序序列中,最终得到一个包含n个数的有序序列。 代码描述: function insertSort(arr){ var temp; //temp变量用于临时存储待插入元素 for(var i=1; i<arr.length; i++){ temp = arr[i]; //从前往后查找插入位置 for(var j=i; j>0&&arr[j-1]>temp; j--){ arr[j]=arr[j-1]; //将大于temp的arr[j]元素后移 } arr[j]=temp; } } //测试 var testArr = [35,22,1,56,88,25]; insertSort(testArr); alert(testArr); //输出1,22,25,35,56,88 现在如果要在页面中使用video标签,需要考虑三种情况,支持Ogg Theora或者VP8(如果这玩意儿没出事的话)的(Opera、Mozilla、Chrome),支持H.264的(Safari、IE 9、Chrome),都不支持的(IE6、7、8)。好吧,现在让我们从技术层面来认识HTML 5的视频,包括video标签的使用,视频对象可以用到的媒介属性和方法,以及媒介事件。 Video标签的使用 Video标签含有src、poster、preload、autoplay、loop、controls、width、height等几个属性, 以及一个内部使用的标签 (1) src属性和poster属性 你能想象src属性是用来干啥的。跟 (2) preload属性 这个属性也能通过名字了解用处,此属性用于定义视频是否预加载。属性有三个可选择的值:none、metadata、auto。如果不使用此属性,默认为auto。 None:不进行预加载。使用此属性值,可能是页面制作者认为用户不期望此视频,或者减少HTTP请求。 Metadata:部分预加载。使用此属性值,代表页面制作者认为用户不期望此视频,但为用户提供一些元数据(包括尺寸,第一帧,曲目列表,持续时间等等)。 Auto:全部预加载。 (3) autoplay属性 又是一个看名字知道用处的属性。Autoplay属性用于设置视频是否自动播放,是一个布尔属性。当出现时,表示自动播放,去掉是表示不自动播放。 注意,HTML中布尔属性的值不是true和false。正确的用法是,在标签中使用此属性表示true,此时属性要么没有值,要么其值恒等于他的名字 (此处,自动播放为或者);而在标签中不使用此属性表示false(此处不进行自动播放为)。 (4) loop属性 一目了然,loop属性用于指定视频是否循环播放,同样是一个布尔属性。 (5) controls属性 Controls属性用于向浏览器指明页面制作者没有使用脚本生成播放控制器,需要浏览器启用本身的播放控制栏。 控制栏须包括播放暂停控制,播放进度控制,音量控制等等。 每个浏览器默认的播放控制栏在界面上不一样。由于我浏览器的诡异问题,Firefox和Safari的Video标签不正常,所以这两个只能在网上找截图了。 (6) width属性和height属性 属于标签的通用属性了,这个不用多说。 (7) source标签 Source标签用于给媒体(因为audio标签同样可以包含此标签,所以这儿用媒体,而不是视频)指定多个可选择的(浏览器最终只能选一个)文件地址,且只能在媒体标签没有使用src属性时使用。 浏览器按source标签的顺序检测标签指定的视频是否能够播放(可能是视频格式不支持,视频不存在等等),如果不能播放,换下一个。此方法多用于兼容不同的浏览器。Source标签本身不代表任何含义,不能单独出现。 此标签包含src、type、media三个属性。 src属性:用于指定媒体的地址,和video标签的一样。 Type属性:用于说明src属性指定媒体的类型,帮助浏览器在获取媒体前判断是否支持此类别的媒体格式。 Media属性:用于说明媒体在何种媒介中使用,不设置时默认值为all,表示支持所有媒介。你想到
事件委托
例如,你有一个很多行的大表格,在每个上绑定点击事件是个非常危险的想法,因为性能是个大问题。流行的做法是使用事件委托。
事件委托描述的是将事件绑定在容器元素上,然后通过判断点击的target子元素的类型来触发相应的事件。
事件委托依赖于事件冒泡,如果事件冒泡到table之前被禁用的话,那以下代码就无法工作了。
myTable.onclick = function () {
e = e || window.event;
var targetNode = e.target || e.srcElement;
// 测试如果点击的是TR就触发
if (targetNode.nodeName.toLowerCase() === 'tr') {
alert('You clicked a table row!');
}
}
事件(Event)知识整理(二)
事件流
DOM同时支持两种事件模型:捕获型事件和冒泡型事件
并且每当某一事件发生时,都会经过捕获阶段->处理阶段->冒泡阶段(有些浏览器不支持捕获)
捕获阶段是由上层元素到下层元素的顺序依次。而冒泡阶段则正相反。
如下图 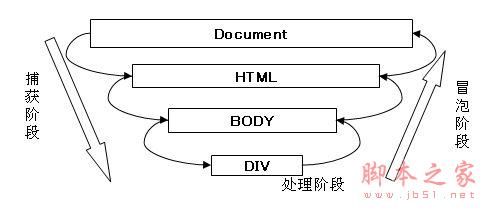
当事件触发时body会先得到有事件发生的信息,然后依次往下传递,直到到达最详细的元素。这就是事件捕获阶段。
还记得事件注册方法ele.addEventListener(type,handler,flag)吧,Flag是一个Boolean值,true表示事件捕捉阶段执行,false表示事件冒泡阶段执行。
接着就是事件冒泡阶段。从下往上 依次执行事件处理函数(当然前提是当前元素为该事件注册了事件句柄)。
在这个过程中,可以阻止事件的冒泡,即停止向上的传递。
阻止冒泡有时是很有必要的,例如
本意是如果点击div中按钮以外的位置时执行funcA,点击button时执行funcB。但是实际点击button时就会先后执行funcB,funcA。
而如果在button的事件句柄中阻止冒泡的话,div就不会执行事件句柄了。组合构造
先简单介绍在JS中创建对象的方式有如下几种:
这种模式就是抽象了创建具体对象的过程,也是最基本的一种设计模式,就像下面这样咯:
2. 构造函数模式
我们创建的每个函数都 一个prototype属性,这个属性是一个指针,指向一个对象(原型对象),使用原型对象的好处是不必在构造函数中定义对象实例的信息,而是可以将这些信息直接添加到原型对象中。就像下面这样:
所谓的原型的动态性,即随时可以为原型添加属性和方法,并且修改能够立即在所有对象实例中反映出来,像下面这样:
怎么组合呢,其实就是用构造函数模式定义实例属性(不会被共享),而用原型模式用于定义方法和共享的属性,另外这种组合模式还支持向构造函数传递参数,像下面这样:判断数组类型
2、每个页面的Array原生对象所引用的地址是不一样的,在子页面声明的array,所对应的构造函数,是子页面的Array对象;父页面来进行判断,使用的Array并不等于子页面的Array;切记,不然很难跟踪问题!
怎么区分数组和对象
判断一个变量类型是数组还是对象
var arr = [1, 2, 3]; var obj = { name: 'lyl', age: 18, 1: 'name' } console.log(arr instanceof Array); //true console.log(obj instanceof Array); //false var arr = [1, 2, 3]; var obj = { name: 'lyl', age: 18, 1: 'name' } console.log(arr.constructor === Array); //true console.log(obj.constructor === Array); //false var arr = [1, 2, 3]; var obj = { name: 'lyl', age: 18, 1: 'name' } console.log(Object.prototype.toString.call(arr) === '[object Array]'); //true console.log(Object.prototype.toString.call(boj) === '[object Array]'); //false var arr = [1, 2, 3]; var obj = { name: 'lyl', age: 18, 1: 'name' }
console.log(arr.sort === Array.prototype.sort); //true console.log(obj.sort === Array.prototype.sort); //false1、objectName instanceof Array
2、objectName.constructor == Array
(123).constructor == Number // true
a)在不同 iframe 中创建的 Array 并不共享 prototype
b)即使为true,也有可能不是数组。
function SubArray(){
}
SubArray.prototype = [];
myArray = new SubArray;
alert(myArray instanceof Array)3、特性判断
b)splice
c)length不可枚举 function isArray(object){ return object && typeof object==='object' && typeof object.length==='number' && typeof object.splice==='function' && //判断length属性是否是可枚举的 对于数组 将得到false !(object.propertyIsEnumerable('length'));}4、Array.isArray(objectName);
5、Object.prototype.toString.call(objectName)
Object.prototype.toString.call(objectName) === ‘[object Array]‘;Js数据类型
js的基本数据类型有哪些?
ECMAScript中有5中简单数据类型(也称为基本数据类型): Undefined、Null、Boolean、Number和String。还有1中复杂的数据类型————Object,Object本质上是由一组无序的名值对组成的。Undefined、Null、Boolean、Number都属于基本类型。Object、Array和Function则属于引用类型,String有些特殊,具体的会在下面展开分析。ECMAScript中用var关键字来定义变量,因为js是弱类型的,所以无法确定变量一定会存储什么值,也就不知道变量到底会是什么类型,而且变量的类型可以随时改变。ECMAScript是松散类型的来由,所谓松散类型就是可以用来保存任何类型的数据。es6中新增了let命令来声明变量、const命令声明一个只读的常量。let的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效。const一旦声明,常量的值就不能改变。let、const这里不做展开讨论,可以参考 阮一峰 - ECMAScript 6 入门js中的变量是松散类型的,所以它提供了一种检测当前变量的数据类型的方法,也就是typeof关键字.
通过typeof关键字,对这5种数据类型会返回下面的值(以字符串形式显示)undefined ---------- 如果值未定义 Undefinedboolean ---------- 如果这个值是布尔值 Booleanstring ---------- 如果这个值是字符串 Stringnumber ---------- 如果这个值是数值类型 Numberobject ---------- 如果这个值是对象或null Objecttypeof null返回为object,因为特殊值null被认为是一个空的对象引用。Undefined类型只有一个值,即特殊的undefined。在使用var声明变量但未对其加以初始化时,这个变量的值就是undefined。不过,一般建议尽量给变量初始化,但是在早期的js版本中是没有规定undefined这个值的,所以在有些框架中为了兼容旧版浏览器,会给window对象添加undefined值。window
['undefined'] = window['undefined']; //或者window
.undefined = window.undefined; Null类型是第二个只有一个值的数据类型,这个特殊的值是null。从逻辑角度来看,null值表示一个空对象指针,而这也正是使用typeof操作符检测null时会返回object的原因。 var car = null; console.log(typeof car); // "object"null而不是其他值。这样一来,只要直接检测null值就可以知道相应的变量是否已经保存了一个对象的引用了。
例如: if(car != null){ //对car对象执行某些操作 }console
.log(undefined == null); //true var message = 'Hello World'; var messageAsBoolean = Boolean(message);
var message = 'Hello World'; if(message) { alert("Value is true"); }
!!一般用来将后面的表达式强制转换为布尔类型的数据(boolean),也就是只能是true或者false;var
foo; alert
(!foo);//undifined情况下,一个感叹号返回的是true; alert
(!goo);//null情况下,一个感叹号返回的也是true; var
o={flag:true}; var
test=!!o.flag;//等效于var test=o.flag||false; alert
(test);alert
(NaN == NaN); //falsevar
name = String("jwy");alert
(typeof name);//"string"var
x=new String('12345')typeof
x //objectx='12345'typeof
x //stringvar
author = "Tom";alert
(typeof name);//"string"Es6 symbol
编码实现插入排序
Html5视频是哪个标签 video
标签的一样,这个属性用于指定视频的地址。而poster属性用于指定一张图片,在当前视频数据无效时显示(预览图)。视频数据无效可能是视频正在加载,可能是视频地址错误等等。