【机器学习案例四】基于心电图的心脏病诊断(分类)
基于心电图的心脏病诊断
- 案例背景
- 数据预处理
- 决策树
- 要求
- 模型参数
- 格子搜索确定最优参数
- 用最优参数训练模型
- 利用产生的决策树确定属性重要性
- AdaBoost、随机森林、 GBDT、xgboost、lightGBM
- 要求
- 代码
- 神经网络模型
- 要求
- 模型(200,200)
- 模型参数(50,40,20)
案例背景
数据集 mitbih_train 中给出了心电图数据,其中每一行表示采集到一个人的心电图片段,并且将其转化为 187 个属性特征(记为 x1,x2,…x187),每一行最后一列给出了分类标签(记为 y),其中 0 表示健康病人,1~4 分别对应着存在四种类型心脏异常的病人。请根据要求建立分类模型,并将建立的模型在数据集 mitbih_test 中进行测试。
数据预处理
- 导入库
import numpy as np
import pandas as pd
import os
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
- 读取数据
train=pd.read_csv('mitbih_train.csv',header=None)
test=pd.read_csv('mitbih_test.csv',header=None)
cols=['x' + str(i+1) for i in range(187)]
cols.append('y')
train.columns=cols
test.columns=cols
- 处理训练集和测试集
train_x=train.drop('y',axis=1)
test_x=test.drop('y',axis=1)
train_y=train['y']
test_y=test['y']
决策树
要求
请建立决策树模型并进行调优,分别评价模型在训练集和测试集的预测效果;利用产生的决策树确定属性重要性。
模型参数
DecisionTreeClassifier().get_params()
{‘class_weight’: None,
‘criterion’: ‘gini’,
‘max_depth’: None,
‘max_features’: None,
‘max_leaf_nodes’: None,
‘min_impurity_decrease’: 0.0,
‘min_impurity_split’: None,
‘min_samples_leaf’: 1,
‘min_samples_split’: 2,
‘min_weight_fraction_leaf’: 0.0,
‘presort’: False,
‘random_state’: None,
‘splitter’: ‘best’}
格子搜索确定最优参数
tree=DecisionTreeClassifier()
parameters={'max_depth':np.arange(5,20,1)}
tree_grid=GridSearchCV(tree,parameters,cv=5)
tree_grid.fit(train_x,train_y)
print(tree_grid.best_params_)
print(tree_grid.best_score_)
best_params_:{‘max_depth’: 17}
best_score:0.96
用最优参数训练模型
tree=DecisionTreeClassifier(max_depth=17)
tree.fit(train_x,train_y)
tree.score(train_x,train_y)
tree.score(test_x,test_y)
训练精度:0.9846
测试精度:0.9605
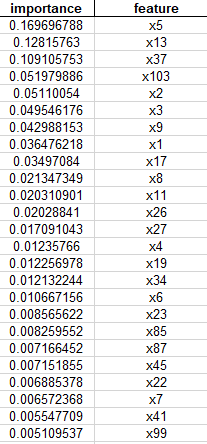
利用产生的决策树确定属性重要性
stat=pd.DataFrame(columns=['importance','feature'])
stat['importance']=tree.feature_importances_
stat['feature']=train_x.columns
stat.sort_values(by='importance',ascending=False,inplace=True)
stat.to_excel('eample4.xls',index=False)
AdaBoost、随机森林、 GBDT、xgboost、lightGBM
要求
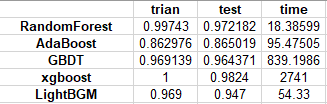
分别建立 AdaBoost、随机森林以、 GBDT 、xgboost 和lightGBM 对训练集数据进行训练,分别评价模型在训练集和测试集的预测效果并计算算法的执行时间。
代码
- 导入库
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
import lightgbm as lgb
from xgboost import XGBClassifier
- 构建模型
rf=RandomForestClassifier()
ada=AdaBoostClassifier()
gbdt=GradientBoostingClassifier()
mdl_lgb=lgb.LGBMClassifier(num_leaves=127,n_estimators=200,max_depth=6,learning_rate=0.3,reg_alpha=0.05)
mdl_xgb=XGBClassifier(n_estimators=200,max_depth=6,learning_rate=0.3)
- 训练模型
model_strlist=['RandomForest','AdaBoost','GBDT',‘XGboost’,‘,'lightGBM ’]
train_=[]
test_=[]
time_=[]
for num,model in enumerate([rf,ada,gbdt,mdl_xgb,mdl_lgb]):
a=time.time()
model.fit(train_x,train_y)
train_acc=model.score(train_x,train_y)
test_acc=model.score(test_x,test_y)
b=time.time()-a
print("{} train/test accuracies : {}/{} time: {} ".format(model_strlist[num],str(train_acc)[:5],str(test_acc)[:5],b))
train_.append(train_acc)
test_.append(test_acc)
time_.append(b)
- 保存结果
stat={}
stat['trian']=train_
stat['test']=test_
stat['time']=time_
stat=pd.DataFrame(stat,index=['RandomForest','AdaBoost','GBDT'])
stat.to_excel('example4-2.xls')
在训练集和测试集上表现最好的是xgboost,但是用的时间是最长的,是时长排名第二为的GBDT的三倍还多,模型的训练成本较高。用是最短的是随机深林,仅用了18秒,而且训练效果也很好,训练效果在五个模型中排名第二位。
神经网络模型
要求
分别建立具有两个隐藏层和三个隐藏层的神经网络模型,要求使二者的参数规模接近并且激活函数、损失函数以及最优化算法设定方面均相同,在对训练集数据进行训练的基础上分别评价模型在训练集和测试集的预测效果。
模型(200,200)
from sklearn import neural_network as nn
from sklearn.metrics import accuracy_score
a=time.time()
mdl_nn=nn.MLPClassifier(solver='adam',
momentum=0.9, #solver为sgd时使用
activation='relu',
learning_rate_init=0.001, #可选,默认0.001,初始学习率,控制更新权重的补偿,只有当solver=’sgd’ 或’adam’时使用
learning_rate='constant', #学习率的变化策略,根据loss的变化来调整
alpha=0.0001,
hidden_layer_sizes=(200,200)
verbose=True, #是否将过程打印
batch_size=20000, #更新一次网络结构的参数所需要的样本量
max_iter=200,
shuffle=True,
)
mdl_nn.fit(train_x,train_y)
yhat=mdl_nn.predict(train_x)
ypred=mdl_nn.predict(test_x)
print(accuracy_score(train_y,yhat))
print(accuracy_score(test_y,ypred))
print(time.time()-a)
训练集:0.9849
测试集:0.97629
模型参数(50,40,20)
a=time.time()
mdl_nn=nn.MLPClassifier(solver='adam',
momentum=0.9, #solver为sgd时使用
activation='relu',
learning_rate_init=0.001, #可选,默认0.001,初始学习率,控制更新权重的补偿,只有当solver=’sgd’ 或’adam’时使用
learning_rate='constant', #学习率的变化策略,根据loss的变化来调整
alpha=0.0001,
hidden_layer_sizes=(50,40,20)
verbose=True, #是否将过程打印
batch_size=20000, #更新一次网络结构的参数所需要的样本量
max_iter=200,
shuffle=True,
)
mdl_nn.fit(train_x,train_y)
yhat=mdl_nn.predict(train_x)
ypred=mdl_nn.predict(test_x)
print(accuracy_score(train_y,yhat))
print(accuracy_score(test_y,ypred))
print(time.time()-a)
训练集:0.9737
测试集:0.9693
在参数数量差不多的情况下,两层的神经网络在训练集和测试集上都优于三层的神经网络,但并不显著。