MySQL必知必会——用正则表达式进行搜索
一、正则表达式
1、正则表达式介绍
前例博客中的过滤例子允许用匹配、比较和通配操作符寻找数据。对于基本的过滤,这样就足够了。但是随着过滤条件的复杂性的增加,WHERE子句本身的复杂性也有必要增加。
这也就是正则表达式变得有用的地方,正则表达式(Regular Expression)是用来匹配文本的特殊的串(字符集合)。如果你想从一个文本文件中提取电话号码,可以使用正则表达式。如果想替换一个页面中的所有URL为这些URL的实际HTML链接,也可以使用一个正则表达式。所有程序设计类的语言、文本编辑器、操作系统等都支持正则表达式。
正则表达式用正则表达式语言来建立,正则表达式语言是用来完成刚讨论的所有工作以及更多工作的一种特殊语言。与任意语言一样 ,正则表达式具有你必须学习的特殊语法和指令。
2、使用MySQL正则表达式
那么,正则表达式和MySQL有什么关系呢?已经说过,正则表达式的作用是匹配文本,将一个模式与一个文本串进行比较。MySQL用WHERE子句对正则表达式提供了初步的支持,允许你指定正则表达式过滤SELECT检索出的数据。
2.1基本字符匹配
我们从一个简单的例子开始,下面的语句检索列prod_name包含文本1000的所有行。
MariaDB [course]> SELECT prod_name,prod_id
-> FROM products
-> WHERE prod_name REGEXP '1000'
-> ORDER BY prod_name;
+--------------+---------+
| prod_name | prod_id |
+--------------+---------+
| JetPack 1000 | JP1000 |
+--------------+---------+
1 row in set (0.00 sec)
这条语句除了关键字LIKE被REGEXP替代外,看上去非常像使用LIKE的语句。它告诉MySQL:REGEXP后跟的东西作为正则表达式处理。
在上面的例子中,正则表达式或许没有带来太多好处,可能还会降低性能,但请参考下面的例子:
MariaDB [course]> SELECT prod_name,prod_id
-> FROM products
-> WHERE prod_name REGEXP '.000'
-> ORDER BY prod_name;
+--------------+---------+
| prod_name | prod_id |
+--------------+---------+
| JetPack 1000 | JP1000 |
| JetPack 2000 | JP2000 |
+--------------+---------+
2 rows in set (0.00 sec)
这里使用了正则表达式'.000'。.是正则表达式语言中一个特殊的字符.。它表示匹配任意一个字符,因此1000和2000都匹配且返回。
LIKE与REGEXP的区别:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name LIKE '1000'
-> ORDER BY prod_name;
Empty set (0.00 sec)
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '1000'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
+--------------+
1 row in set (0.01 sec)
上述例子发现第一条语句不返回数据,而第二条语句返回一行。为什么呢?
正如之前讲通配符时所说,LIKE匹配整个列。如果被匹配的文本在列值中出现(被匹配文本'1000',列值'JetPack 1000' ),LIKE将不会找到它,相应的行也不被返回(除非使用通配符)。而REGEXP在列指内进行匹配,如果被匹配的文本在一个列值中出现,REGEXP将会匹配到它,相应的行将会被返回。这是一个很重要的差别。
那么,REGEXP能否匹配整个列值呢(从而和LIKE起到相同的作用),答案是肯定的,使用定位符^和$即可。
匹配不区分大小写:MySQL中的正则表达式匹配(自从3.23.4版本之后)不区分大小写(即大写和小写都匹配)。为区分大小写,可使用
BINARY关键字,如WHERE prod_name REGEXP BINARY 'Jetpack .000'
2.2进行OR匹配
为搜索两个串之一,或者为这个串,或者为另一个串。使用|,如下所示:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '1000|2000'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
语句中使用了正则表达式1000|2000。
|为正则表达式的OR操作符。它表示匹配其中之一,因此1000和2000都匹配并返回。
使用|从功能上类似于在SELECT语句中使用OR语句,多个OR条件可并入单个正则表达式。
两个以上的OR条件,例如
'1000|2000|3000'将匹配1000或2000或3000
2.3匹配几个字符之一
匹配任何单一字符,但是,如果你只想匹配特定的字符,怎么办?
可以通过指定一组用[] 括起来的字符来完成,如下所示:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[123] Ton'
-> ORDER BY prod_name;
+-------------+
| prod_name |
+-------------+
| 1 ton anvil |
| 2 ton anvil |
+-------------+
2 rows in set (0.00 sec)
这里使用了正则表达式[123]Ton。[123]定义一组字符,它的意思是匹配1或2或3 。
因此,1ton和2ton都匹配且返回。
正如所见,[]是另一种形式的OR语句。事实上,正则表达式[123]Ton是[]1|2|3]Ton的缩写,也可以使用后者。但是,需要用[]来定义OR语句查找什么 。具体请看下例:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '1|2|3 Ton'
-> ORDER BY prod_name;
+---------------+
| prod_name |
+---------------+
| 1 ton anvil |
| 2 ton anvil |
| JetPack 1000 |
| JetPack 2000 |
| TNT (1 stick) |
+---------------+
5 rows in set (0.00 sec)
这并不是希望的输出,两个要求的行被检索出来,但还检索出了另外3行。之所以这样是由于MySQL理解你的意思为’1’或’2’或’3 ton’。除非把字符|括在一个集合中,否则它将应用于整个串。
字符串也可以被否定,它们将匹配除指定字符外的任何东西。为了否定一个字符集,在集合的开始处放置一个^即可。所以[^123]匹配除了这些字符之外的任何内容。
2.4匹配范围
集合可以用来定义要匹配的一个或者多个字符。
例如 ,下面集合将匹配数字0到 9 [0123456789]
为了简化这种类型的集合,可以使用-来定义一个范围。下面的式子功能等同于上面的数字列表[0-9]
范围不限于完整的集合,[1-3]和[6-9]也是合法的范围,此外,范围也不一定是数值的,也可以是字母的。
[a-z]就代表匹配任意字符 。
举例:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[1-5] Ton'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+--------------+
3 rows in set (0.00 sec)
这里使用正则表达式[1-5] Ton,[1-5]定义了一个范围,这个表达式意思是匹配1到5,因此返回3个匹配行,由于5 Ton匹配,所以返回.5 Ton
2.5匹配特殊字符
正则表达式语言由具有特定含义的特殊字符构成,已经学习了. [] | -等,还有其他一些字符串。
如果要匹配这些字符的话,应该怎么办?
假如,要找出包含.字符的值,该如何搜索。请看下例:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '.'
-> ORDER BY prod_name;
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Bird seed |
| Carrots |
| Detonator |
| Fuses |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| Sling |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
14 rows in set (0.00 sec)
这并不是期望的输出,.匹配任意字符。因此每行都被检索出来。
为了匹配特殊字符,必须用\\为前导。\\-表示查找-,\\.表示查找.
修改上例为
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '\\.'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
+--------------+
1 row in set (0.00 sec)
这才是期望的输出,这种处理就是所谓的**转义(escaping)。*,正则表达式内具有特殊含义的所有字符都必须以这种方式转义。
\\也可以用来引用元字符(具有特殊意思的字符),如下表所示:
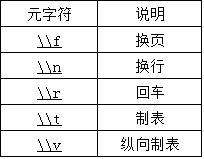
为了匹配反斜杠字符本身,需要使用\\\
2.6匹配字符类
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字符等的匹配。为了更方便工作,可以使用预定义的字符集,称为字符类(character class)。
下表列出字符类以及它们的含义
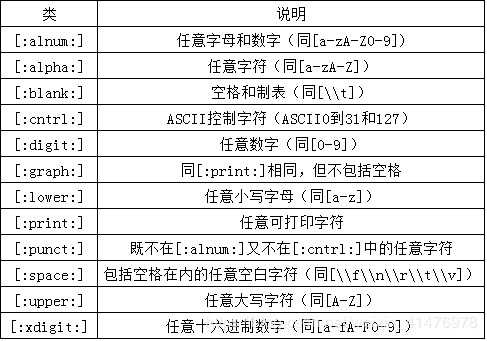
2.7匹配多个实例
目前为止使用的所有正则表达式都试图匹配单次出现,如果存在一个匹配,该行被检索出来,如果不存在,检索不出任何行,但有时需要对匹配的数目进行更强的控制。例如,你可能需要寻找所有的数,不管数中包含多少数字,或者你可能想寻找一个单词并且能够适应一个尾随的s。
可以用下表列出的正则表达式重复元字符来完成。
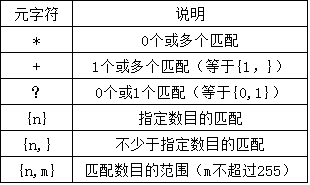
看这个例子:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '\\([0-9] sticks?\\)'
-> ORDER BY prod_name;
+----------------+
| prod_name |
+----------------+
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
2 rows in set (0.00 sec)
解析:正则表达式\\([0-9] sticks?\\),分开来看\\(匹配(,[0-9]匹配任意数字,sticks?匹配stick和sticks 。(s后的?使s成为可选的,因为?匹配它前面的任何字符的0次或1次出现)。\\)匹配)。
以下是另一个例子,这次我们打算匹配连在一起的4位数字:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[[:digit:]]{4}'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
分析:[[:digit:]]表示数字,因而它为数字的一个集合。{4}确切地要求它前面地字符(任意数字)出现4次,所以[[:digit:]]{4}匹配连在一起的任意4位数字。
需要注意的是,编写正则表达式的时候,某个特殊的表达式几乎不止一种写法,上面的例子也可以写成下面的语句:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[0-9][0-9][0-9][0-9]'
-> ORDER BY prod_name;
2.8定位符
目前为止所有的例子都是匹配一个串的任意位置的文本,为了匹配特定位置的文本,需要使用下面列出的定位符。

例如 ,如果你想找出一个数(包括以小数点开始的数)开头的所有产品,简单搜索[0-9\\.]或者[[:digit:]\\.]是不行的,因为它将在文本内任意位置进行匹配。解决办法是使用定位符^,如下:
MariaDB [course]> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '^[0-9\\.]'
-> ORDER BY pord_name;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+--------------+
3 rows in set (0.00 sec)
简单的正则表达式的测试:
可以在不使用数据库表的情况下用SELECT来测试正则表达式。REGEXP检查总是返回0(没有匹配)或1(匹配)。用带文字串的REGEXP来测试表达式,并试验它们。相应的语法如下:
SELCT 'hello' REGEXP '[0-9]';
+------------------------+
| 'hello' REGEXP '[0-9]' |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
这个例子返回值为0,因为文本hello中没有数字。